为什么我们选择parquet
说明:此方案已经我们已经运行1年。
1、场景描述:
我们对客户登录日志做了数据仓库,但实际业务使用中有一些个共同点,
A 需要关联维度表
B 最终仅取某个产品一段时间内的数据
C 只关注其中极少的字段
基于以上业务,我们决定每天定时统一关联维度表,对关联后的数据进行另外存储。各个业务直接使用关联后的数据进行离线计算。
2、择parquet的外部因素
在各种列存储中,我们最终选择parquet的原因有许多。除了parquet自身的优点,还有以下因素
A、公司当时已经上线spark 集群,而spark天然支持parquet,并为其推荐的存储格式(默认存储为parquet)。
B、hive 支持parquet格式存储,如果以后使用hiveql 进行查询,也完全兼容。
3、选择parquet的内在原因
下面通过对比parquet和csv,说说parquet自身都有哪些优势
csv在hdfs上存储的大小与实际文件大小一样。若考虑副本,则为实际文件大小*副本数目。(若没有压缩)
3.1 parquet采用不同压缩方式的压缩比
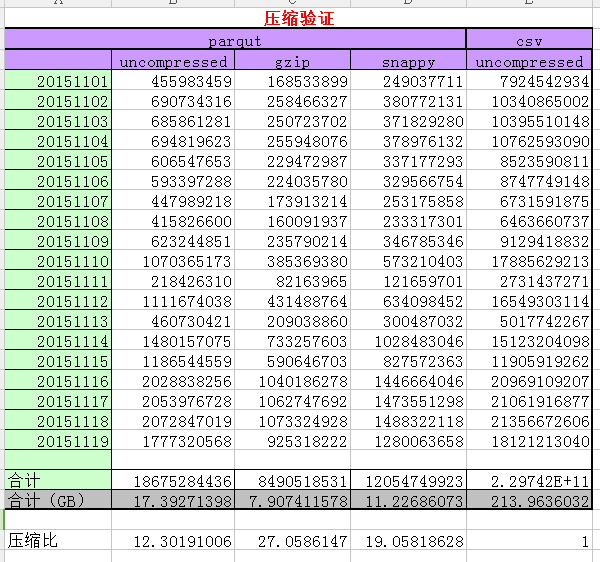
说明:原始日志大小为214G左右,120+字段
采用csv(非压缩模式)几乎没有压缩。
采用parquet 非压缩模式、gzip、snappy格式压缩后分别为17.4G、8.0G、11G,达到的压缩比分别是:12、27、19。
若我们在hdfs上存储3份,压缩比仍达到4、9、6倍
3.2 分区过滤与列修剪
3.2.1分区过滤
parquet结合spark,可以完美的实现支持分区过滤。如,需要某个产品某段时间的数据,则hdfs只取这个文件夹。
spark sql、rdd 等的filter、where关键字均能达到分区过滤的效果。
使用spark的partitionBy 可以实现分区,若传入多个参数,则创建多级分区。第一个字段作为一级分区,第二个字段作为2级分区。。。。。
3.2.2 列修剪
列修剪:其实说简单点就是我们要取回的那些列的数据。
当取得列越少,速度越快。当取所有列的数据时,比如我们的120列数据,这时效率将极低。同时,也就失去了使用parquet的意义。
3.2.3 分区过滤与列修剪测试如下:
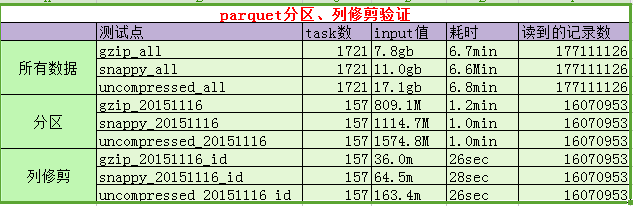
说明:
A、task数、input值、耗时均为spark web ui上的真实数据。
B、之所以没有验证csv进行对比,是因为当200多G,每条记录为120字段时,csv读取一个字段算个count就直接lost excuter了。
C、注意:为避免自动优化,我们直接打印了每条记录每个字段的值。(以上耗时估计有多部分是耗在这里了)
D、通过上图对比可以发现:
- 当我们取出所有记录时,三种压缩方式耗时差别不大。耗时大概7分钟。
- 当我们仅取出某一天时,parquet的分区过滤优势便显示出来。仅为6分之一左右。貌似当时全量为七八天左右吧。
- 当我们仅取某一天的一个字段时,时间将再次缩短。这时,硬盘将只扫描该列所在rowgroup的柱面。大大节省IO。如有兴趣,可以参考深入分析Parquet列式存储格式

E、测试时请开启filterpushdown功能
4、结论
- parquet的gzip的压缩比率最高,若不考虑备份可以达到倍。可能这也是spar parquet默认采用gzip压缩的原因吧。
- 分区过滤和列修剪可以帮助我们大幅节省磁盘IO。以减轻对服务器的压力。
- 如果你的数据字段非常多,但实际应用中,每个业务仅读取其中少量字段,parquet将是一个非常好的选择。
为什么我们选择parquet的更多相关文章
- hadoop入门到实战(6)hive常用优化方法总结
问题导读:1.如何理解列裁剪和分区裁剪?2.sort by代替order by优势在哪里?3.如何调整group by配置?4.如何优化SQL处理join数据倾斜?Hive作为大数据领域常用的数据仓库 ...
- Parquet与ORC:高性能列式存储格式(收藏)
背景 随着大数据时代的到来,越来越多的数据流向了Hadoop生态圈,同时对于能够快速的从TB甚至PB级别的数据中获取有价值的数据对于一个产品和公司来说更加重要,在Hadoop生态圈的快速发展过程中,涌 ...
- 大数据小视角2:ORCFile与Parquet,开源圈背后的生意
上一篇文章聊了聊基于PAX的混合存储结构的RCFile,其实这里笔者还了解一些八卦,RCfile的主力团队都是来自中科院的童鞋在Facebook完成的,算是一个由华人主导的编码项目.但是RCfile仍 ...
- Hive 导入 parquet 格式数据
Hive 导入 parquet 数据步骤如下: 查看 parquet 文件的格式 构造建表语句 倒入数据 一.查看 parquet 内容和结构 下载地址 社区工具 GitHub 地址 命令 查看结构: ...
- 开源列式存储引擎Parquet和ORC
转载自董的博客 相比传统的行式存储引擎,列式存储引擎具有更高的压缩比,更少的IO操作而备受青睐(注:列式存储不是万能高效的,很多场景下行式存储仍更加高效),尤其是在数据列(column)数很多,但每次 ...
- 【kudu pk parquet】runtime filter实践
已经有好一阵子没有写博文了,今天给大家带来一篇最近一段时间开发相关的文章:在impala和kudu上支持runtime filter. 大家搜索下实践者社区,可以发现前面已经有好几位同学写了这个主题的 ...
- Parquet and ORC
http://dongxicheng.org/mapreduce-nextgen/columnar-storage-parquet-and-orc/ 相比传统的行式存储引擎,列式存储引擎具有更高的压缩 ...
- parquet文件格式——本质上是将多个rows作为一个chunk,同一个chunk里每一个单独的column使用列存储格式,这样获取某一row数据时候不需要跨机器获取
Parquet是Twitter贡献给开源社区的一个列数据存储格式,采用和Dremel相同的文件存储算法,支持树形结构存储和基于列的访问.Cloudera Impala也将使用Parquet作为底层的存 ...
- Hive性能调优(一)----文件存储格式及压缩方式选择
合理使用文件存储格式 建表时,尽量使用 orc.parquet 这些列式存储格式,因为列式存储的表,每一列的数据在物理上是存储在一起的,Hive查询时会只遍历需要列数据,大大减少处理的数据量. 采用合 ...
随机推荐
- 《Python核心编程》第五章:数字
PS:[笔记+代码+图片]在GitHub上持续更新,欢迎star:https://github.com/gdouchufu/Core-Python-Programming 本章大纲 介绍Python支 ...
- 七、Mosquito 集群搭建
本章主要讲述Mosquitto 集群搭建的两种方式 1.进行双服务器搭建 2.进行多服务器搭建 一.Mosquitto的分布式集群部署 如果需要做并发量很大的时候就需要考虑做集群处理,但是我在查找资料 ...
- 细说PHP的FPM
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++基础概念++ C ...
- 工作笔记-javascript-网络层封装
/** * @Author Mona * @Date 2016-12-08 * @description 网络层封装 */ /** * 封装基本请求方式 */ window.BaseRequest = ...
- java反射子之获取方法信息(二)
一.获取方法 1.方法作用. 2. 二.获取方法信息.(修饰符,返回值,方法名称,参数列表,抛出的异常). ############################################## ...
- javascript使用百度地图api和html5特性获取浏览器位置
<!DOCTYPE html><html><head> <meta charset="utf-8"> <title>&l ...
- 理解RESTful 架构
REST是所有Web应用都应该遵守的架构设计指导原则. Representational State Transfer,翻译是”表现层状态转化”. 面向资源是REST最明显的特征,对于同一个资源的一组 ...
- C++之条形码,windows下zint库的编译及应用(二)
zint库是一个开源的第三方库,提供了生成条形码.二维码等功能.本文主要介绍zint库的生成及简单应用. 0windows下zint库的编译及应用(一) 工具/原料 vs2012 生成条形 ...
- SQL学习笔记之MySQL中真假“utf8” 问题
0x00 MySQL中UTF8报错 最近我遇到了一个 bug,我试着通过 Rails 在以“utf8”编码的 MariaDB 中保存一个 UTF-8 字符串,然后出现了一个离奇的错误: Incorre ...
- 生产者消费者JAVA实现
三种实现方式: 1. Object对象的wait(),notify(),加synchronize. 2. Lock的await(),signal(). 3. BlockingQueue阻塞队列. Ob ...