JVM学习十:JVM之垃圾收集器及GC参数
接近两个月左右没有写博客,主要是因为小孩过来后,回家比较忙,现在小孩端午送回家了,开始继续之前的JVM学习之路,前面学习了GC的算法和种类,那么本章则是基于算法来产生实际的用途,即垃圾收集器。
一、堆的回顾
新生代中的98%对象都是“朝生夕死”的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块比较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是说,每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的空间会被浪费。
当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖于老年代进行分配担保,所以大对象直接进入老年代。
堆的结构如下图所示:

垃圾收集器:
如果说收集算法时内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
虽然我们在对各种收集器进行比较,但并非为了挑出一个最好的收集器。因为直到现在位置还没有最好的收集器出现,更加没有万能的收集器,所以我们选择的只是对具体应用最合适的收集器。
二、串行收集器:Serial收集器
- 最古老,最稳定
- 简单而高效
- 可能会产生较长的停顿
- -XX:+UseSerialGC
新生代、老年代都会使用串行回收
新生代复制算法
老年代标记-整理
总结:Serial收集器对于运行在Client模式下的虚拟机来说是一个很好的选择。
这个收集器是一个单线程的收集器,但它的单线程的意义并不仅仅说明它只会使用一个CPU或一条收集线程去完成垃圾收集工作,更重要的是在它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。收集器的运行过程如下图所示:
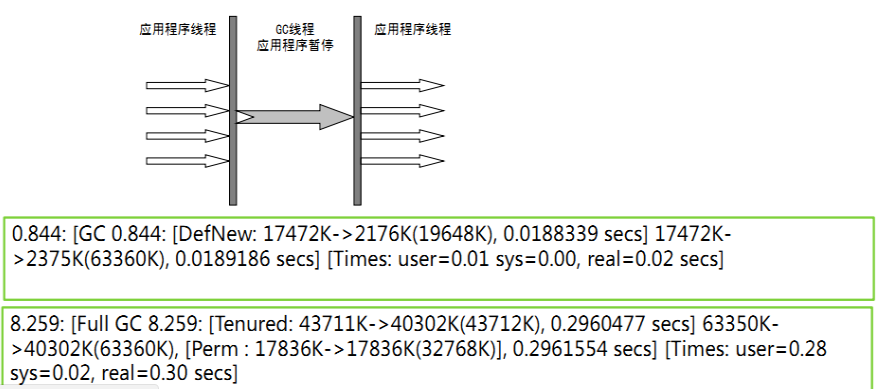
三、并行收集器
1、ParNew收集器:
- ParNew收集器其实就是Serial收集器新生代的并行版本。
- 多线程,需要多核支持。
- -XX:+UseParNewGC
新生代并行
老年代串行
- -XX:ParallelGCThreads 限制线程数量
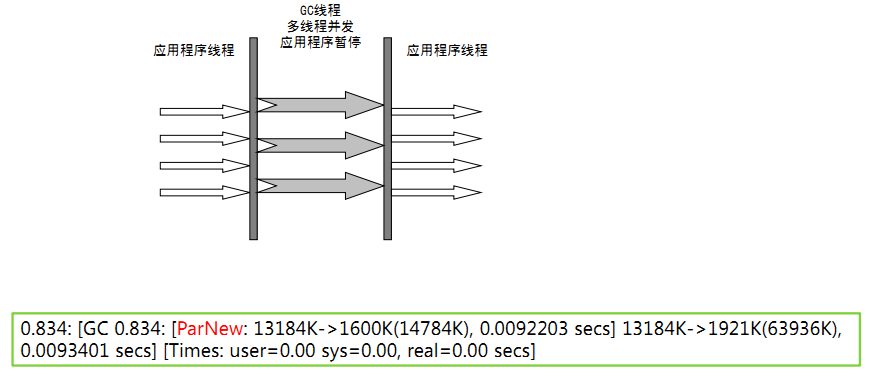
2、Parallel Scanvenge收集器:
- 类似ParNew,但更加关注吞吐量
- -XX:+UseParallelGC 使用Parallel Scanvenge收集器:新生代并行,老年代串行
3、Parallel Old收集器:
- Parallel Old收集器是Parallel Scanvenge收集器的老年代版本
- -XX:+UseParallelGC 使用Parallel Old收集器:新生代并行,老年代并行
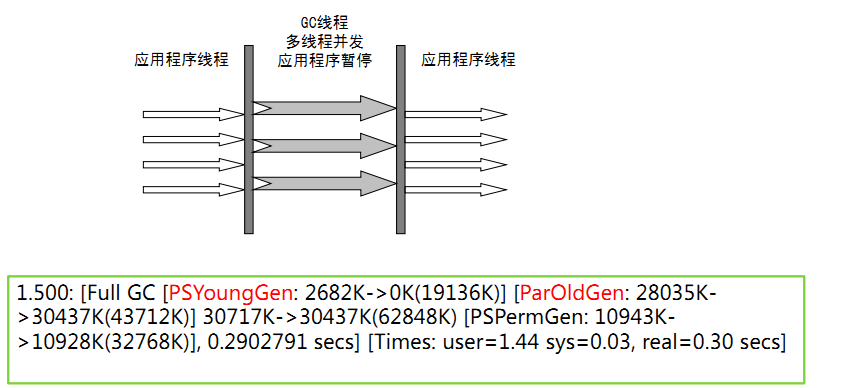
各种参数设置:
- -XX:MaxGCPauseMills
最大停顿时间,单位毫秒
GC尽力保证回收时间不超过设定值
- -XX:GCTimeRatio
0-100的取值范围
垃圾收集时间占总时间的比
默认99,即最大允许1%时间做GC
注:这两个参数是矛盾的。因为停顿时间和吞吐量不可能同时调优。我们一方买希望停顿时间少,另外一方面希望吞吐量高,其实这是矛盾的。因为:在GC的时候,垃圾回收的工作总量是不变的,如果将停顿时间减少,那频率就会提高;既然频率提高了,说明就会频繁的进行GC,那吞吐量就会减少,性能就会降低。
吞吐量:CPU用于用户代码的时间/CPU总消耗时间的比值,即=运行用户代码的时间/(运行用户代码时间+垃圾收集时间)。比如,虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%。
注2:以上所有的收集器当中,当执行GC时,都会stop the world,但是下面的CMS收集器却不会这样。
四、CMS收集器
CMS收集器(Concurrent Mark Sweep:并发标记清除)是一种以获取最短回收停顿时间为目标的收集器。适合应用在互联网站或者B/S系统的服务器上,这类应用尤其重视服务器的响应速度,希望系统停顿时间最短。
- Concurrent Mark Sweep 并发标记清除,并发低停顿
- 标记-清除算法
- 并发阶段会降低吞吐量(因为停顿时间减少了,于是GC的频率会变高)
- 老年代收集器(新生代使用ParNew)
- -XX:+UseConcMarkSweepGC 打开这收集器
注:这里的并发指的是与用户线程一起执行。
2、CMS收集器运行过程:(着重实现了标记的过程)
(1)初始标记
根可以直接关联到的对象
速度快
(2)并发标记(和用户线程一起)
主要标记过程,标记全部对象
(3)重新标记
由于并发标记时,用户线程依然运行,因此在正式清理前,再做修正
(4)并发清除(和用户线程一起)
基于标记结果,直接清理对象
整个过程如下图所示:
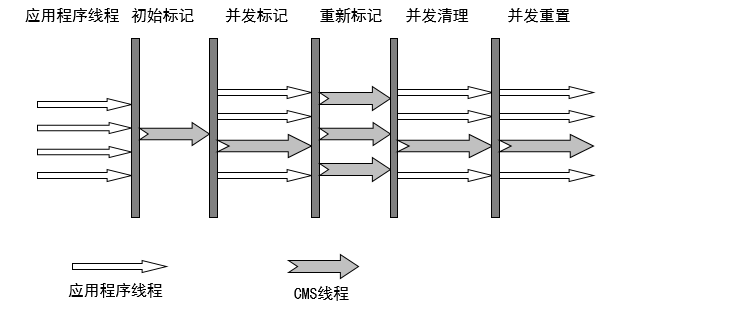
其中,初始标记和重新标记时,需要stop the world。
整个过程中耗时最长的是并发标记和并发清除,这两个过程都可以和用户线程一起工作。
打印GC日志举例如下:
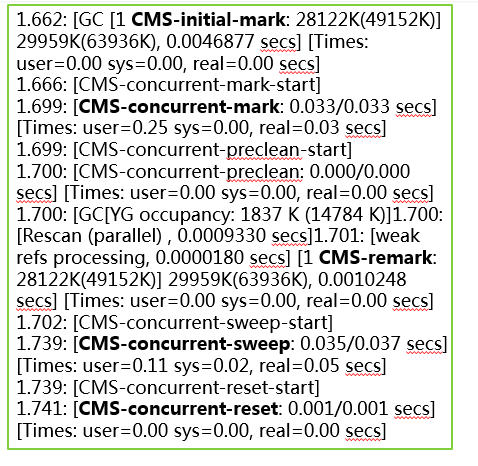
3、CMS收集器特点:
(1)尽可能降低停顿
(2)会影响系统整体吞吐量和性能
比如,在用户线程运行过程中,分一半CPU去做GC,系统性能在GC阶段,反应速度就下降一半
(3)清理不彻底
因为在清理阶段,用户线程还在运行,会产生新的垃圾,无法清理
(4)因为和用户线程一起运行,不能在空间快满时再清理
-XX:CMSInitiatingOccupancyFraction设置触发GC的阈值
如果不幸内存预留空间不够,就会引起concurrent mode failure
我们来看一下concurrent mode failure的日志:

碰到上图中的情况,我们需要使用串行收集器作为后备。
4、既然标记清除算法会造成内存空间的碎片化,CMS收集器为什么使用标记清除算法而不是使用标记整理算法:
答案:
CMS收集器更加关注停顿,它在做GC的时候是和用户线程一起工作的(并发执行),如果使用标记整理算法的话,那么在清理的时候就会去移动可用对象的内存空间,那么应用程序的线程就很有可能找不到应用对象在哪里。
为了解决碎片的问题,CMS收集器会有一些整理上的参数,接下来就来讲这个。
5、整理时的各种参数:
- -XX:+ UseCMSCompactAtFullCollection
Full GC后,进行一次整理。整理过程是独占的,会引起停顿时间变长
- -XX:+CMSFullGCsBeforeCompaction
设置进行几次Full GC后,进行一次碎片整理
- -XX:ParallelCMSThreads
设定CMS的线程数量
五、GC参数
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:SurvivorRatio:设置eden区大小和survivior区大小的比例
-XX:NewRatio:新生代和老年代的比
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :新生代使用并行回收收集器
-XX:+UseParallelOldGC:老年代使用并行回收收集器
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS+串行收集器
-XX:ParallelCMSThreads:设定CMS的线程数量
-XX:CMSInitiatingOccupancyFraction:设置CMS收集器在老年代空间被使用多少后触发
-XX:+UseCMSCompactAtFullCollection:设置CMS收集器在完成垃圾收集后是否要进行一次内存碎片的整理
-XX:CMSFullGCsBeforeCompaction:设定进行多少次CMS垃圾回收后,进行一次内存压缩
-XX:+CMSClassUnloadingEnabled:允许对类元数据进行回收
-XX:CMSInitiatingPermOccupancyFraction:当永久区占用率达到这一百分比时,启动CMS回收
-XX:UseCMSInitiatingOccupancyOnly:表示只在到达阀值的时候,才进行CMS回收
为了减轻GC压力,我们需要注意些什么?
- 软件如何设计架构(性能的根本在应用)
- GC参数属于微调(设置不合理会影响性能,产生大的延时)
- 堆空间如何管理和分配
- 代码如何写
参考资料:
《深入JVM内核原理诊断与优化》视频学习
http://www.cnblogs.com/smyhvae
JVM学习十:JVM之垃圾收集器及GC参数的更多相关文章
- JVM学习三:JVM之垃圾收集器及GC参数
一.堆的回顾 新生代中的98%对象都是"朝生夕死"的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块比较大的Eden空间和两块较小的Survivor空间,每次使用E ...
- JVM学习笔记三:垃圾收集器与内存分配策略
内存回收与分配重点关注的是堆内存和方法区内存(程序计数器占用小,虚拟机栈和本地方法栈随线程有相同的生命周期). 一.判断对象是否存活? 1. 引用计数算法 优势:实现简单,效率高. 致命缺陷:无法解决 ...
- 【JVM学习笔记二】垃圾收集器与内存分配策略
1. 概述 1) GC的历史比Java久远 2) GC需要完成的三件事: | 哪些内存需要回收 | 什么时候回收 | 如何回收 3) Java内存运行时区域各个部分: | Java虚拟机栈.计数器.本 ...
- JVM学习笔记三:垃圾收集器及内存管理策略
垃圾收集器 上文说到了垃圾收集算法,这次我们聊一下HotSpot的具体垃圾收集器的实现,以JDK1.7为例,其包含的可选垃圾收集器如下图: 不同收集器之间的连线,代表它们可以搭配使用,收集器所属的区域 ...
- java虚拟机学习-JVM内存管理:深入垃圾收集器与内存分配策略(4)
Java与C++之间有一堵由内存动态分配和垃圾收集技术所围成的高墙,墙外面的人想进去,墙里面的人却想出来. 概述: 说起垃圾收集(Garbage Collection,下文简称GC),大部分人都把这项 ...
- JVM性能优化系列-(2) 垃圾收集器与内存分配策略
2. 垃圾收集器与内存分配策略 垃圾收集(Garbage Collection, GC)是JVM实现里非常重要的一环,JVM成熟的内存动态分配与回收技术使Java(当然还有其他运行在JVM上的语言,如 ...
- GC垃圾回收 | 深入理解G1垃圾收集器和GC日志
来源:并发编程网链接:http://ifeve.com/深入理解G1垃圾收集器/ G1 GC是Jdk7的新特性之一.Jdk7+版本都可以自主配置G1作为JVM GC选项:作为JVM GC算法的一次重大 ...
- JVM学习十 -(复习)内存分配与回收策略
内存分配与回收策略 对象的内存分配,就是在堆上分配(也可能经过 JIT 编译后被拆散为标量类型并间接在栈上分配),对象主要分配在新生代的 Eden 区上,少数情况下可能直接分配在老年代,分配规则不固定 ...
- 查看JVM使用的默认的垃圾收集器
一.查看步骤 cmd执行命令: java -XX:+PrintCommandLineFlags -version 输出如下(举例): 针对上述的-XX:UseParallelGC,这边我们引用< ...
随机推荐
- 今目标登录时报网络错误E110
今目标登录的时候报错了,错误代码:E110不论怎么修改都修复不了,百度相关资料也没有,只能联系客服. 经过好久终于联系上了客服,客服给出的解决方案是修改:Enternet选项: 第一步:打开,控制面板 ...
- this & super
/* 当本类的成员和局部变量同名用this区分. 当子父类中的成员变量同名用super区分父类. this和super的用法很相似. this:代表一个本类对象的引用. super:代表一个父 ...
- PAT 甲级 1043 Is It a Binary Search Tree
https://pintia.cn/problem-sets/994805342720868352/problems/994805440976633856 A Binary Search Tree ( ...
- php判断是否https
function is_https() { if ( !empty($_SERVER['HTTPS']) && strtolower($_SERVER['HTTPS']) !== 'o ...
- python3.6 SSL module is not available
pip is configured with locations that require TLS/SSL, however the ssl module in Python is not avail ...
- webgl学习笔记三-平移旋转缩放
写在前面 建议先阅读下前面我的两篇文章. webgl学习笔记一-绘图单点 webgl学习笔记二-绘图多点 平移 1.关键点说明 顶点着色器需要加上 uniform vec4 u_Translation ...
- SQL中的逻辑运算符
逻辑运算符和比较运算符一样,都是返回 true 或 false 值得布尔数据类型. 运算符 行为 ALL 如果一个比较集中全部都是 true ,则值为 true AND 如果两个布尔值表达式均为 ...
- 第165天:canvas绘制圆环旋转动画
canvas绘制圆环旋转动画——面向对象版 1.HTML 注意引入Konva.js库 <!DOCTYPE html> <html lang="en"> &l ...
- hdu mophues
在比赛的时候,被这个题目虐死了,这一周中每当我有空闲时间我就总是思索这个题目的解题方法. 终于在自己学过了mobius反演,并且看过别人写得解题思路后自己有了思路. 下面说说我的解题思路吧. 首先题目 ...
- MySQL二进制安装部署
#使用二进制包安装mysql -linux-glibc2.-x86_64.tar.gz /data/ -linux-glibc2.-x86_64.tar.gz -C /data/ -linux-gli ...