栈的存储结构的实现(C/C++实现)
存档
#include "iostream.h"
#include <stdlib.h>
#define max 20
typedef char elemtype;
#include "stack.h"
void main()
{
stack s;
char x;
cout<<"(1)初始化栈s\n";
initstack(s);
cout<<"(2)栈为"<<(stackempty(s)?"空":"非空")<<endl;
cout<<"(3)依次输入字母序列,以'#'结束"<<endl;
cin>>x;
while(x!='#')
{
push(s,x);
cin>>x;
}
cout<<"(4)栈为"<<(stackempty(s)?"空":"非空")<<endl;
cout<<"(5)栈长度stacklength(s):"<<stacklength(s)<<endl;
cout<<"(6a)栈顶元素gettop(s)为:"<<gettop(s)<<endl;
cout<<"(6b)栈顶元素gettop1(s,x)为:";
gettop1(s,x);
cout<<x<<endl;
cout<<"(7)从栈顶到栈底元素printstack(s):";
printstack(s);
cout<<"(8)出栈pop1(s,x)的元素为:";
pop1(s,x);
cout<<x<<endl;
cout<<"(9)出栈序列:";
while(!stackempty(s))
{
cout<<pop(s)<<" ";
}
cout<<endl;
cout<<"(10)栈为"<<(stackempty(s)?"空":"非空")<<endl;
cout<<"(11)依次进栈元素a,b,c\n";
push(s,'a');
push(s,'b');
push(s,'c');
cout<<"(12)从栈顶到栈底元素printstack(s):";
printstack(s);
cout<<"(13)清空栈clearstack(s)\n";
clearstack(s);
cout<<"(14)栈为"<<(stackempty(s)?"空":"非空")<<endl;
cout<<"(15)销毁栈"<<endl;
destorystack(s);
cout<<"(17)销毁栈后调用push(s,e)和printstack(s)"<<endl;
push(s,'e');
printstack(s);
}
struct stack
{
elemtype *base;//存栈元素
elemtype *top;//栈顶指定器
int stacksize;//栈的最大容量
};
void initstack(stack &s)
{
//构造一个空栈s
s.base=new elemtype[max];//malloc()分配存储空间
if(!s.base)
exit(-);//#define OVERFLOW -2
s.top=s.base;//空栈
s.stacksize=max;//栈的存储容量
}
void clearstack(stack &s)
{
//清除栈s,使成为空栈
s.top=s.base;//空栈栈顶指针和栈底指针相等
}
int stackempty(stack s)
{
//若栈s为空栈返回1,否则返回0
if(s.top==s.base)
return ;//空栈返回1,非空返回0
else
return ;
}
int stacklength(stack s)
{
//返回栈的长度
return s.top-s.base;
}
void push(stack &s,elemtype e)
{
//元素e进栈
if(!s.base)//栈不存在的处理
{
cout<<"栈不存在\n";
return;
}
if(s.top-s.base>s.stacksize)//栈满的处理
{
cout<<"栈已满!\n";
return;
}
*s.top=e;//元素e存进栈顶的位置
s.top++;//栈顶指针指向栈顶元素的下一个位置
}
elemtype pop(stack &s)
{
//栈s的栈顶元素出栈并返回
if(s.base==s.top)
{
cout<<"栈空,不能出栈\n";
exit(-);
}
else
{
s.top--;//栈顶指针减1,下次进栈,会覆盖当前位置的值,相当于删除
return *s.top;//返回栈顶元素的值
}
}
int pop1(stack &s,elemtype &e)
{
//栈s的栈顶元素出栈并返回
if(s.base==s.top)
{
cout<<"栈空,不能出栈\n";
return ;
}
else
{
s.top--;//栈顶指针减1,下次进栈,会覆盖当前位置的值,相当于删除
e=*s.top;
return ;//返回栈顶元素的值
}
}
elemtype gettop(stack s)
{
//取栈s的当前栈顶元素并返回
if(s.top==s.base)
{
cout<<"栈空,获取栈顶元素失败"<<endl;
exit(-);
}
else
return *(s.top-);//top指针-1的位置才是栈顶元素所在的位置
}
int gettop1(stack s,elemtype &e)
{
//取栈s的当前栈顶元素并返回
if(s.top==s.base)
{
cout<<"栈空,获取栈顶元素失败"<<endl;
return ;
}
else
e=*(s.top-);
return ;//top指针-1的位置才是栈顶元素所在的位置
}
void printstack(stack s)
{
//输出栈中所有元素,但不出栈,不做任何修改
int i;
for(i=s.top-s.base-;i>=;i--)//总共s.top-s.base个元素,下标范围就是[0...(s.top-s.base-1)]
cout<<s.base[i]<<" ";
cout<<endl;
}
void destorystack(stack &s)
{
//销毁栈
delete s.base;//销毁连续空间
s.base=NULL;//指针赋空
s.top=NULL;//指针赋空
s.stacksize=;//栈容量赋0
}
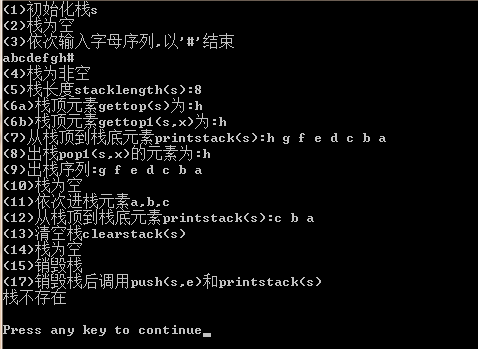
运行结果如下:
栈的存储结构的实现(C/C++实现)的更多相关文章
- C#创建安全的栈(Stack)存储结构
在C#中,用于存储的结构较多,如:DataTable,DataSet,List,Dictionary,Stack等结构,各种结构采用的存储的方式存在差异,效率也必然各有优缺点.现在介绍一种后进先出的数 ...
- 栈的存储结构和常见操作(c 语言实现)
俗话说得好,线性表(尤其是链表)是一切数据结构和算法的基础,很多复杂甚至是高级的数据结构和算法,细节处,除去数学和计算机程序基础的知识,大量的都在应用线性表. 一.栈 其实本质还是线性表:限定仅在表尾 ...
- C语言解释器的实现--存储结构(一)
目录: 1. 内存池 2. 栈 3. Hash表 1.内存池 在一些小的程序里,没什么必要添加内存管理模块在里面.但是对于比较复杂的代码,如果需要很多的内存操作,那么加入自己的内存管理是有必要的.至 ...
- C++编程练习(4)----“实现简单的栈的链式存储结构“
如果栈的使用过程中元素数目变化不可预测,有时很小,有时很大,则最好使用链栈:反之,如果它的变化在可控范围内,使用顺序栈会好一些. 简单的栈的链式存储结构代码如下: /*LinkStack.h*/ #i ...
- Java栈之链式栈存储结构实现
一.链栈 采用单链表来保存栈中所有元素,这种链式结构的栈称为链栈. 二.栈的链式存储结构实现 package com.ietree.basic.datastructure.stack; /** * 链 ...
- C#创建安全的字典(Dictionary)存储结构
在上面介绍过栈(Stack)的存储结构,接下来介绍另一种存储结构字典(Dictionary). 字典(Dictionary)里面的每一个元素都是一个键值对(由二个元素组成:键和值) 键必须是唯一的,而 ...
- 队列的存储结构和常见操作(c 语言实现)
一.队列(queue) 队列和栈一样,在实际程序的算法设计和计算机一些其他分支里,都有很多重要的应用,比如计算机操作系统对进程 or 作业的优先级调度算法,对离散事件的模拟算法,还有计算机主机和外部设 ...
- js数据结构与算法存储结构
数据结构(程序设计=数据结构+算法) 数据结构就是关系,没错,就是数据元素相互之间存在的一种或多种特定关系的集合. 传统上,我们把数据结构分为逻辑结构和物理结构. 逻辑结构:是指数据对象中数据元素之间 ...
- [置顶] ※数据结构※→☆线性表结构(queue)☆============优先队列 链式存储结构(queue priority list)(十二)
优先队列(priority queue) 普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除.在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有 ...
随机推荐
- php通过system()调用Linux命令问题
最近在做php和linux crontab的联调,发现php在linux下的权限问题需要引起注意,调试问题的过程中发现有许多问题前人说的比较零散,我在这里汇总,顺带抛砖引玉一下. 1.$result= ...
- http性能测试工具wrk源码学习之开篇
1.前言 最近工作需要测试nginx反向代理的性能,于是找了一些http测试工具,例如经典的Apache的ab.siege.wrk.wrk使用多线程事件驱动方式,支持lua脚本扩展.关于wrk介绍可以 ...
- Anaconda多版本Python管理
Anaconda是一个集成python及包管理的软件,记得最早使用时在2014年,那时候网上还没有什么资料,需要同时使用py2和py3的时候,当时的做法是同时安装Anaconda2和Anaconda3 ...
- Linux发行版 CentOS6.5 修改默认主机名
修改前准备 我们将主机名修改为comexchan.cnblogs.com(本文发布于http://comexchan.cnblogs.com/) 备份相关配置文件,以便回滚 cp /etc/sysco ...
- 【转】nginx提示:500 Internal Server Error错误的解决方法
本文转自:http://www.jb51.net/article/35675.htm 现在越来越多的站点开始用 Nginx ,("engine x") 是一个高性能的 HTTP 和 ...
- 【http转https】其之二:申请Let's Encrypt颁发SSL证书
文:铁乐猫 2017年1月12日 申请Let's Encrypt颁发SSL证书 由 ISRG(Internet Security Research Group,互联网安全研究小组)提供服务, ISRG ...
- thinkphp3.2.3的使用心得(零)
从模板传参到控制器 模板中代码: <volist name="list" id="vo"> <a href="__CONTROLLE ...
- SQL基础学习_03_数据更新
数据的插入 1. 基本INSERT语句 INSERT的基本语法为: INSERT INTO <表名> (列1, 列2, 列3, -) VALUES (值1, 值2, 值 ...
- C#面向插件级别的软件开发 - 开源研究系列文章
在现在的面向对象的分析与设计软件开发过程中,最开始就是面向对象的软件开发.但是,在实际的软件开发过程中,很多都是面向接口的开发方式,这种是一种面向对象开发的模式.但是,今天笔者给大家带来的是面向插件的 ...
- Java的静态代码块是否会在类被加载时自动执行?
JAVA静态代码块会在类被加载时自动执行? 一.先看Java静态方法,静态变量 http://www.cnblogs.com/winterfells/p/7906078.html 静态代码块 在类中, ...