Scrapy1.4爬取笑话网站数据,Python3.5+Django2.0构建笑话应用
Part1:需求简要描述
1、抓取http://www.jokeji.cn网站的笑话
2、以瀑布流方式显示
Part2:安装爬虫框架Scrapy1.4
1、 安装Scrapy1.4
E:\django\myProject001>pip install scrapy
执行报错:
error: Unable to find vcvarsall.bat
Failed building wheel for Twisted
2、安装wheel
E:\django\myProject001>pip install wheel
3、下载编译好的wheel文件
访问下面链接下载编译好的wheel文件到当前目录下
https://www.lfd.uci.edu/~gohlke/pythonlibs/
4、安装编译好的wheel文件
E:\django\myProject001>pip install Twisted-17.9.0-cp35-cp35m-win_amd64.whl
E:\django\myProject001>pip install Scrapy-1.4.0-py2.py3-none-any.whl
5、查看Scrapy是否安装成功
E:\django\myProject001>scrapy version
Scrapy 1.4.0
6、安装Py32Win模块
E:\django\myProject001>pip install pypiwin32
访问windows系统API的库
7、安装OpenPyXL
E:\django\myProject001>pip install openpyxl
用于将爬取数据写入Excel文件
Part3:创建项目及应用
1、创建项目及应用
E:\django>django-admin startproject myProject001
E:\django>cd myProject001
E:\django\myProject001>python3 manage.py startapp joke
2、修改settings.py
文件路径:myProject001\myProject001\settings.py
# 增加应用 INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'joke',
] # 修改amind管理后台语言 LANGUAGE_CODE = 'zh-hans'
TIME_ZONE = 'Asia/Shanghai'
3、修改modles.py
文件路径:myProject001\joke\models.py
from django.db import models class Jokes(models.Model):
jokeText = models.TextField(u'笑话内容')
createDate = models.DateField(u'创建日期', auto_now_add=True)
modifyDate = models.DateField(u'修改日期', auto_now=True)
4、创建数据迁移文件并执行
E:\django\myProject001>python3 manage.py makemigrations
E:\django\myProject001>python3 manage.py migrate
使用SQLite查看数据库,表创建成功
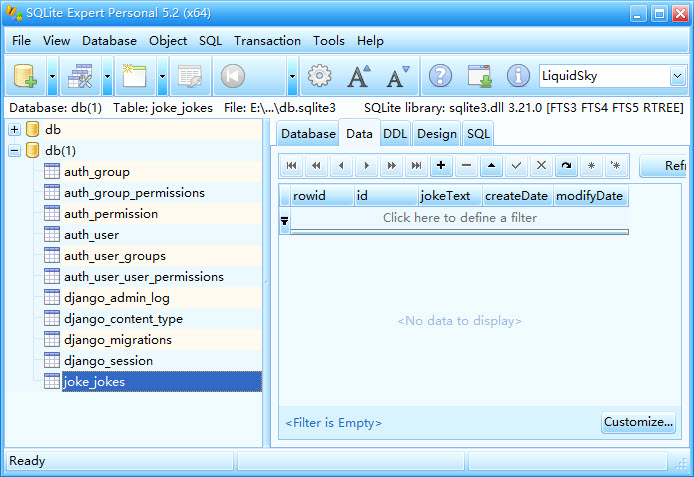
5、修改views.py
文件路径:myProject001\joke\views.py
from django.shortcuts import render
from django.http import HttpResponse def index(request):
return HttpResponse('这里是笑话应用的首页')
6、在joke应用下创建urls.py
文件路径:myProject001\joke\urls.py
from django.urls import path
from . import views urlpatterns = [
path('', views.index, name='index'),
]
7、修改项目应用下的urls.py
文件路径:myProject001\myProject001\urls.py
from django.contrib import admin
from django.urls import path,include urlpatterns = [
path('admin/', admin.site.urls),
path('joke/', include('joke.urls')),
]
8、创建应用首页模板文件index.html
模板文件路径:
myProject001\joke\templates\joke\index.html
模板文件内容:
<html>
<head>
<title>笑话应用的首页</title>
</head>
<body> </body>
</html>
9、启动应用
E:\django\myProject001>python3 manage.py runserver
访问如下地址,应用创建成功
http://127.0.0.1:8000/joke/

Part4:了解XPath一些基本知识
1、节点和属性
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=gb2312" />
<title>开心一刻</title>
<link rel="icon" href="/favicon.ico" type="image/x-icon" />
<link href="css/list.css" rel="stylesheet" type="text/css" />
</head>
<body>
<div class="style_top">
<div class="list_title">
<ul>
<li>
<a href="/jokehtml/bxnn/2017122722221351.htm"target="_blank" >醉人的笑容你会有</a>
</li>
<li>
<a href="/jokehtml/fq/201712272221462.htm"target="_blank" >搞笑夫妻乐事儿多</a>
</li>
<li>
<a href="/jokehtml/mj/2017122722205011.htm"target="_blank" >幽默密切联系生活</a>
<i>
</ul>
</div>
</div>
</body>
</html>
节点/元素:html、head、body、div、li 等
节点/元素文本内容:开心一刻、醉人的笑容你会有
属性:class、href 等
属性值:style_top、/jokehtml/bxnn/2017122722221351.htm 等
2、XPath使用路径表达式选取节点
| 表达式 | 描述 | 实例 |
| 节点名称 | 选取此节点的所有子节点 | body |
| / | 从根节点选取 | /html |
| // | 选择文档中的节点,而不考虑位置 | //li |
| . | 选取当前节点 | .//title |
| .. | 选取当前节点的父节点 | |
| @ | 选取属性 | //@href |
| 谓语 | 找某个特定的节点或者包含某个指定的值的节点 | //title[@lang='eng'] |
| * | 任意元素 | //* |
| @* | 任意属性 | //title[@*] |
| node() | 任意类型 | |
| | | 或运算符 | //title | //price |
| : | 命名空间 | my:* |
| text() | 文本内容 | /html/head/title/text() |
| response.xpath() | 返回选择器列表,使用xpath语法选择的节点 | response.xpath('//base/@href').extract() |
| response.css() | 返回选择器列表,使用css语法选择的节点 | response.css('base::attr(href)').extract() |
| response.extract() | 返回被选择元素的unicode字符串 | |
| response.re() | 返回通过正则表达式提取的unicode字符串列表 |
Part5:分析网页源代码确定抓取数据的逻辑
1、笑话内容页面源码分析
笑话内容所在的html代码
<span id="text110">
<P>1、为了省腮红钱,我每天出门给自己两个耳光。</P>
<P>2、不要把今天的工作拖到明天,明天还不是要做?还不如干脆点,今天就把工作辞了。 </P>
<P>3、朋友,你听我一句劝,钱没了可以再挣,所以我找你借的那笔钱就不还了吧。</P>
<P>4、正能量的东西也不能多看,就好比自己挺穷的,哪能天天看有钱人的生活?肯定越看越伤心。还不如多看点更丧的东西,显得自己元气尚存。</P>
<P>5、根据一个人的车,我们就能看出这个人是什么样的。比如:如果它在沟里,它就是女人的车。</P>
<P>6、以前小时候女鬼总喜欢在梦里吓我,现在长大了,懂事了,单身久了,女鬼都不敢出现了!</P>
<P>7、我喜欢了一个女生,为了弄清楚她是什么样的人,所以我关注她小号。然后被她发现,扇了我一巴掌,把我从厕所赶出来了。</P>
<P>8、老是看到有人说趴在兰博基尼方向盘上哭,然后大家都很羡慕的样子,所以我想问一下,哪里有兰博基尼方向盘出售?</P>
<P>9、这个世界上漂亮女孩已经那么多,为啥不能多一个我?</P>
<P>10、我都19了,还没来月经,身边的女孩纸胸都老高了,我还是平胸,怎么办啊!可怕的是腿上胳膊上汗毛老长了,更更可怕的是裤裆里,长出来个可怕的东西,有时候软软的,有时候硬硬的,好可怕啊,我该怎么办?</P>
</span>
翻页所在的html代码
<div class=zw_page1>
下一篇:<a href="../../JokeHtml/bxnn/2017122722221351.htm">爆逗二货,醉人的笑容你会有</a>
</div>
<div class=zw_page2>
上一篇:<a href="../../JokeHtml/bxnn/2017122900222852.htm">搞笑很出色的是二货</a>
</div>
2、定义提取逻辑
先依据初始链接提取笑话内容
分支1:
提取下一篇链接,依据下一篇链接提取笑话内容
如此循环,直至没有下一篇链接
分支2:
提取上一篇链接,依据上一篇链接提取笑话内容
如此循环,直至没有上一篇链接
Part6:创建Scrapy项目抓取数据
1、创建Scrapy项目
E:\scrapy>scrapy startproject myScrapy1815
执行上面的命令生成项目myScrapy1815
再在目录myScrapy1815\myScrapy1815\spiders\下创建文件myJoke_spider.py
项目的完整目录结构如下
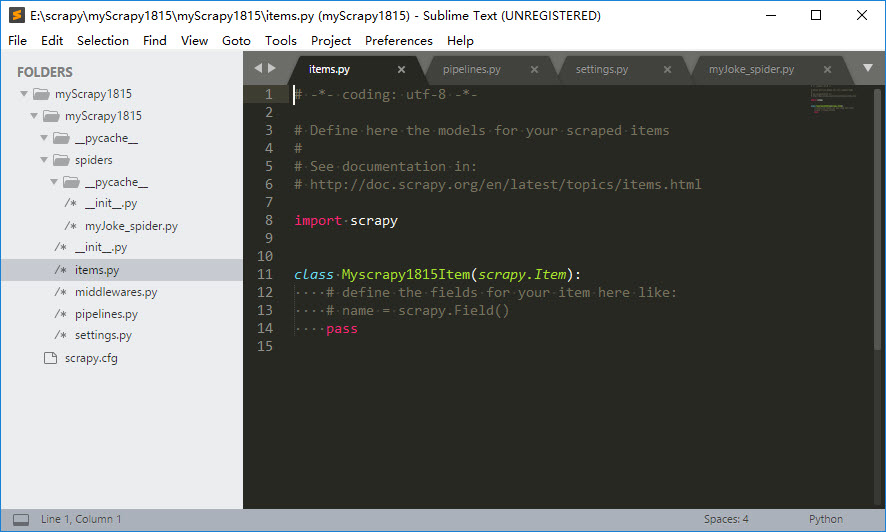
2、定义Item
Item是保存爬取到的数据的容器,可以理解为编程中的对象。一个Item即一个对象保存的是一条记录。
打开文件myScrapy1815\myScrapy1815\items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html import scrapy class Myscrapy1815Item(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass class JokeItem(scrapy.Item):
# 正文内容
joke_content = scrapy.Field()
3、编写Spider
打开文件myScrapy1815\myScrapy1815\spiders\myJoke_spider.py
添加如下内容
import scrapy
from scrapy.http.request import Request
from myScrapy1815.items import JokeItem class JokeSpider(scrapy.Spider):
name = "joke"
allowed_domains = ["jokeji.cn"]
start_urls = [
"http://www.jokeji.cn/JokeHtml/bxnn/2017122900211092.htm"
] def parse(self, response):
# 获取笑话内容
jokes = response.xpath('//span[@id="text110"]/p').extract()
for joke in jokes:
item = JokeItem()
item['joke_content'] = joke
yield item # 获取下一篇链接
nexthref = response.xpath('//div[@class="zw_page1"]/a/@href').extract_first()
if nexthref is not None:
# 将相对url转为绝对url
nexthref = response.urljoin(nexthref)
# 继续获取下一篇笑话
yield Request(nexthref, callback=self.parseNexthref) # 获取上一篇链接
prevhref = response.xpath('//div[@class="zw_page2"]/a/@href').extract_first()
if prevhref is not None:
# 将相对url转为绝对url
prevhref = response.urljoin(prevhref)
# 继续获取下一篇笑话
yield Request(prevhref, callback=self.parsePrevhref) def parseNexthref(self, response):
# 获取笑话内容
jokes = response.xpath('//span[@id="text110"]/p').extract()
print(jokes)
for joke in jokes:
item = JokeItem()
item['joke_content'] = joke
yield item # 获取下一篇链接
nexthref = response.xpath('//div[@class="zw_page1"]/a/@href').extract_first()
if nexthref is not None:
# 将相对url转为绝对url
nexthref = response.urljoin(nexthref)
# 继续获取下一篇笑话,测试时可以将下一行代码注释掉
#yield Request(nexthref, callback=self.parseNexthref) def parsePrevhref(self, response):
# 获取笑话内容
jokes = response.xpath('//span[@id="text110"]/p').extract()
for joke in jokes:
item = JokeItem()
item['joke_content'] = joke
yield item # 获取上一篇链接
prevhref = response.xpath('//div[@class="zw_page2"]/a/@href').extract_first()
if prevhref is not None:
# 将相对url转为绝对url
prevhref = response.urljoin(prevhref)
# 继续获取上一篇笑话,测试时可以将下一行代码注释掉
#yield Request(prevhref, callback=self.parsePrevhref)
4、编写Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline
打开文件myScrapy1815\myScrapy1815\pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html import sqlite3
import json
import re
from openpyxl import Workbook class Myscrapy1815Pipeline(object): def __init__(self):
# 文件文件
self.file = open('myItems.json', 'w', encoding='utf-8')
# Excel文件
self.wb = Workbook()
self.ws = self.wb.active
self.ws.title = "笑话集" #定义sheet名称
self.ws.append(['joke_content']) #定义表头
# 数据库连接
self.conn = sqlite3.connect("E:\\django\\myProject001\\db.sqlite3") # 当spider被开启时方法被调用
def open_spider(self, spider):
pass # 每个item pipeline组件都需要调用该方法
def process_item(self, item, spider):
# 写入文本文件
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
# 写入Excel文件
self.ws.append([item['joke_content']])
self.wb.save('myItems.xlsx')
# 写入数据库
record = item['joke_content']
record = record.replace('<BR>','\r\n')
pattern = re.compile(r'<[^>]+>', re.S)
record = pattern.sub('', record)
sql="insert into joke_jokes(jokeText,createDate,modifyDate) values('"+record+"',datetime('now','localtime'),datetime('now','localtime'))"
self.conn.execute(sql)
self.conn.commit()
return item # 当spider被关闭时方法被调用
def close_spider(self, spider):
self.file.close()
self.conn.close()
pass
5、激活Item Pipeline
打开文件myScrapy1815\myScrapy1815\settings.py
删掉如下三行代码之前的注释符#
ITEM_PIPELINES = {
'myScrapy1815.pipelines.Myscrapy1815Pipeline': 300,
}
6、启动Spider
E:\scrapy\myScrapy1815>scrapy crawl joke
抓取的数据,文本文件格式如下
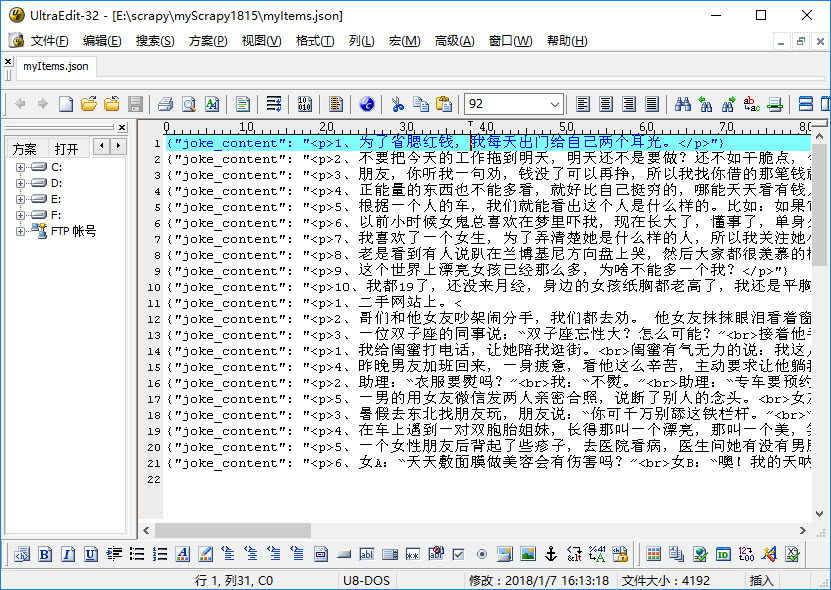
抓取的数据,Excel文件格式如下
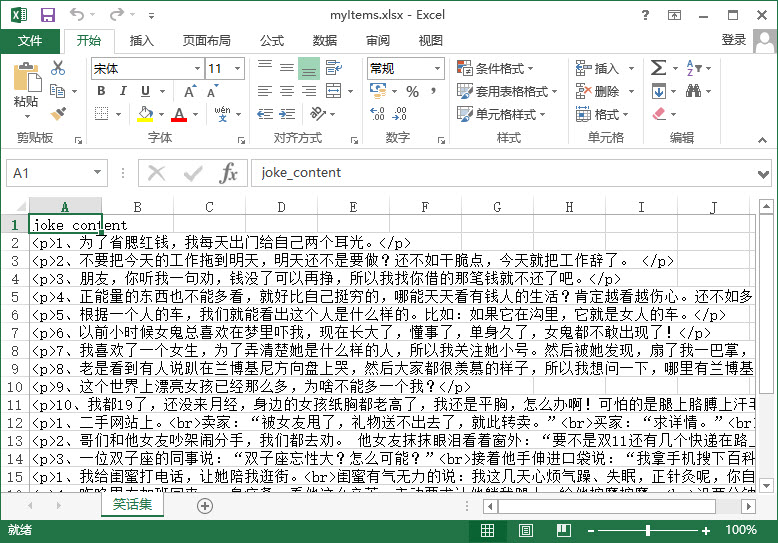
抓取的数据,保存在SQLite数据库中如下
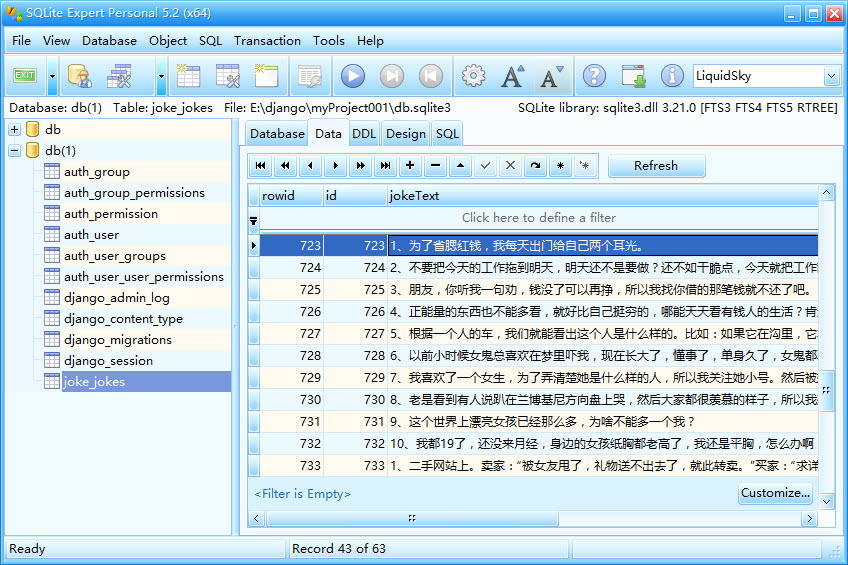
Part7:以瀑布流方式显示笑话内容
1、修改settings.py
文件位置:myProject001\myProject001\settings.py
ALLOWED_HOSTS = ['10.61.226.236','127.0.0.1','localhost']
允许通过以上3个地址访问
2、修改应用的urls.py
文件位置:myProject001\joke\urls.py
from django.urls import path
from . import views urlpatterns = [
path('', views.index, name='index'),
path('index_ajax/', views.index_ajax),
]
3、修改views.py
文件位置:myProject001\joke\views.py
from json import dumps
from django.core import serializers
from django.shortcuts import render
from django.http import HttpResponse,JsonResponse
from . import models # 页面首次加载的记录数
FIRST_PAGE_SIZE = 50
# Ajax每次加载的记录数
PAGE_SIZE = 20 def index(request):
# 首次加载
jokes = models.Jokes.objects.all()[0:FIRST_PAGE_SIZE]
return render(request, 'joke/index.html', {'jokes':jokes}) def index_ajax(request):
# 当前页码
pageIndex = int(request.POST.get('pageIndex',''))
# 总记录数
totalCount = models.Jokes.objects.filter().count() # 定义提取记录的范围(数组上标、数组下标)
lBound = FIRST_PAGE_SIZE + (pageIndex-1) * PAGE_SIZE
uBound = FIRST_PAGE_SIZE + pageIndex * PAGE_SIZE # 是否有下一页(上标小于总记录数时有下一页)
hasNextPage = 1 if uBound <= totalCount else 0 # 如果上标大于或等于总记录数,则上标使用总记录数
if uBound >= totalCount:
uBound = totalCount # 按范围提取记录
jokes = models.Jokes.objects.all()[lBound:uBound] # 序列化JSON
json_data = {}
json_data['hasNextPage'] = hasNextPage
json_data['jokes'] = serializers.serialize('json', jokes) # 返回JSON格式的数据
return HttpResponse(JsonResponse(json_data), content_type="application/json")
4、修改模板文件index.html
文件位置:myProject001\joke\templates\joke\index.html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<!-- 上述3个meta标签*必须*放在最前面,任何其他内容都*必须*跟随其后! -->
<title>段子</title>
{% load static %}
<link rel="stylesheet" type="text/css" href="{% static 'joke/css/bootstrap.min_v3.3.7.css' %}" />
<link rel="stylesheet" type="text/css" href="{% static 'joke/css/style.css' %}" />
<!-- HTML5 shim and Respond.js for IE8 support of HTML5 elements and media queries -->
<!-- WARNING: Respond.js doesn't work if you view the page via file:// -->
<!--[if lt IE 9]>
<script src="https://cdn.bootcss.com/html5shiv/3.7.3/html5shiv.min.js"></script>
<script src="https://cdn.bootcss.com/respond.js/1.4.2/respond.min.js"></script>
<![endif]-->
</head>
<body>
<div class="container">
<div id="masonry" class="row masonry">
{% for joke in jokes %}
<div class="col-md-4 col-sm-6 col-xs-12 item ">
<div class="well well-sm" style="line-height:180%;">
<span class="label label-success">{{ joke.pk }}</span> {{ joke.jokeText }}
</div>
</div>
{% endfor %}
</div>
</div>
<script src="{% static 'joke/js/jquery.min_v1.12.4.js' %}"></script>
<script src="{% static 'joke/js/bootstrap.min_v3.3.7.js' %}"></script>
<script src="{% static 'joke/js/masonry.pkgd.min_v4.2.0.js' %}"></script>
<script src="{% static 'joke/js/imagesloaded.pkgd.min_v4.1.3.js' %}"></script>
<!-- 瀑布流布局 -->
<script>
$("#loadingModal").modal('show');
$('.masonry').masonry({
//itemSelector: '.item'
});
</script>
<!-- 页面无限加载 -->
<script>
// 默认加载第2页
var pageIndex = 1;
// 是否正在加载标记
var isLoading = 0;
// 是否已提示没有更多内容
var isNotice = 0;
// 是否还有更多
var hasNextPage = 1;
// 页面滚动到底部,触发加装
$(window).scroll(function(){
var scrollTop = $(this).scrollTop();
var scrollHeight = $(document).height();
var windowHeight = $(this).height();
if(scrollTop + windowHeight == scrollHeight){
if(hasNextPage == 0 & isNotice == 0){
// 没有下一页内容时提示
isNotice = 1;
$('#masonry').append('<div id="noticeInfomation" class="col-md-4 col-sm-6 col-xs-12 item "><div class="alert alert-warning"><strong>提示:</strong>没有更多内容了...</div></div>');
$('#masonry').masonry('reloadItems');
$('#masonry').masonry('layout');
}else if(hasNextPage == 1 & isLoading == 0){
// 避免Ajax执行过程中反复被调用
isLoading = 1;
$('#masonry').append('<div id="noticeInfomation" class="col-md-4 col-sm-6 col-xs-12 item "><div class="alert alert-warning"><strong>提示:</strong>正在加载更多内容...</div></div>');
$('#masonry').masonry('reloadItems');
$('#masonry').masonry('layout');
setTimeout("loadJoke(pageIndex);", 1000);
}
}
});
// Ajax方法
function loadJoke(arg){
//var host = 'localhost';
//var port = '8000';
var labelCss = 'label label-info';
if(pageIndex%2 == 1){
labelCss = 'label label-info';
}
else{
labelCss = 'label label-success';
}
$.ajax({
url: "./index_ajax/",
type: "POST",
dataType: 'json',
data: {pageIndex: arg},
success: function (data) {
$("#noticeInfomation").remove();
hasNextPage = data['hasNextPage'];
jokes = JSON.parse(data['jokes']);
for (var obj in jokes){
$('#masonry').append('<div class="col-md-4 col-sm-6 col-xs-12 item "><div class="well well-sm" style="line-height:180%;">'+'<span class="'+labelCss+'">'+jokes[obj].pk+'</span> '+jokes[obj].fields.jokeText+'</div></div>');
$('#masonry').masonry('reloadItems');
$('#masonry').masonry('layout');
}
pageIndex = pageIndex + 1;
isLoading = 0;
}
});
};
//Django的CSRF保护机制(ajax)
$.ajaxSetup({
data: {csrfmiddlewaretoken: '{{ csrf_token }}' },
});
</script>
</body>
</html>
5、启动应用
访问应用:http://10.61.226.236/joke/
页面效果如下
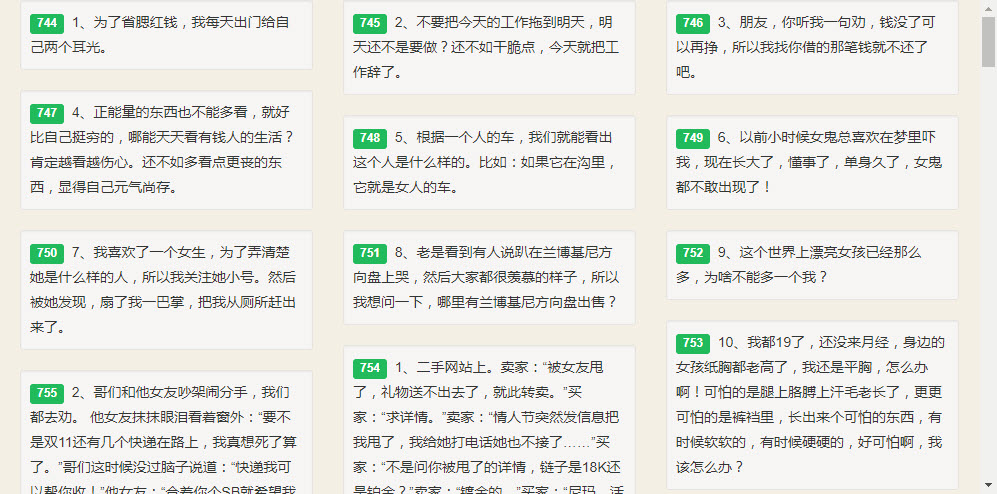
6、补充说明
UI使用了bootstrap、jquery、masonry、ajax无限加载
=====结束=====
Scrapy1.4爬取笑话网站数据,Python3.5+Django2.0构建笑话应用的更多相关文章
- python3.5+django2.0快速入门(二)
昨天写了python3.5+django2.0快速入门(一)今天将讲解配置数据库,创建模型,还有admin的后台管理. 配置数据库 我们打开mysite/mysite/settings.py这个文件. ...
- python3.5+django2.0快速入门(一)
因为这篇教程需要用到anaconda的一些操作,如果还不懂anaconda的操作的同学可以看下这篇文章python 入门学习之anaconda篇. 创建python3+的开发环境 直接在终端输入:co ...
- Python3.6+Django2.0以上 xadmin站点的配置和使用
1. xadmin的介绍 django自带的admin站点虽然功能强大,但是界面不是很好看.而xadmin界面好看,功能更强大,并完全支持Bootstrap主题模板.xadmin内置了丰富的插件功能. ...
- Python爬取招聘网站数据,给学习、求职一点参考
1.项目背景 随着科技的飞速发展,数据呈现爆发式的增长,任何人都摆脱不了与数据打交道,社会对于“数据”方面的人才需求也在不断增大.因此了解当下企业究竟需要招聘什么样的人才?需要什么样的技能?不管是对于 ...
- 【Python3.6+Django2.0+Xadmin2.0系列教程一】环境搭建及项目创建
由于工作需要,接触了大半年时间的Django+xadmin框架,一直没空对这块对进行相关的梳理.最近在同事的怂恿下,就在这分享下笔者的学习及工作经验吧. 好了,话不多说,下面开始进入正题: 环境需求: ...
- Python3.7+Django2.0.4配合Mongodb打造高性能高扩展标签云存储方案
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_141 书接上回,之前有一篇文章提到了标签云系统的构建:Python3.7+jieba(结巴分词)配合Wordcloud2.js来构 ...
- python3下Django2.0配置最新xadmin详解
1,打开pycharm,创建一个Django项目 2,安装Django,默认是最新版本,pip3 install -i https://pypi.douban.com/simple/ django 3 ...
- python爬取招聘网站数据
# -*- coding: utf-8 -*- # 爬虫分析 from bs4 import BeautifulSoup from lxml import etree from selenium im ...
- 【Python3.6+Django2.0+Xadmin2.0系列教程之二】学生信息管理系统(入门篇)
上一篇我们已经创建好了一个Xadmin的基础项目,现在我们将在此基础上构建一个同样很基础的学生信息管理系统. 一.创建模型 模型是表示我们的数据库表或集合类,并且其中所述类的每个属性是表或集合的字段, ...
随机推荐
- Java学习之计算机基础(二)
今天主要介绍原码.反码与补码的知识.了解原码.反码与补码的知识,可以帮助我们更好地理解在计算机内部是如何进行运算的,同时对于后面更好地学习和理解Java基本数据类型及其范围打下基础. 背景知识: 在计 ...
- OBS源码解析(1)main函数
int main(int argc, char *argv[]){#ifndef _WIN32 signal(SIGPIPE, SIG_IGN);#endif #ifdef _WIN32 /*Open ...
- C++ 函数对象
函数对象 c++中函数名后的()称为函数调用运算符.函数调用运算符也可以重载,如果某个类重载了函数调用运算符,则该类的实例就是一个函数对象.函数对象本身并不是很有用,但他们使得算法操作的参数化策略成为 ...
- WINDOWS java 不能正常卸载 问题, (其他系统问题 也可以试试)
1.JAVA 原安装包无法卸载 不知道 有没有通知 碰到过这种情况的 自己碰到过3次这种情况了, 卸载不掉, 在网上 找了N多中 方法, 注册表什么的都被翻烂了, 单还是没用,其中有一次还把 ...
- JAVA通过Gearman实现MySQL到Redis的数据同步(异步复制)
MySQL到Redis数据复制方案 无论MySQL还是Redis,自身都带有数据同步的机制,像比较常用的 MySQL的Master/Slave模式 ,就是由Slave端分析Master的binlog来 ...
- Dell poweredge r210进BIOS改动磁盘控制器(SATA Controller)接口模式
Dell poweredge r210进BIOS改动磁盘控制器(SATA Controller)接口模式 开机后按F2键进入BIOS设置,例如以下图: BIOS设置主界面: 使用上下键移动光标到&qu ...
- SOJ--Zig-Zag
Zig-Zag 在图形图像处理中经常须要将一个二维的图像矩阵转化为一维的向量.二维化一维的过程实际上就是将二维数组的元素按某种顺序构成一维数组. 一种经常使用的序列叫"Zig-Zag&quo ...
- 快速上手virtualenv
五分钟轻松学会管理项目开发环境. 在开发Python应用程序的时候,系统安装的Python3只有一个版本:3.x.所有第三方的包都会被pip安装到Python3的site-packages目录下. p ...
- 一 、Spring Boot 学习之项目搭建
一.简介 spring 官方网站本身使用Spring 框架开发,随着功能以及业务逻辑的日益复杂,应用伴随着大量的XML配置文件以及复杂的Bean依赖关系. 随着Spring 3.0的发布,Spring ...
- 数据库、ArcCatalog空间数据源正常访问,数据库设置没问题时,ArcEngine连接SDE时报"ORA-12560: TNS: 协议适配器错误"的解决办法;ArcEngine连接SDE总结
碰到的问题描述: 通过C# 基于ArcEngine写SDE直连的时候测试项目连接属性设置为如下: tPropSet.SetProperty("User", "GISDAT ...