深度学习基础系列(二)| 常见的Top-1和Top-5有什么区别?
在深度学习过程中,会经常看见各成熟网络模型在ImageNet上的Top-1准确率和Top-5准确率的介绍,如下图所示:
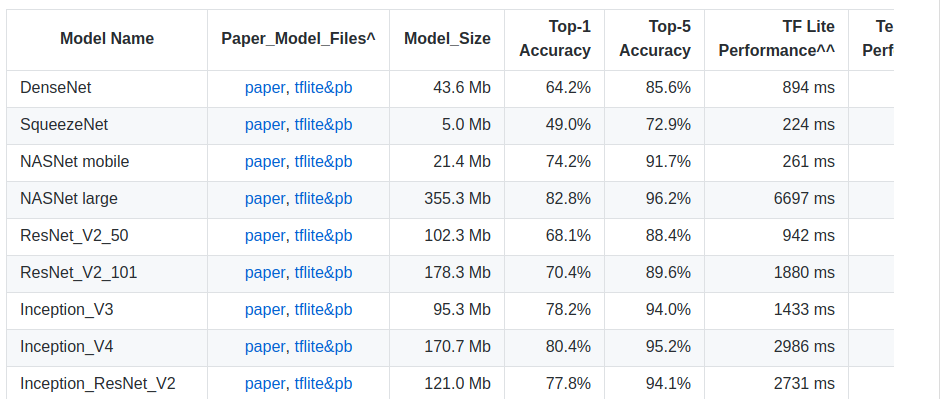
那Top-1 Accuracy和Top-5 Accuracy是指什么呢?区别在哪呢?我们知道ImageNet有大概1000个分类,而模型预测某张图片时,会给出1000个按概率从高到低的类别排名,
所谓的Top-1 Accuracy是指排名第一的类别与实际结果相符的准确率,
而Top-5 Accuracy是指排名前五的类别包含实际结果的准确率。
下面的代码可更为直观地说明其中的区别:
import numpy as np
import tensorflow.keras.backend as K # 随机输出数字0~9的概率分布
output = K.random_uniform_variable(shape=(1, 10), low=0, high=1)
# 实际结果假设为数字1
actual_pos = K.variable(np.array([1]), dtype='int32')
print("数字0~9的预测概率分布为:", K.eval(output))
print("实际结果为数字:", K.eval(actual_pos))
print("实际结果是否in top 1: ", K.eval(K.in_top_k(output, actual_pos, 1)))
print("实际结果是否in top 5: ", K.eval(K.in_top_k(output, actual_pos, 5)))
运行后再看看结果为:
数字0~9的预测概率分布为: [[0.301023 0.8182187 0.71007144 0.80164504 0.7268218 0.58599055 0.19250274 0.9076816 0.8101771 0.49439466]]
实际结果为数字: [1]
实际结果是否in top 1: [False]
实际结果是否in top 5: [ True]
从结果上看,output中排名最高的值为0.9076816,其对应的数字为7,而实际数字为1,故不在Top1,而数字1对应的值为0.8182187,排名第二,故在Top5内。
深度学习基础系列(二)| 常见的Top-1和Top-5有什么区别?的更多相关文章
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(十一)| Keras中图像增强技术详解
在深度学习中,数据短缺是我们经常面临的一个问题,虽然现在有不少公开数据集,但跟大公司掌握的海量数据集相比,数量上仍然偏少,而某些特定领域的数据采集更是非常困难.根据之前的学习可知,数据量少带来的最直接 ...
- 深度学习基础系列(七)| Batch Normalization
Batch Normalization(批量标准化,简称BN)是近些年来深度学习优化中一个重要的手段.BN能带来如下优点: 加速训练过程: 可以使用较大的学习率: 允许在深层网络中使用sigmoid这 ...
- 深度学习基础系列(四)| 理解softmax函数
深度学习最终目的表现为解决分类或回归问题.在现实应用中,输出层我们大多采用softmax或sigmoid函数来输出分类概率值,其中二元分类可以应用sigmoid函数. 而在多元分类的问题中,我们默认采 ...
- 深度学习基础(二)AlexNet_ImageNet Classification with Deep Convolutional Neural Networks
该论文是深度学习领域的经典之作,因为自从Alex Krizhevsky提出AlexNet并使用GPUs大幅提升训练的效率之后,深度学习在图像识别等领域掀起了研究使用的热潮.在论文中,作者训练了一个含有 ...
- 深度学习基础系列(十)| Global Average Pooling是否可以替代全连接层?
Global Average Pooling(简称GAP,全局池化层)技术最早提出是在这篇论文(第3.2节)中,被认为是可以替代全连接层的一种新技术.在keras发布的经典模型中,可以看到不少模型甚至 ...
- 深度学习基础系列(三)| sigmoid、tanh和relu激活函数的直观解释
常见的激活函数有sigmoid.tanh和relu三种非线性函数,其数学表达式分别为: sigmoid: y = 1/(1 + e-x) tanh: y = (ex - e-x)/(ex + e-x) ...
- 深度学习基础系列(一)| 一文看懂用kersa构建模型的各层含义(掌握输出尺寸和可训练参数数量的计算方法)
我们在学习成熟网络模型时,如VGG.Inception.Resnet等,往往面临的第一个问题便是这些模型的各层参数是如何设置的呢?另外,我们如果要设计自己的网路模型时,又该如何设置各层参数呢?如果模型 ...
随机推荐
- JQ笔记-加强版
Query初级 一.介绍.基本写法 什么是JQ: 一个优秀的JS库,大型开发必备 JQ的好处: 简化JS的复杂操作 不再需要关心兼容性 提供大量实用方法 如何学习JQ: www.jquery. ...
- 【BZOJ】2120: 数颜色 带修改的莫队算法
[题意]给定n个数字,m次操作,每次询问区间不同数字的个数,或修改某个位置的数字.n,m<=10^4,ai<=10^6. [算法]带修改的莫队算法 [题解]对于询问(x,y,t),其中t是 ...
- C语言与汇编语言对照分析
游戏通常会包含各种各样的功能,如战斗系统.UI渲染.经济系统.生产系统等,每个系统又包含各式各样子功能,如伤害判定.施法.使用道具.角色移动.玩家之间交易等等.这些游戏功能在代码实现中往往少不了条件判 ...
- 安装Docker-ce
Docker Engine改为Docker CE(社区版) 它包含了CLI客户端.后台进程/服务以及API.用户像以前以同样的方式获取.Docker Data Center改为Docker EE(企业 ...
- 美团实习Java岗面经,已拿offer
作者:icysnowgx 链接:https://www.nowcoder.com/discuss/71954?type=2&order=3&pos=10&page=1 来源:牛 ...
- c++中指针常量,常指针,指向常量的常指针区分
const char * myPtr = &char_A;//指向常量的指针 char * const myPtr = &char_A;//常量的指针 const char * con ...
- (转)USB 基本知识
USB的重要关键字: 1.端点:位于USB设备或主机上的一个数据缓冲区,用来存放和发送USB的各种数据,每一个端点都有惟一的确定地址,有不同的传输特性(如输入端点.输出端点.配置端点.批量传输端点) ...
- linux 实现自动创建ftp用户并创建文件夹
创建一个 createuser.sh的脚本文件 #!/bin/sh #传入的文件名 name=$1 #创建该用户所对应的ftp文件夹 /srv/ftp是我的ftp服务器的根目录 mkdir /sr ...
- ASP.NET Core 2.0 MVC 发布部署--------- SUSE 16 Linux Enterprise Server 12 SP2 X64 具体操作
.Net Core 部署到 SUSE 16 Linux Enterprise Server 12 SP2 64 位中的步骤 1.安装工具 1.apache 2..Net Core(dotnet-sdk ...
- JavaScript基础练习(一)
加法的案例改为 可以做加减乘除.求余五种运算 为抵抗洪水,战士连续作战89小时,编程计算共多少天零多少小时? (function(a){ alert("战士连续作战"+parseI ...