hadoop+hive+spark搭建(三)
一、spark安装
因为之前安装过hadoop,所以,在“Choose a package type”后面需要选择“Pre-build with user-provided Hadoop [can use with most Hadoop distributions]”,然后,点击“Download Spark”后面的“spark-2.1.0-bin-without-hadoop.tgz”下载即可。Pre-build with user-provided Hadoop: 属于“Hadoop free”版,这样,下载到的Spark,可应用到任意Hadoop 版本。

上传spark软件包到任意节点上
解压缩spark软件包到/usr/local/目录下

重命名为spark文件夹
mv spark-2.1.0-bin-without-hadoop/ spark
重命名conf/目录下spark-env.sh.template为spark-env.sh
cp spark-env.sh.template spark-env.sh
重命名conf/目录下slaves.template为slaves
mv slaves.template slaves
二、配置spark
编辑conf/spark-env.sh文件,在第一行添加以下配置信息:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
#上述表示Spark可以把数据存储到Hadoop分布式文件系统HDFS中,也可以从HDFS中读取数据。如果没有配置上面信息,Spark就只能读写本地数据,无法读写HDFS数据。
export JAVA_HOME=/usr/local/jdk64/jdk1.8.0
编辑conf/slaves文件
三、验证spark是否安装成功
在spark目录中输入命令验证spark是否安装成功
bin/run-example SparkPi
bin/run-example SparkPi 2>&1 | grep "Pi is" #过滤显示出pi的值

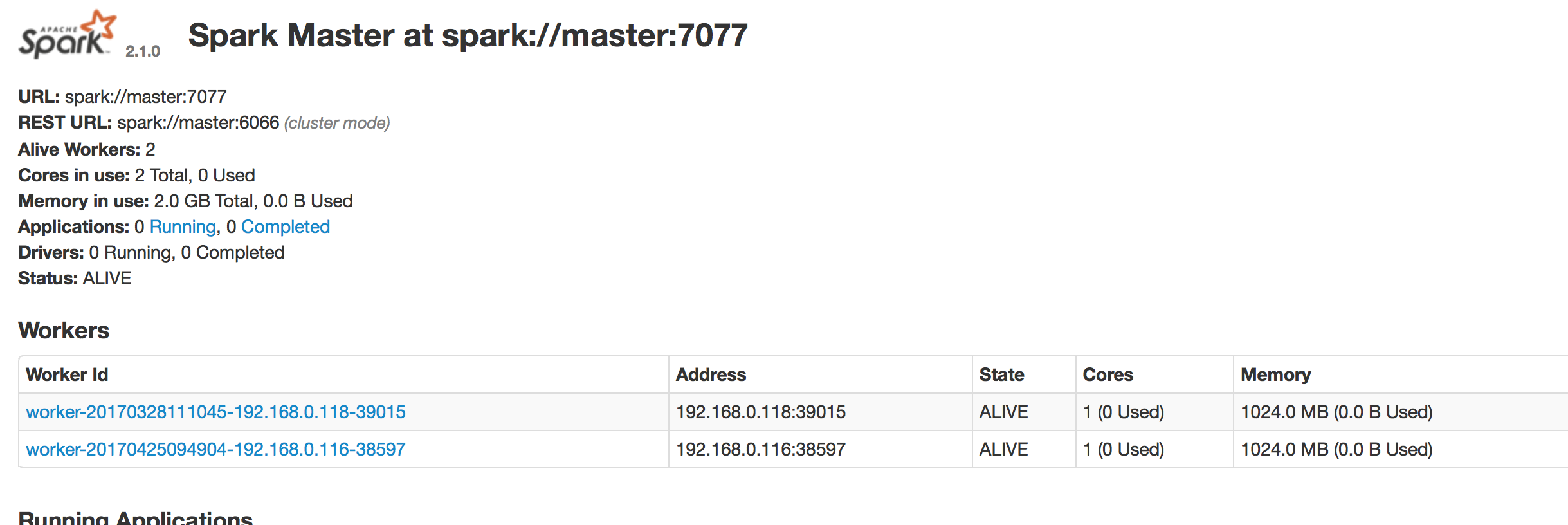
web界面为8080端口
集群模式下shell
pyspark --master spark://master:7077 #python
提交应用
spark-submit
--class <main-class> #需要运行的程序的主类,应用程序的入口点
--master <master-url> #Master URL,下面会有具体解释
--deploy-mode <deploy-mode> #部署模式
... # other options #其他参数
<application-jar> #应用程序JAR包
[application-arguments] #传递给主类的主方法的参数
hadoop+hive+spark搭建(三)的更多相关文章
- hadoop+hive+spark搭建(一)
1.准备三台虚拟机 2.hadoop+hive+spark+java软件包 传送门:Hadoop官网 Hive官网 Spark官网 一.修改主机名,hosts文件 主机名修改 hostnam ...
- hadoop+hive+spark搭建(二)
上传hive软件包到任意节点 一.安装hive软件 解压缩hive软件包到/usr/local/hadoop/目录下 重命名hive文件夹 在/etc/profile文件中添加环境变量 export ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- hadoop和spark搭建记录
因玩票需要,使用三台搭建spark(192.168.1.10,192.168.1.11,192.168.1.12),又因spark构建在hadoop之上,那么就需要先搭建hadoop.历经一个两个下午 ...
- 了解大数据的技术生态系统 Hadoop,hive,spark(转载)
首先给出原文链接: 原文链接 大数据本身是一个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞生的.你能够把它比作一个厨房所以须要的各种工具. 锅碗瓢盆,各 ...
- 一文教你看懂大数据的技术生态圈:Hadoop,hive,spark
转自:https://www.cnblogs.com/reed/p/7730360.html 大数据本身是个很宽泛的概念,Hadoop生态圈(或者泛生态圈)基本上都是为了处理超过单机尺度的数据处理而诞 ...
- 配置Hadoop,hive,spark,hbase ————待整理
五一一天在家搭建好了集群,要上班了来不及整理,待下周周末有时间好好整理整理一个完整的搭建hadoop生态圈的集群的系列 若出现license information(license not accep ...
- Hadoop集群搭建(三)~centos6.8网络配置
安装完centos之后,进入系统,进行网络配置.主要分为五个部分: 修改虚拟机网络编辑器:配置Winodws访问虚拟机:配置centos网卡:通过网络名访问虚拟机配置网络服务. (一)虚拟机网络编辑器 ...
- 服务器Hadoop+Hive搭建
出于安全稳定考虑很多业务都需要服务器服务器Hadoop+Hive搭建,但经常有人问我,怎么去选择自己的配置最好,今天天气不错,我们一起来聊一下这个话题. Hadoop+Hive环境搭建 1虚拟机和系统 ...
随机推荐
- Selenium自动化脚本开发总结
Selenium Selenium 是ThoughtWorks专门为Web应用程序编写的一个验收测试工具. Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE.Mo ...
- HBase架构
文章作者:luxianghao 文章来源:http://www.cnblogs.com/luxianghao/p/6573817.html 转载请注明,谢谢合作. 免责声明:文章内容仅代表个人观点, ...
- JsonCpp(C++程序使用)
C++ json解析库 github C++: Makefile目录cmd:make 得到build 得到.a静态库 Eclipse引入头文件 (include目录) 引入.a静态库 编译设置: O ...
- Python总的字符串
Python总最常用的类型,使用单引号双引号表示.三引号之间的字符串可以跨多行并且可以是原样输出的. Python中不支持字符类型,字符也是字符串. ---字符串的CRUD [1:3] [:6] -- ...
- 交叉编译Python-2.7.13到ARM(aarch32)平台
作者:彭东林 邮箱:pengdonglin137@163.com QQ:405728433 环境 主机: ubuntu14.04 64bit 开发板: qemu + vexpress-a9 (参考: ...
- JS把命名空间传递给模块形式
//方法依赖 jquery 或者其他 有扩展方法 extend() 类库 例如: underscore.js 链接地址 http://underscorejs.org var app = {}; ( ...
- Android-自定义控件之时针-霞辉
注释已经比较详细了,废话就不多说了.贴代码了 时针分针秒钟都做上去了,采用的方法也很简单,仔细看一会就能看懂 自定义View类 package com.xh.mytime; import java.u ...
- 网站优化记录-通过命令预编译Asp.net 网站,成功优化到毫秒级别。
在去年一次项目上线时发现部署的站点首次访问跟回收后响应特别慢.(使用的是vs工具预编译的方式发布),在随后找到解决办法是通过命令预编译Asp.net 网站,成功解决站点响应在毫秒级别. 预编译 ASP ...
- J2那几个E和Web基础
收到PHP童鞋的反馈: 我觉得不用讲太基础的语法,基础语法大家自己去看,主要讲讲java web开发的一个流程,从开始写代码,到编译,发布,上线,回滚整个流程 大体上的环节,以及需要用到哪些工具 具体 ...
- XJOI1657&Codevs1255搭积木【树状动规】
搭积木 一种积木搭建方式,高为H的积木,最底层有M个积木,每一层的积木数是他的低一层的积木数+1或-1.总共有N个积木.(且每行积木数不超过10)比如上图N=13 H=6 M=2. 输入格式: 第一行 ...