Hadoop生态系统图解
Hadoop生态架构图
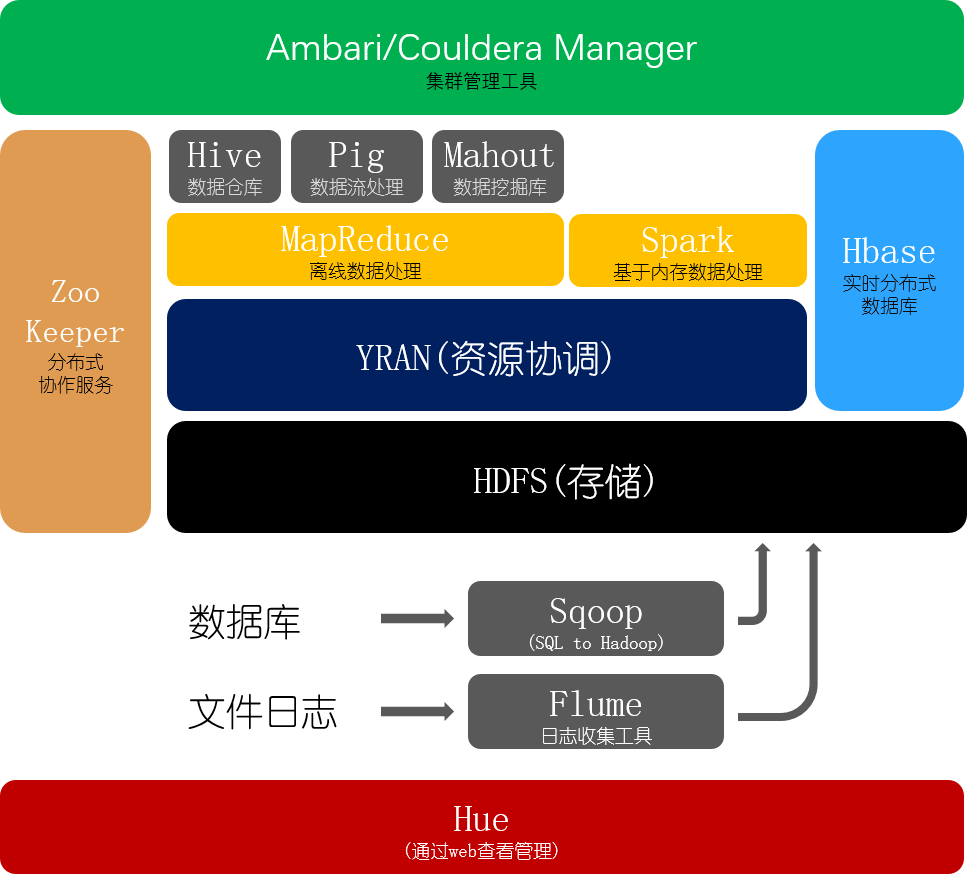
参考文章:
Hadoop生态系统介绍
HDFS架构
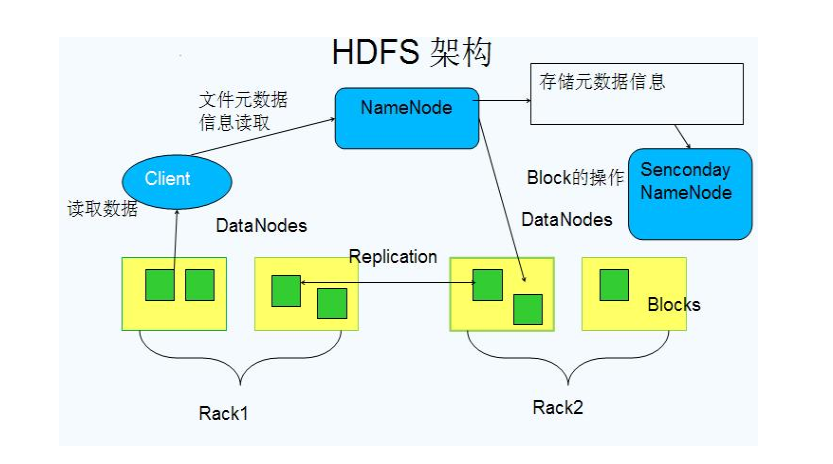
1.NaneDode:主节点,**存储文件的元数据**如文件名,文件目录结构,文件属性(生成时间,副本数量,文件权限),以及每个文件的块列表所在DataNode等
一个JAVA进程:数据存储在内存中,为了速度读写(本地还有备份)
本地磁盘:1、fsimage:镜像文件
2、edits :编辑日志
2.DataNode:数据节点,实际的本地文件系统,**存储文件块数据,以及快数据的检验和**
真正的存储:数据在磁盘中
3.Secondary NameNode用来**监控HDFS状态的辅助后台程序**,每隔一段时间**获取HDFS元数据快照**,就是定时对本地磁盘的 NameNode 的 fsimage 和 edits 进行合并,不断更新镜像
数据以block方式存储
Hadoop2.x块大小:128M
参考文章:
HDFS 原理、架构与特性介绍
谷歌三大核心技术(一)Google File System中文版
YARN架构

1.ResourceManager 资源管理者
*接收客户端请求
*启动/监控ApplicationMaster
*监控NodeManager
*资源分配与调度
2.NodeManager 节点管理者
*管理节点资源
*处理来自ResourceManager的任务
*处理来自ApplicationMaster的任务
3.ApplicationMaster 应用主管
*数据切分
*为应用程序向ResourceManager提出资源申请,并分配给内部任务
*任务监控与容错
4.container 容器
*对任务运行环境的抽象,封装了CPU,内存等多维资源以及环境变量,启动命令等运行任务的相关信息
参考文章:
Hadoop构架概览
MapReduce框架(离线运算框架)
1.将数据计算过程分为两个阶段 Map 和 Reduce
*Map将数据进行并行处理
*Reduce将处理结果进行汇总
2.shuffle 连接 Map 和 Reduce 阶段
*Map Task 将数据存储到本地磁盘
*Reduce Task 将数据从 Map Task 上读一份数据
特点:
*仅适合离线数据处理,有极高的容错性和拓展性,适合简单批处理任务
*启动开销大,过多使用磁盘导致效率低下
MapReduce on YRAN
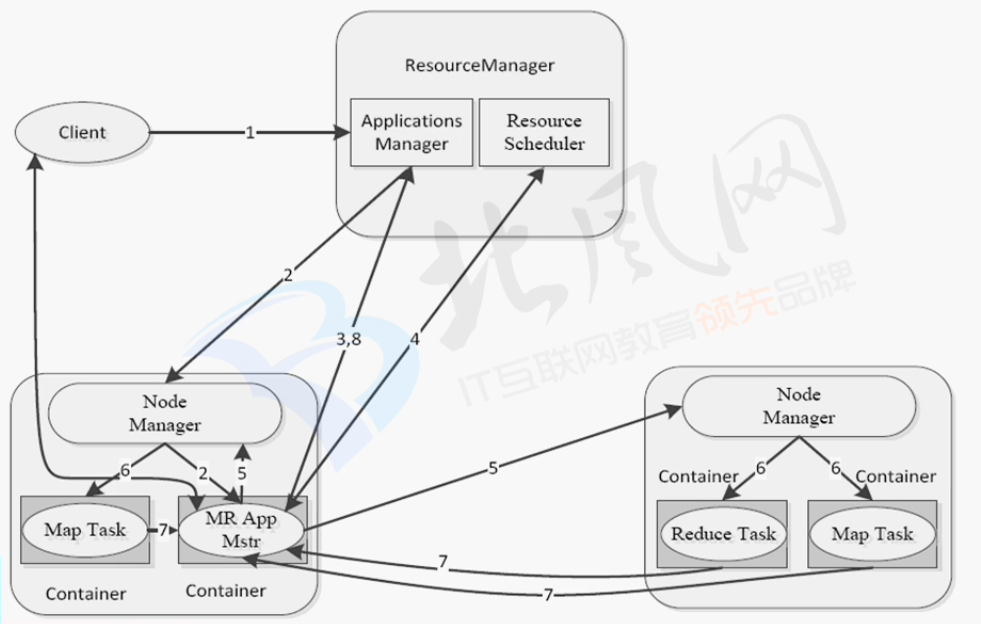
从客户端到客户端中间的过程详解图
注:图片来源见水印,侵删
Hadoop生态系统图解的更多相关文章
- Hadoop概念学习系列之Hadoop 生态系统(十二)
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Hadoop生态系统如何选择搭建
Apache Hadoop项目的目前版本(2.0版)含有以下模块: Hadoop通用模块:支持其他Hadoop模块的通用工具集. Hadoop分布式文件系统(HDFS):支持对应用数据高吞吐量访问的分 ...
- Hadoop 生态系统
1.概述 最近收到一些同学和朋友的邮件,说能不能整理一下 Hadoop 生态圈的相关内容,然后分享一些,我觉得这是一个不错的提议,于是,花了一些业余时间整理了 Hadoop 的生态系统,并将其进行了归 ...
- 从问题域出发认识Hadoop生态系统
近些年来Hadoop生态系统发展迅猛,它本身包含的软件越来越多,同时带动了周边系统的繁荣发展.尤其是在分布式计算这一领域,系统繁多纷杂,时不时冒出一个系统,号称自己比MapReduce或者Hive高效 ...
- hadoop生态系统的详细介绍
1.Hadoop生态系统概况 Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠.高效.可伸缩的特点. Hadoop的核心是HDFS和MapReduce,hadoop2.0还包括YAR ...
- hadoop 之Hadoop生态系统
1.Hadoop生态系统概况 Hadoop是一个能够对大量数据进行分布式处理的软件框架.具有可靠.高效.可伸缩的特点. Hadoop的核心是HDFS和Mapreduce,hadoop2.0还包括YAR ...
- 04_Apache Hadoop 生态系统
内容提纲: 1)对 Apache Hadoop 生态系统的认识(Hadoop 1.x 和 Hadoop 2.x) 2) Apache Hadoop 1.x 框架架构原理的初步认识 3) Apache ...
- Hadoop概念学习系列之Hadoop 生态系统
当下 Hadoop 已经成长为一个庞大的生态体系,只要和海量数据相关的领域,都有 Hadoop 的身影.下图是一个 Hadoop 生态系统的图谱,详细列举了在 Hadoop 这个生态系统中出现的各种数 ...
- Apache Kudu: Hadoop生态系统的新成员实现对快速数据的快速分析
A new addition to the open source Apache Hadoop ecosystem, Apache Kudu completes Hadoop's storage la ...
随机推荐
- ionic2 使用 cordova 打包成安卓apk
准备工作: 1.下载java sdk 配置好java 环境 2.下载android sdk 跟 android studio 并配置好环境 1.查看平台支持,添加android平台 首先命令提示符进入 ...
- SharePoint 无法删除搜索服务应用程序
在SharePoint的使用中,经常会遇到某些服务创建失败,某些服务删除不成功的情况.这里,我们就遇到了搜索服务创建失败,然后删除也不成功,使用管理中心的UI无法删除,PowerShell命令也无法删 ...
- sar使用
http://88fly.blog.163.com/blog/static/1226803902012514710581/
- kafka 0.10.2 消息生产者
package cn.xiaojf.kafka.producer; import org.apache.kafka.clients.producer.KafkaProducer; import org ...
- 在.Net下使用redis基于StackExchange.Redis
研究了下redis在.net下的使用,因为以前在java上用redis用的是jedis操作,在.net不是很熟悉,在网站上也看了一部分的.net下redis的使用,大部分都是ServiceStack. ...
- Android面试题目2
1. 请描述下Activity的声明周期. onCreate->onStart->onRemuse->onPause->onStop->onRestart->onD ...
- php注册登录源代码
php注册登录源代码 链接数据库<?php$conn=mysql_connect('localhost','root','');mysql_select_db('ht',$conn);mysql ...
- SQL SERVER 自动生成 MySQL 表结构及索引 的建表SQL
SQL SERVER的表结构及索引转换为MySQL的表结构及索引,其实在很多第三方工具中有提供,比如navicat.sqlyog等,但是,在处理某些数据类型.默认值及索引转换的时候,总有些 ...
- C# 调用cmd.exe的方法
网上有很多用C#调用cmd的方法,大致如下: [c-sharp] view plaincopy private void ExecuteCmd(string command) { Proces ...
- openvpn配置注意事项
1.安装VPN安装结束后,需要配置CONFIG文件夹服务端及客户端的配置文件,建议从sample文件里直接拷贝修改,网上的一些案例会引起无法启动的问题,没仔细研究过是哪里错了,反正最后从sample里 ...