【爬虫入门01】我第一只由Reuests和BeautifulSoup4供养的Spider
【爬虫入门01】我第一只由Reuests和BeautifulSoup4供养的Spider
广东职业技术学院 欧浩源
1、引言
网络爬虫可以完成传统搜索引擎不能做的事情,利用爬虫程序在网络上取得数据,经过数据清洗和分析,使非结构化的数据转换成结构化的数据,其结果可以存储到数据库,也可以进行数据的可视化,还能根据分析数据的基础获得想要的结果。除了利用urllib.request和正则表达式或者利用Scrapy框架实现网络爬虫之外,利用Requests和BeautifulSoup4技术也可能很方便的实现网络爬虫。前者很多技术书籍和网络博文都有细述,后者目前的资料并不太多。
本文将以一个具体例子,详细介绍利用Requests和BeautifulSoup4技术开发网络爬虫的技术要点和实现步骤。
2、爬虫的功能需求
爬虫的目标:
将“内涵吧”里面的内涵段子从第1页开始,逐页将段子爬出来,并将其文本存储到E盘的duanzi.txt文件下。
爬虫的功能:
1、爬虫启动后,显示版本信息。
2、每按一下回车键,爬去一页段子并保存。
3、输入“exit”退出网络爬虫。
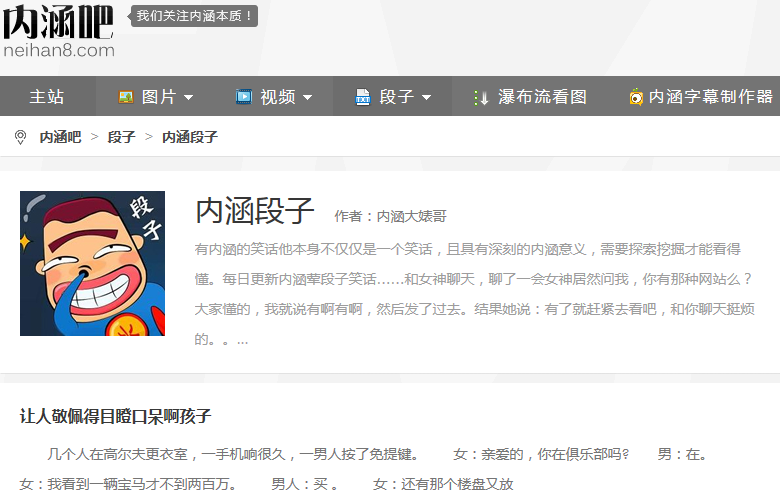
网址:http://www.neihan8.com/article/
3、爬虫程序的设计思路
首先使用Requests模块的get方法连接网页并获取网络资源,在这里需要爬取网页的URL。通过分析,发现“内涵吧”的网页URL中,处理第1页之外,其他每页都有规律可循。
即:res = requests.get(myurl)
接着利用BeautifulSoup模块使用lxml解析器将网络资源取出 放到变量中。
即:soup = BeautifulSoup(res,'lxml')
然后通过BeautifulSoup模块中的方法,过滤网络信息并将目标内容取出。
最后将目标内容存储到指定的文件中。
4、网络爬虫的基本功能
首先,用最简单的方法,实现将目标URL的内容爬取出来,如果这个步骤不能实现,后续的所有工作都是没有意义的。
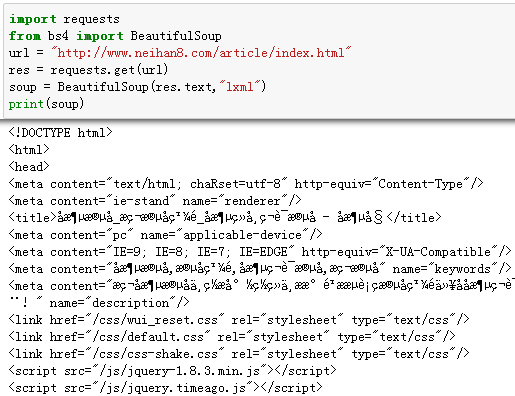
上面代码虽然只有区区几行,实际上,已经实现一个网络爬虫了。
从获得的网络信息来看,很多地方出现乱码。这个问题是编码的问题。在获取的内容中,可以看到这样的信息:chaRset=utf-8。
在读取网络信息之前,将其编码格式指定为utf-8即可。
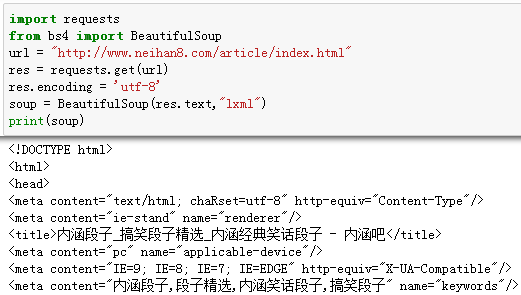
指定正确的编码方式后,获取的结果中没有乱码出现了。
到这里,是不是就完美结束了呢?
理论上可以,实际上还不行。现在很多网站对于非正常请求是拒绝访问的。所以,必须给爬虫穿上一个合法的外衣。最理想的做法是,将爬虫的访问模拟成浏览器的请求。
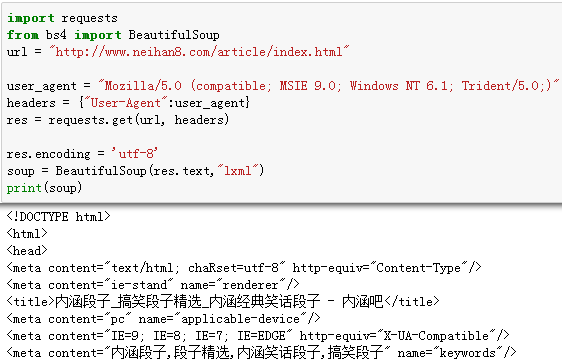
至此,一个完美的网络爬虫基本结构就出来了。
5、将目标内容过滤出来
通过对爬取到的网页信息分析,在漫漫的信息海洋中,发现目标段子内容在div标签中,并且class属性为desc。

因此,可以通过BeautifulSoup模块的faind_all()方法将其内容取出,其返回一个内容列表。
item_list = soup.find_all("div", {"class":"desc"})
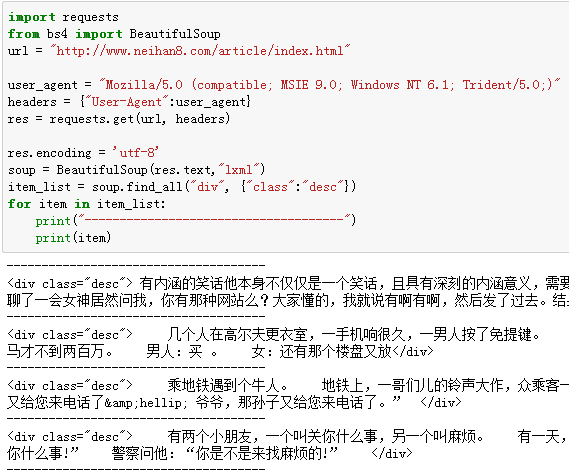
在返回的内容列表中,还有一部分标签的信息,这是我们不需要的,可以只读取文本内容,把这些无关的信息过滤掉:
print(item.text)
6、网络爬虫的基本框架
对网络爬虫的几个主要功能测试成功后,就可以开始构思的爬虫的基本框架了。
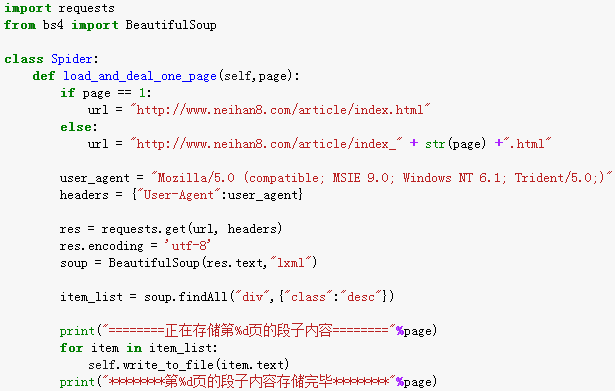
首先定义一个网络爬虫类Spider,在该类中实现一个装载网页内容的方法load_and_deal_page(self,page),将指定页的内容读出装载到指定的变量中,并通过BeautifulSoup模块将所需内容过滤出来。
再写一个将目标内容写入文件的方法write_to_file(self,text),将指定内容以追加的方式写入到固定的文件中。
接着实现一个控制程序流程的方法begin_to_work(self),实现按下回车键爬取下一页和输入“exit”退出网络爬虫的功能。
然后在类的__init__(self)方法中,实现基本信息的打印和相关变量的定义。
最后在main函数中,实现一个网络爬虫的对象实例,并启动。

7、网页装载及处理的方法
在网页装载的时候,需要获得该页面的URL地址。通过观察,除了“内涵吧”的首页地址之外,其他页面的URL均有规律可循。

因此,可以使用if语句对其做适当的处理。

该方法是本网络爬虫的核心代码,其实现可以如下:
8、将内容写入文件的方法
首先使用open方法以追加方式打开文件,接着用write方法就指定内容写入,最后用close方法关闭文件即可。

9、初始化与流程控制的方法
在初始化函数中,除了打印基本信息之外,还要定义两个变量,enable用于控制爬虫是否启动,page用于控制爬取的页面。

在流程控制的方法中,通过判断外部输入的信息,以实现网络爬虫的控制,如果收到回车键则爬取下一页网页信息,如果收到"exit"则退出网络爬虫。

10、main函数的实现
当所有的功能模块实现时候,main方法是最简单的事情了。在这里,实现一个Spider的对象实例,并启动网络爬虫。

11、网络爬虫的运行结果
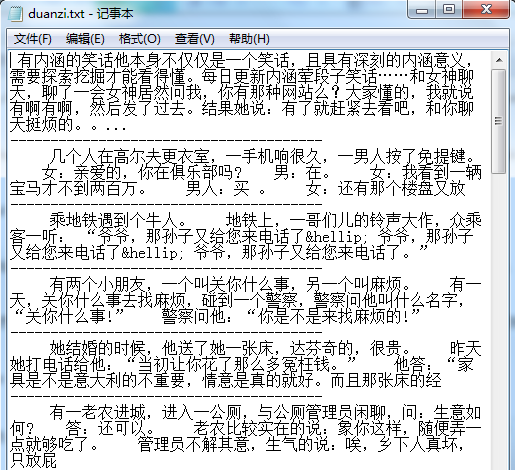
网络爬虫启动后,在控制端口可以看到运行的信息并可以控制程序的继续和退出。

打开指定写入的文件,可以看到从“内涵吧”爬去出来的段子内容。
12、小结
网络爬虫可以帮你收集和处理大量数据,让你可以一次查看几千甚至几万个网页,并通过数据分析获得目标结果。Python语言拥有强大的第三方库,从Requests和BeautifulSoup入手学习网络爬虫是一个非常不错的选择。
【爬虫入门01】我第一只由Reuests和BeautifulSoup4供养的Spider的更多相关文章
- 【网络爬虫入门01】应用Requests和BeautifulSoup联手打造的第一条网络爬虫
[网络爬虫入门01]应用Requests和BeautifulSoup联手打造的第一条网络爬虫 广东职业技术学院 欧浩源 2017-10-14 1.引言 在数据量爆发式增长的大数据时代,网络与用户的沟 ...
- python爬虫入门01:教你在 Chrome 浏览器轻松抓包
通过 python爬虫入门:什么是爬虫,怎么玩爬虫? 我们知道了什么是爬虫 也知道了爬虫的具体流程 那么在我们要对某个网站进行爬取的时候 要对其数据进行分析 就要知道应该怎么请求 就要知道获取的数据是 ...
- 爬虫入门——01
1. 引言 从今天开始系统的学习网络爬虫.写这篇博客的目的在于,一来记录下自己的学习过程:二来希望可以给像我一样不懂爬虫但又对爬虫十分感兴趣的人带来一些帮助. 昨天去图书馆找有关爬虫书 ...
- 【网络爬虫入门05】分布式文件存储数据库MongoDB的基本操作与爬虫应用
[网络爬虫入门05]分布式文件存储数据库MongoDB的基本操作与爬虫应用 广东职业技术学院 欧浩源 1.引言 网络爬虫往往需要将大量的数据存储到数据库中,常用的有MySQL.MongoDB和Red ...
- python爬虫入门02:教你通过 Fiddler 进行手机抓包
哟~哟~哟~ hi起来 everybody 今天要说说怎么在我们的手机抓包 通过 python爬虫入门01:教你在Chrome浏览器轻松抓包 我们知道了 HTTP 的请求方式 以及在 Chrome 中 ...
- 爬虫框架Scrapy的第一个爬虫示例入门教程
我们使用dmoz.org这个网站来作为小抓抓一展身手的对象. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目 ...
- 不用搭环境的10分钟AngularJS指令简易入门01(含例子)
不用搭环境的10分钟AngularJS指令简易入门01(含例子) `#不用搭环境系列AngularJS教程01,前端新手也可以轻松入坑~阅读本文大概需要10分钟~` AngularJS的指令是一大特色 ...
- 爬虫入门系列(二):优雅的HTTP库requests
在系列文章的第一篇中介绍了 HTTP 协议,Python 提供了很多模块来基于 HTTP 协议的网络编程,urllib.urllib2.urllib3.httplib.httplib2,都是和 HTT ...
- 【网络爬虫入门02】HTTP客户端库Requests的基本原理与基础应用
[网络爬虫入门02]HTTP客户端库Requests的基本原理与基础应用 广东职业技术学院 欧浩源 1.引言 实现网络爬虫的第一步就是要建立网络连接并向服务器或网页等网络资源发起请求.urllib是 ...
随机推荐
- 我的hibernate学习记录(二)
通过上一篇文章我的hibernate学习记录(一)基本上的入门了hibernate,但是,里面还有还多东西是通过迷迷糊糊的记忆,或者说copy直接弄进去的,所以这篇文章就需要对上篇的一些文件.对象进行 ...
- linux一周学习总结
对于linux,之前也完全没有接触过,完全零基础小白.来到马哥以后,进入学习也有一周时间 ,一周里老师带我们学习了很多指令,下面,我就自己的理解和老师讲授的内容对linux中的一些指令做一个简单的小总 ...
- 微信小程序简单入门理解
简单的小程序示例结构: (一):理解小程序结构app.js,app.json,app.wxss ①app.js,app.json是小程序结构必要的部分,app.wxss可选择 ②app.js用于创建小 ...
- 学号:201521123116 《java程序设计》第九周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常相关内容. 2. 书面作业 本次PTA作业题集异常 1.常用异常 题目5-1 1.1 截图你的提交结果(出现学号) 1.2 自己 ...
- Junit4学习(五)Junit4测试套件
一,背景 1,随着开发规模的深入和扩大,项目或越来越大,相应的我们的测试类也会越来越多:那么就带来一个问题,假如测试类很多,就需要多次运行,造成测试的成本增加:此时就可以使用junit批量运行测试类的 ...
- 基于图形检测API(shape detection API)的人脸检测
原文:https://paul.kinlan.me/face-detection/ 在 Google 开发者峰会中,谷歌成员 Miguel Casas-Sanchez 跟我说:"嘿 Paul ...
- npm run build生成路径问题
vue项目中可以使用npm run build 命令生成静态文件夹dist,开发者可以直接点击dist文件夹下面的index.html问价来访问自己的项目,但是用vue-cli生成的项目,当运行npm ...
- eclipse里index.jsp头部报错的原因和解决方法
index.jsp的头<%@这句报错的话,是因为没有引入Tomcat的原因.解决:A:Window---Preferences---server---RuntimeEnviroments--Ad ...
- RSA原理、ssl认证、Tomcat中配置数字证书以及网络传输数据中的密码学知识
情形一:接口的加.解密与加.验签 rsa不是只有加密解密,除此外还有加签和验签.之前一直误以为加密就是加签,解密就是验签.这是错误的! 正确的理解是: 数据传输的机密性:公钥加密私钥解密是密送,保 ...
- 鸟哥Linux学习笔记03
1, 在Linux中,默认情况下所有的系统上的账号都记录在/etc/passwd这个文件内,密码记录在/etc/shadow这个文件下,所有的组名都记录在/etc/group内,这三个文件可以说是Li ...