elasticsearch 集群的安装部署
一 介绍
elasticsearch 是居于lucene的搜素引擎,可以横向集群扩展以及分片,开发者无需关注如何实现了索引的备份,集群同步,分片等,我们很容易通过简单的配置就可以启动elasticsearch集群,通过提供的基于rest的api实现数据存储以及索引。主要是搭建ELK分布式日志搜集平台以elasticsearch作为日志的存储来研究elasticsearch。
二 参考
http://learnes.net/getting_started/installing_es.html ----》提供了elasticsearch 详细的安装,调用以及集群搭建,集群,分布式的设计思想。
https://www.elastic.co/ -----官网地址
https://github.com/elastic/elasticsearch ---github代码托管地址
三 集群部署
主要通过统一集群名,和通过修改广播地址来实现各个node的自动发现建立集群。
vim ./config/elasticsearch.yml
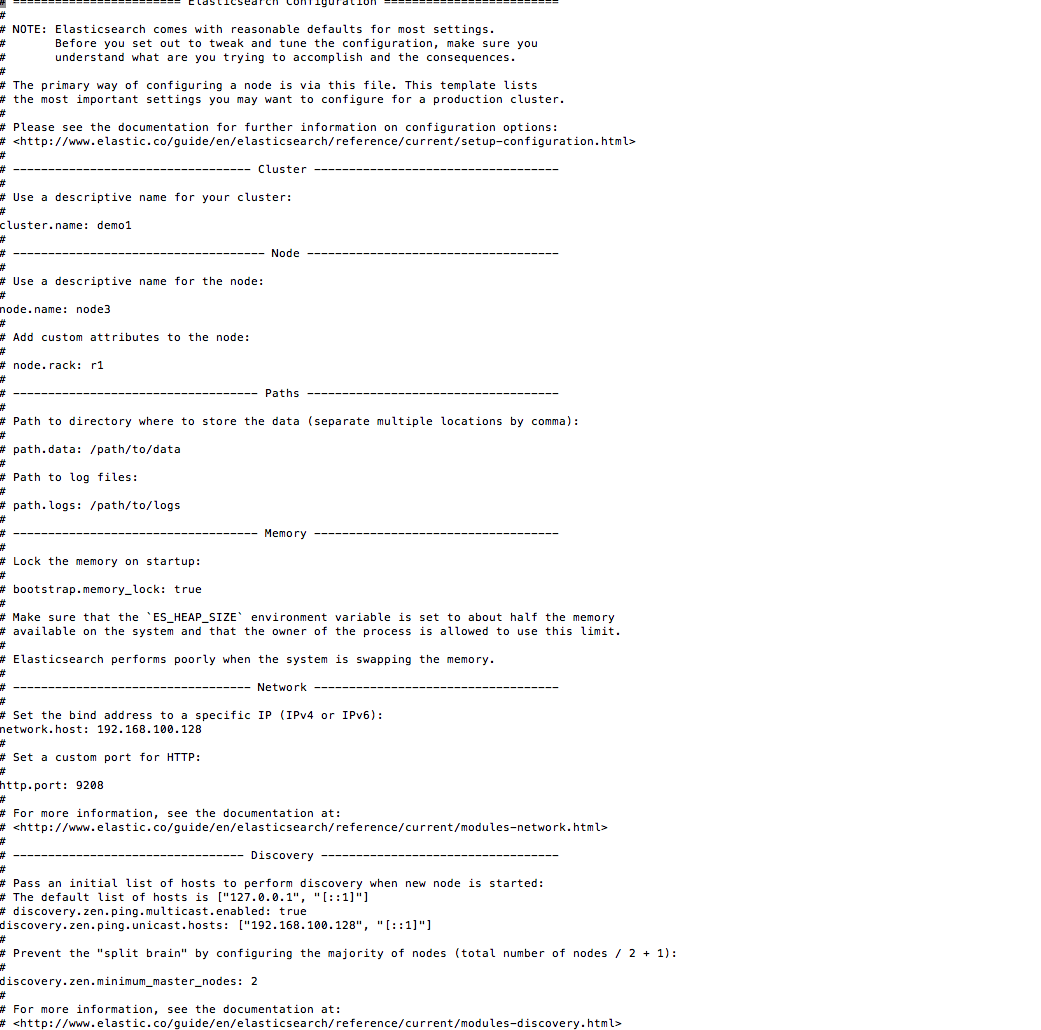
上面的配置文件我们很容易看懂如何修改实现自己想要的配置,这里只要通过修改cluster.name: 指定相同名字。node.name 是节点名字 不一样来区分。
启动
./bin/elasticsearch
六 效果

七 总结
总的来说elasticsearch集群的部署还是很简单的,以上使用elasticsearch-2.4.0-2 通过elasticsearch-head 插件来安装提供基于web ui 可以直观看到集群信息以及索引分片信息以及查询等方便使用。
elasticsearch-head 安装: http://blog.csdn.net/jiuqiyuliang/article/details/51240800
分布式特性:
Elasticsearch 的分布式部分很简单。你甚至不需要关于分布式系统的任何内容,比如分片、集群、发现等成堆的分布式概念。你可能在你的笔记本中运行着刚才的教程,如果你想在一个拥有100个节点的集群中运行教程,你会发现操作是完全一样的。
Elasticsearch 很努力地在避免复杂的分布式系统,很多操作都是自动完成的:
- 可以将你的文档分区到不同容器或者 分片 中,这些文档可能被存在一个节点或者多个节点。
- 跨节点平衡集群中节点间的索引与搜索负载。
- 自动复制你的数据以提供冗余副本,防止硬件错误导致数据丢失。
- 自动在节点之间路由,以帮助你找到你想要的数据。
- 无缝扩展或者恢复你的集群。
故障恢复:
被杀掉的节点是主节点。而为了集群的正常工作必须需要一个主节点,所以首先进行的进程就是从各节点中选择了一个新的主节点:Node 2。
主分片 1 和 2 在我们杀掉 Node 1 后就丢失了,我们的索引在丢失主节点的时候是不能正常工作的。如果我们在这个时候检查集群健康状态,将会显示 red:存在不可用的主节点!
幸运的是,丢失的两个主分片的完整拷贝在存在于其他的节点上,所以新的主节点所完成的第一件事情就是将这些在 Node 2 和 Node 3 上的从分片提升为主分片,然后集群的健康状态就变回至 yellow。这个提升的进程是瞬间完成了,就好像按了一下开关。
那么为什么集群健康状态依然是是 yellow 而不是 green 呢?是因为现在我们有3个主分片,但是我们之前设定了1个主分片有2个从分片,但是现在却只有1份从分片,所以状态无法变为 green,不过我们可以不用太担心这里:当我们再次杀掉 Node 2 的时候,我们的程序依旧可以在没有丢失任何数据的情况下运行,因为 Node 3 中依旧拥有每个分片的备份。
以上摘自: http://learnes.net/distributed_cluster/coping_with_failure.html
elasticsearch 集群的安装部署的更多相关文章
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- (转)linux下weblogic12c集群的安装部署
本文介绍linux下weblogic12c集群的安装部署,版本12c,其他版本操作会有所不同,但其大体操作基本都是一样的 关于weblogic的集群,在此就不多做介绍了,如果有不了解的朋友可以百度搜索 ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(二)——Spark-2.1.0 on Yarn安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS、YARN、MR)安装
虽然我已经装了个Cloudera的CDH集群(教程详见:http://www.cnblogs.com/pojishou/p/6267616.html),但实在太吃内存了,而且给定的组件版本是不可选的, ...
- Istio(二):在Kubernetes(k8s)集群上安装部署istio1.14
目录 一.模块概览 二.系统环境 三.安装istio 3.1 使用 Istioctl 安装 3.2 使用 Istio Operator 安装 3.3 生产部署情况如何? 3.4 平台安装指南 四.Ge ...
- ElasticSearch实战系列一: ElasticSearch集群+Kinaba安装教程
前言 本文主要介绍的是ElasticSearch集群和kinaba的安装教程. ElasticSearch介绍 ElasticSearch是一个基于Lucene的搜索服务器,其实就是对Lucene进行 ...
- Elasticsearch集群架构的部署和调优(一)
[root@es-node1 ~]# mkdir /usr/java[root@es-node1 ~]# tar zxvf jdk1.8.0_131.tar.gz -C /usr/java/ [roo ...
- 分布式实时日志系统(一)环境搭建之 Jstorm 集群搭建过程/Jstorm集群一键安装部署
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
随机推荐
- lamp环境的搭建和安装
最近,部门有些系统需要迁移到新的机器上,因此需要在新的机器上安装lamp和lnmp的环境,因此在这里总结一下: 一. 安装lamp环境的步骤: (1).因为是新的机器,因此需要安装gcc的各种环境: ...
- javascript 类型 内存
ecmscript中包含两种类型 基本类型值 引用类型值(对象) 按值传递和按引用传递 function test ($num) { //按值传递,JavaScript中没有按引用 ...
- 一步一步学EF系列一【最简单的一个实例】
整个文章我都会用最简单,最容易让人理解的方式给大家分享和共同学习.(由于live Writer不靠谱 又得补发一篇) 一.安装 Install-Package EntityFramework 二.简单 ...
- http协议中客户端8种请求方法
http请求中的8种请求方法 1.opions 返回服务器针对特定资源所支持的HTML请求方法 或web服务器发送*测试服务器功能(允许客户端查看服务器性能) 2.Get 向特定资源发出请 ...
- TOSCA自动化测试工具安装
1.下载链接 https://www.tricentis.com/software-testing-tools/ 2.免费试用14天, 弹出的页面输入邮箱地址--> 输入一堆信息-->点击 ...
- centos ssh免密码秘钥登录
假设从A主机ssh登录B主机,用秘钥代替密码,步骤如下: 1.在A主机上执行:ssh-keygen -t rsa 一切默认,不用输入密码,生成两个文件: /root/.ssh/id_rsa /roo ...
- linux 性能测试工具Lmbench
Lmbench是一套简易,可移植的,符合ANSI/C标准为UNIX/POSIX而制定的微型测评工具.一般来说,它衡量两个关键特征:反应时间和带宽.Lmbench旨在使系统开发者深入了解关键操作的基础成 ...
- 20145314郑凯杰 《Java程序设计》第4周学习总结
20145314郑凯杰 <Java程序设计>第4周学习总结 所有代码已上传: 教材学习内容总结 ①继承 设计程序中,因们需要设计多个模块,我想到了李晓东以前教我们的三个字"模块化 ...
- IO多路复用客户端-服务器模型
IO多路复用服务器 -- 实现字符回射 服务器端 /************************************************************************* ...
- uboot下ext4ls的用法
列出sd卡的第一个分区里/bin目录下的内容,示例如下: ext4ls mmc 0:1 /bin