HBase存储架构
以下的介绍是基于Apache Hbase 0.94版本:
从HBase的架构图上可以看出,HBase中的存储包括HMaster、HRegionServer、HRegion、Store、MemStore、StoreFile、HFile、HLog等,本篇文章统一介绍他们的作用即存储结构。
以下是HBase存储架构图:

HBase中的每张表都通过行键按照一定的范围被分割成多个子表(HRegion),默认一个HRegion超过256M就要被分割成两个,这个过程由HRegionServer管理,而HRegion的分配由HMaster管理。
HMaster的作用:
- 为Region server分配region
- 负责Region server的负载均衡
- 发现失效的Region server并重新分配其上的region
- HDFS上的垃圾文件回收
- 处理schema更新请求
HRegionServer作用:
- 维护master分配给他的region,处理对这些region的io请求
- 负责切分正在运行过程中变的过大的region
可以看到,client访问hbase上的数据并不需要master参与(寻址访问zookeeper和region server,数据读写访问region server),master仅仅维护table和region的元数据信息(table的元数据信息保存在zookeeper上),负载很低。
HRegionServer存取一个子表时,会创建一个HRegion对象,然后对表的每个列族创建一个Store实例,每个Store都会有一个MemStore和0个或多个StoreFile与之对应,每个StoreFile都会对应一个HFile, HFile就是实际的存储文件。因此,一个HRegion有多少个列族就有多少个Store。
一个HRegionServer会有多个HRegion和一个HLog。
HRegion
table在行的方向上分隔为多个Region。Region是HBase中分布式存储和负载均衡的最小单元,即不同的region可以分别在不同的Region Server上,但同一个Region是不会拆分到多个server上。
Region按大小分隔,每个表一行是只有一个region。随着数据不断插入表,region不断增大,当region的某个列族达到一个阈值(默认256M)时就会分成两个新的region。
每个region由以下信息标识:
- <表名,startRowkey,创建时间>
- 由目录表(-ROOT-和.META.)可值该region的endRowkey
HRegion定位:
Region被分配给哪个Region Server是完全动态的,所以需要机制来定位Region具体在哪个region server。
HBase使用三层结构来定位region:
- 1、 通过zk里的文件/hbase/rs得到-ROOT-表的位置。-ROOT-表只有一个region。
- 2、通过-ROOT-表查找.META.表的第一个表中相应的region的位置。其实-ROOT-表是.META.表的第一个region;.META.表中的每一个region在-ROOT-表中都是一行记录。
- 3、通过.META.表找到所要的用户表region的位置。用户表中的每个region在.META.表中都是一行记录。
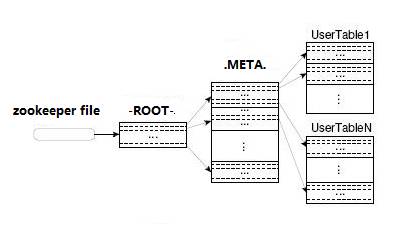
-ROOT-表永远不会被分隔为多个region,保证了最多需要三次跳转,就能定位到任意的region。client会将查询的位置信息保存缓存起来,缓存不会主动失效,因此如果client上的缓存全部失效,则需要进行6次网络来回,才能定位到正确的region,其中三次用来发现缓存失效,另外三次用来获取位置信息。
Store
每一个region有一个或多个store组成,至少是一个store,hbase会把一起访问的数据放在一个store里面,即为每个ColumnFamily建一个store,如果有几个ColumnFamily,也就有几个Store。一个Store由一个memStore和0或者多个StoreFile组成。
HBase以store的大小来判断是否需要切分region。
MemStore
memStore 是放在内存里的。保存修改的数据即keyValues。当memStore的大小达到一个阀值(默认64MB)时,memStore会被flush到文件,即生成一个快照。目前hbase 会有一个线程来负责memStore的flush操作。
StoreFile
memStore内存中的数据写到文件后就是StoreFile,StoreFile底层是以HFile的格式保存。
HFile
HBase中KeyValue数据的存储格式,是hadoop的二进制格式文件。
首先HFile文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。Trailer中又指针指向其他数据块的起始点,FileInfo记录了文件的一些meta信息。
Data Block是hbase io的基本单元,为了提高效率,HRegionServer中又基于LRU的block cache机制。每个Data块的大小可以在创建一个Table的时候通过参数指定(默认块大小64KB),大号的Block有利于顺序Scan,小号的Block利于随机查询。每个Data块除了开头的Magic以外就是一个个KeyValue对拼接而成,Magic内容就是一些随机数字,目的是烦着数据损坏,结构如下。

HFile结构图如下:

Data Block段用来保存表中的数据,这部分可以被压缩。
Meta Block段(可选的)用来保存用户自定义的kv段,可以被压缩。
FileInfo段用来保存HFile的元信息,本能被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index段(可选的)用来保存Meta Blcok的索引。
Trailer这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。目标HFile的压缩支持两种方式:gzip、lzo。

另外,针对目前针对现有HFile的两个主要缺陷:
- a) 暂用过多内存
- b) 启动加载时间缓慢
提出了HFile Version2设计:https://issues.apache.org/jira/secure/attachment/12478329/hfile_format_v2_design_draft_0.1.pdf
HLog
其实HLog文件就是一个普通的Hadoop Sequence File, Sequence File的value是key时HLogKey对象,其中记录了写入数据的归属信息,除了table和region名字外,还同时包括sequence number和timestamp,timestamp是写入时间,sequence number的起始值为0,或者是最近一次存入文件系统中的sequence number。
Sequence File的value是HBase的KeyValue对象,即对应HFile中的KeyValue。

HLog(WAL log):WAL意为write ahead log,用来做灾难恢复使用,HLog记录数据的所有变更,一旦region server 宕机,就可以从log中进行恢复。

LogFlusher
前面提到,数据以KeyValue形式到达HRegionServer,将写入WAL,之后,写入一个SequenceFile。看过去没问题,但是因为数据流在写入文件系统时,经常会缓存以提高性能。这样,有些本以为在日志文件中的数据实际在内存中。这里,我们提供了一个LogFlusher的类。它调用HLog.optionalSync(),后者根据hbase.regionserver.optionallogflushinterval (默认是10秒),定期调用Hlog.sync()。另外,HLog.doWrite()也会根据 hbase.regionserver.flushlogentries (默认100秒)定期调用Hlog.sync()。Sync() 本身调用HLog.Writer.sync(),它由SequenceFileLogWriter实现。
LogRoller
Log的大小通过$HBASE_HOME/conf/hbase-site.xml 的 hbase.regionserver.logroll.period 限制,默认是一个小时。所以每60分钟,会打开一个新的log文件。久而久之,会有一大堆的文件需要维护。首先,LogRoller调用HLog.rollWriter(),定时滚动日志,之后,利用HLog.cleanOldLogs()可以清除旧的日志。它首先取得存储文件中的最大的sequence number,之后检查是否存在一个log所有的条目的“sequence number”均低于这个值,如果存在,将删除这个log。
每个region server维护一个HLog,而不是每一个region一个,这样不同region(来自不同的table)的日志会混在一起,这样做的目的是不断追加单个文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高table的写性能。带来麻烦的时,如果一个region server下线,为了恢复其上的region,需要讲region server上的log进行拆分,然后分发到其他region server上进行恢复。
HBase存储架构的更多相关文章
- 23 HBase 存储架构。
个 Region,Region会下线,新Split出的2个子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上由此过程 ...
- HBase系统架构及数据结构(转)
原文链接:Hbase系统架构及数据结构 HBase中的表一般有这样的特点: 1 大:一个表可以有上亿行,上百万列 2 面向列:面向列(族)的存储和权限控制,列(族)独立检索. 3 稀疏:对于为空(nu ...
- 列式存储hbase系统架构学习
一.Hbase简介 HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现的编程语言为 Java.它是Apache软件基金会的Hadoop项目的一部分,运行 ...
- Hbase系统架构
HBase 系统架构 HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列 ...
- HBase 系统架构
HBase是Apache Hadoop的数据库,能够对大型数据提供随机.实时的读写访问.HBase的目标是存储并处理大型的数据.HBase是一个开源的,分布式的,多版本的,面向列的存储模型.它存储的是 ...
- Hbase的架构原理、核心概念
Hbase的架构原理.核心概念 1.Hbase的表.行.列.列族 2.核心组件: Table和region Table在行的方向上分割为多个HRegion, 一个region由[startkey,en ...
- HBase存储剖析与数据迁移
1.概述 HBase的存储结构和关系型数据库不一样,HBase面向半结构化数据进行存储.所以,对于结构化的SQL语言查询,HBase自身并没有接口支持.在大数据应用中,虽然也有SQL查询引擎可以查询H ...
- HBase体系架构和集群安装
大家好,今天分享的是HBase体系架构和HBase集群安装.承接上两篇文章<HBase简介>和<HBase数据模型>,点击回顾这2篇文章,有助于更好地理解本文. 一.HBase ...
- Hbase 系统架构(zhuan)
一.系统架构 客户端连接hbase依赖于zookeeper,hbase存储依赖于hadoop client: 1.包含访问 hbase 的接口, client 维护着一些 cache(缓存) 来加快对 ...
随机推荐
- ImportError: No module named mysql 报错python引用mysql报错
需要安装 pip2.7 install MySQL-python pip2.7 install mysql-connector
- TF Boys (TensorFlow Boys ) 养成记(三): TensorFlow 变量共享
上次说到了 TensorFlow 从文件读取数据,这次我们来谈一谈变量共享的问题. 为什么要共享变量?我举个简单的例子:例如,当我们研究生成对抗网络GAN的时候,判别器的任务是,如果接收到的是生成器生 ...
- High-level NavMesh Building Components
Here we introduce four high level components for the navigation system: //这里我们介绍四个高水平导航系统组件: NavMesh ...
- Java并发编程从入门到精通 张振华.Jack --我的书
[当当.京东.天猫.亚马逊.新华书店等均有销售] 目 录 第一部分:线程并发基础 第1章 概念部分 1 1.1 CPU核心数.线程数 (主流cpu.线程数的大体情况说一下) 1 1.2 CPU时间 ...
- hdu 1348:Wall(计算几何,求凸包周长)
Wall Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submis ...
- VC++ 创建自己的头文件包含GUID
Guidgen 是比较好用的工具之一,可以使用它来创建ActiveX控件的UUID,同时可以创建独特的剪贴板格式名称和唯一的标识符的内核对象, 如信号量.互斥和事件. 但我需要为另一个目的创建一个唯 ...
- LAMP环境搭建博客
背景: 公司要用到lamp环境,让我装,我就开始着手找资料,一般分为源码装和yum装,源码装很容易出错,所以我选择了yum装,. 服务器:aliyun服务器 centos6.8系统 按照第一个安装完 ...
- Hibernate_day02--课程安排_主键生成策略_对实体类crud操作_实体类对象状态
Hibernate_day02 上节内容 今天内容 实体类编写规则 Hibernate主键生成策略 实体类操作 对实体类crud操作 添加操作 根据id查询 修改操作 删除操作 实体类对象状态(概念) ...
- Lua中 MinXmlHttpRequest如何发送post方式数据
local xhr=cc.XMLHttpRequest:new() xhr.responseType=cc.XMLHTTPREQUEST_RESPONSE_JSON xhr:open(“POST”,& ...
- C++编译遇到参数错误(cannot convert parameter * from 'const char [**]' to 'LPCWSTR')
转:http://blog.sina.com.cn/s/blog_9ffcd5dc01014nw9.html 前面的几天一直都在复习着被实习落下的C++基础知识.今天在复习着上次创建的窗口程序时,出现 ...