利用scrapy框架进行爬虫
这里写一下爬虫大概的步骤,主要是自己巩固一下知识,顺便复习一下。
一,网络爬虫的步骤
1,创建一个工程
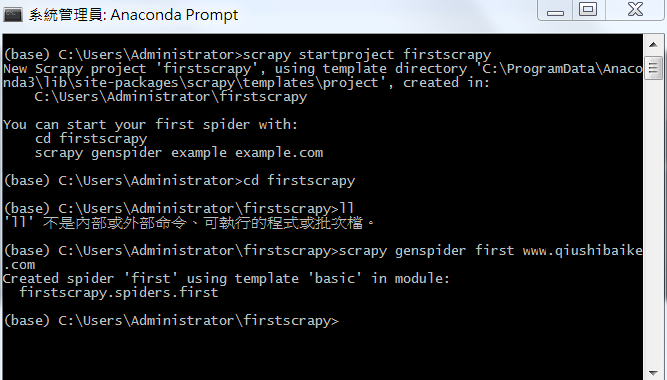
scrapy startproject 工程名称
创建好工程后,目录结构大概如下:

其中:
scrapy.cfg:项目的主配置信息(真正爬虫相关的配置信息在settings.py文件中)
items.py:设置数据存储模板,用于结构化数据,如:Django的Model
pipelines:数据持久化处理
settings.py:配置文件,如:递归的层数,并发数,延迟下载等
spiders:爬虫目录,如:创建文件,编写爬虫解析规则
2,在工程目录下创建一个爬虫文件
1, cd 工程
2,scrapy genspider example example.com
其中: example:表示爬虫文件的名称
example.com 表示起始的url(这个url可以随意写,最后在文件中修改即可)
3,对应的文件中编写爬虫程序来完成爬虫的相关操作
打开first.py,然后进入编写:

4,配置文件的编写
进入settings.py 中修改2个地方:
1,在大概19行中:对请求载体的身份进行伪装
我们可以去谷歌中找一个User-Agent的值 复制进去。效果如下: USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36
(KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36' 2,在大概22行中,修改robots协议
robots协议是君子协议,大概爬虫的话,我们可以不遵照这个协议,哈哈哈哈 ROBOTSTXT_OBEY = False
5,执行
scrapy crwal 爬虫文件的名称 --nolog(组织日志信息的输出) # 输出打印信息
scrapy crawl first # 不输出打印信息
scrapy crawl first --nolog
效果如下:
【爬取的是杨子晚报,这里就以此为例,创建scrapy爬虫 网址:http://www.yangtse.com/】
第一步:安装scrapy框架
(这里不做详细介绍了,要是安装遇到问题的朋友们,可以参考下面链接
http://www.cnblogs.com/wj-1314/p/7856695.html)
第二步:创建scrapy爬虫文件
格式:scrapy startproject + 项目名称
scrapy startproject yangzi
第三步:进入爬虫文件
格式:cd 项目名称
cd yangzi
第四步:创建爬虫项目
格式:scrapy genspider -t basic 项目名称 网址
具体用法如下:

scrapy genspider -t basic yz http://www.yangtse.com/
创建好了,如下图:

解释一下文件:
- scrapy.cfg:项目的配置文件
- yangzi:该项目的python模块。之后您将在此加入代码。
- yangzi/items.py:项目中的item文件。
- yangzi/pipelines.py:项目中的pipelines文件。
- yangzi/yz/:放置spider代码的目录。
第五步:进入爬虫项目中,先写items
写这个的目的就是告诉项目,你要爬去什么东西,比如标题,链接,作者等.
Item是保存爬取到的数据的容器:其使用方法和python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。
类似在ORM中做的一样,你可以通过创建一个scrapy.Item类,并且定义类型为scrapy.Field的类属性来定义一个Item。
首先根据需要从dmoz.org获取到的数据对item进行建模。我们需要从dmoz中获取名字,url,以及网站的描述。对此,在item中定义相应的字段。
以我写的为例,我想爬取标题,链接,内容,如下:
class YangziItem(scrapy.Item):
# define the fields for your item here like:
#标题
title = scrapy.Field()
#链接
link = scrapy.Field()
#内容
text = scrapy.Field()
第六步:进入pipelines,设置相应程序
分析爬去的网站,依次爬取的东西,因为pipelines是进行后续处理的,比如把数据写入MySQL,或者写入本地文档啊等等,就在pipelies里面写。这里直接输出,不做数据库的导入处理
class YangziPipeline(object):
def process_item(self, item, spider):
print(item["title"])
print(item["link"])
return item
第七步:再写自己创建的爬虫
(其实,爬虫和pipelines和settings前后顺序可以颠倒,这个不重要,但是一定要先写items)
Spider是用户编写用于从单个网站(或者一些网站)爬取数据的类。
其包含了一个用于下载的初始url,如何跟进网页中的链接以及如何分析页面中的内容,提取生成item的方法。
为了创建一个Spider,您必须继承scrapy.Spider类,且定义以下三个属性:
name:用于区别Spider。改名字必须是唯一的,您不可以为不同的Spider设定相同的名字。start_urls:包含了Spider在启动时进行爬取的url列表。因此,第一个被获取的页面给将是其中之一。后续的URL则从初始的URL获取到的数据中提取。parse():是spider的一个方法。被调用时,每个初始url完成下载后生成的Response对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
进入爬虫后,先导入items,接下来需要创建一个ITEM容器,
it = YangziItem()
然后写自己的要爬去的内容,分析网页后,利用xpath写
def parse(self, response):
it = YangziItem()
it["title"] = response.xpath('//div[@class="box-text-title]/text()').extract()
it["link"] = response.xpath('//a[@target="_blank"]/@href').extract()
#it["text"] = response.xpath().extract()
yield it
第八步:设置settings
在settings中配置pipelines(ctrl+f 找到pipelines,然后解除那三行的注释,大约在64-68行之间),如下图

第九步:运行爬虫文件
scrapy crawl yz
scrapy crawl yz --nolog #不想显示日志文件
利用scrapy框架进行爬虫的更多相关文章
- Scrapy 框架,爬虫文件相关
Spiders 介绍 由一系列定义了一个网址或一组网址类如何被爬取的类组成 具体包括如何执行爬取任务并且如何从页面中提取结构化的数据. 简单来说就是帮助你爬取数据的地方 内部行为 #1.生成初始的Re ...
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 群辉6.1.7安装scrapy框架执行爬虫
只针对会linux命令,会python的伙伴, 使用环境为: 群辉ds3615xs 6.1.7 python3.5 最近使用scrapy开发了一个小爬虫,因为很穷没有服务器可已部署. 所以打起了我那台 ...
- 09 Scrapy框架在爬虫中的使用
一.简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.它集成高性能异步下载,队列,分布式,解析,持久化等. Scrapy 是基于twisted框架开发而来,twisted是一个 ...
- 基于scrapy框架的爬虫
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. scrapy 框架 高性能的网络请求 高性能的数据解析 高性能的 ...
- 基于scrapy框架的爬虫基本步骤
本文以爬取网站 代码的边城 为例 1.安装scrapy框架 详细教程可以查看本站文章 点击跳转 2.新建scrapy项目 生成一个爬虫文件.在指定的目录打开cmd.exe文件,输入代码 scrapy ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- Scrapy 框架 分布式 爬虫
分布式 爬虫 scrapy-redis 实现 原生scrapy 无法实现 分布式 调度器和管道无法被分布式机群共享 环境安装 - pip install scrapy_redis 导包:from sc ...
随机推荐
- Java开发小技巧(二):自定义Maven依赖
前言 我们在项目开发中经常会将一些通用的类.方法等内容进行打包,打造成我们自己的开发工具包,作为各个项目的依赖来使用. 一般的做法是将项目导出成Jar包,然后在其它项目中将其导入,看起来很轻松,但是存 ...
- 使用邮件激活授权/ LightningChart license
在无网络连接的情况下,可以采用邮件的方式激活授权. 先打开License Manager,然后选 Activate/Deactivate via email, 如下图所示: 此邮件将自动发送到 lic ...
- 【剑指Offer学习】【面试题21:包括min 函数的栈】
题目: 定义栈的数据结构,请在该类型中实现一个可以得到栈的最小素的min 函数.在该栈中.调用min.push 及pop的时间复杂度都是0(1) 解题思路: 把每次的最小元素(之前的最小元素和新压入战 ...
- maven安装配置及使用maven创建一个web项目
今天开始学习使用maven,现在把学习过程中的资料整理在这边. 第一部分.maven安装和配置. http://jingyan.baidu.com/article/295430f136e8e00c7e ...
- Android查缺补漏(View篇)--自定义 View 的基本流程
View是Android很重要的一部分,常用的View有Button.TextView.EditView.ListView.GridView.各种layout等等,开发者通过对这些View的各种组合以 ...
- 【ANT】java项目生成文件示例
<?xml version="1.0" ?> <project default="dist"> <property name=&q ...
- Lucene实现索引和查询
0引言 随着万维网的发展和大数据时代的到来,每天都有大量的数字化信息在生产.存储.传递和转化,如何从大量的信息中以一定的方式找到满足自己需求的信息,使之有序化并加以利用成为一大难题.全文检索技术是现如 ...
- go实例之轻量级线程goroutine、通道channel与select
1.goroutine线程 goroutine是一个轻量级的执行线程.假设有一个函数调用f(s),要在goroutine中调用此函数,请使用go f(s). 这个新的goroutine将与调用同时执行 ...
- 【Netty】源码分析目录
前言 为方便系统的学习Netty,特整理文章目录如下. [Netty]第一个Netty应用 [Netty]Netty核心组件介绍 [Netty]Netty传输 [Netty]Netty之ByteBuf ...
- centOS7 mini配置linux服务器(五) 安装和配置tomcat和mysql
配置java运行环境,少不了服务器这一块,而tomcat在服务器中占据了很大一部分份额,这里就简单记录下tomcat安装步骤. 下载 首先需要下载tomcat7的安装文件,地址如下: http://t ...