ConcurrentHashMap的使用和原理
呵呵呵,原理nmb。
HashTable,HashMap,ConcurrentHashMap
当你作为一个菜鸡的时候,别人就会那这个来问你。
为什么要用ConcurrentHashMap,因为HashMap不是线程安全的,这种线程不安全性体现在进行迭代的时候,也就是用Iterator进行访问。
问题来了,呵呵。
HashMap为什么是不安全的?
HashMap在put的时候,插入的元素超过了容量(由负载因子决定)的范围就会触发扩容操作,就是rehash,这个会重新将原数组的内容重新hash到新的扩容数组中,在多线程的环境下,存在同时其他的元素也在进行put操作,如果hash值相同,可能出现同时在同一数组下用链表表示,造成闭环,导致在get时会出现死循环,所以HashMap是线程不安全的。
觉得还是要用一个例子来说明这种情况。
为啥HashTable是安全的?
另一个键值存储集合HashTable,它是线程安全的,它在所有涉及到多线程操作的都加上了synchronized关键字来锁住整个table,这就意味着所有的线程都在竞争一把锁,在多线程的环境下,它是安全的,但是无疑是效率低下的。
Collections.synchronizedMap()函数返回的是线程安全的HashMap。
平常多线程真的用的比较少,只有在练习代码写写多线程。
package com.tuhooo.practice.concurrent;
import java.util.*;
public class TestConcurrent implements Runnable {
private static HashMap<String, Object> m = new HashMap<String, Object>();
private Integer flag;
static {
for(int i=0; i<10000; i++) {
m.put("hahaha" + i, "hahaha" + i);
}
}
TestConcurrent(Integer flag) {
this.flag = flag;
}
public void run() {
if(new Integer(1).equals(flag)) {
final Iterator<String> iterator = m.keySet().iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
} else {
final Set<String> strings = m.keySet();
for(String key : strings) {
System.out.println("remove " + m.remove(key));
}
}
}
public static void main(String[] args) {
new Thread(new TestConcurrent(1)).start();
new Thread(new TestConcurrent(2)).start();
}
}
下面再用Collections.synchronizedMap(),并在HashMap遍历的时候加上同步锁,可是仍然会出现并发修改异常。因为Collections.synchronizedMap(),只是简单地为HashMap的操作加了一个锁而已。
package com.tuhooo.practice.concurrent;
import java.util.*;
public class TestConcurrent implements Runnable {
private static Map<String, Object> m;
private Integer flag;
private static Object obj = new Object();
TestConcurrent(Integer flag, Map<String, Object> map) {
this.flag = flag;
m = map;
}
public void run() {
if(new Integer(1).equals(flag)) {
// 这里用了同步操作, 可是还是会出错
synchronized (obj) {
final Iterator<String> iterator = m.keySet().iterator();
while(iterator.hasNext()) {
System.out.println(iterator.next());
}
}
} else {
final Set<String> strings = m.keySet();
for(String key : strings) {
System.out.println("remove " + m.remove(key));
}
}
}
public static void main(String[] args) {
final Map<String, Object> map = Collections.synchronizedMap(new HashMap<String, Object>());
for(int i=0; i<10000; i++) {
map.put("hahaha" + i, "hahaha" + i);
}
new Thread(new TestConcurrent(1, map)).start();
new Thread(new TestConcurrent(2, map)).start();
}
}
p.s. 这里好像写错了,锁应该加在keySet()获得key的集合上,而不是找个obj加锁。
其实HashTable有很多的优化空间,锁住整个table这么粗暴的方法可以变相的柔和点,比如在多线程的环境下,对不同的数据集进行操作时其实根本就不需要去竞争一个锁,因为他们不同hash值,不会因为rehash造成线程不安全,所以互不影响,这就是锁分离技术,将锁的粒度降低,利用多个锁来控制多个小的table。
也就是用这两种写法都会出错,那么我们看一下ConcurrentHashMap是怎么做的。
在JDK1.7版本中,ConcurrentHashMap的数据结构是由一个Segment数组和多个HashEntry组成,如下图所示:
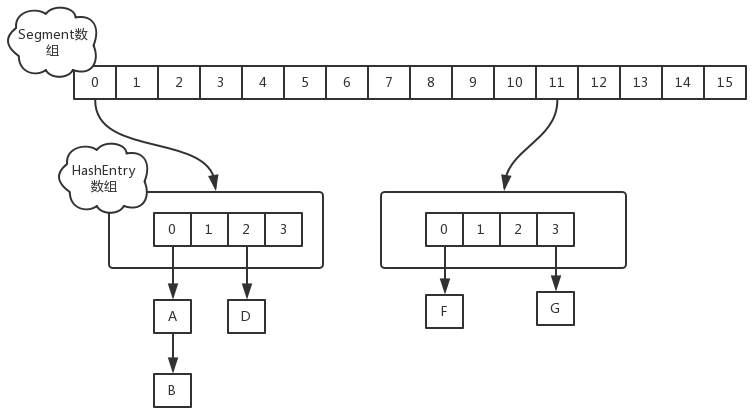
所以Segment的大小取值都是以2的N次方,无关concurrencyLevel的取值,当然concurrencyLevel最大只能用16位的二进制来表示,即65536,换句话说,Segment的大小最多65536个,没有指定concurrencyLevel元素初始化,Segment的大小ssize默认为16
每一个Segment元素下的HashEntry的初始化也是按照位于运算来计算,用cap来表示,HashEntry大小的计算也是2的N次方(cap <<=1), cap的初始值为1,所以HashEntry最小的容量为2
HashMap中常用的四种操作有:
public V get(Object key)
public V put(K key, V value)
public V remove(Object key)
迭代
在多线程环境下,get,put,remove都是比较容易实现的(如果不考虑效率,简单加锁即可),迭代的操作才是真正的难点。
默认一个ConcurrentHashMap中有16个子HashMap,所以相当于一个二级哈希。对于所有的操作都是先定位到子HashMap,再作相应的操作。
public V get(Object key)
先得到 key所在的table,再像HashMap一样get,
中间并不加锁
ConcurrentHashMap的get操作跟HashMap类似,只是ConcurrentHashMap第一次需要经过一次hash定位到Segment的位置,然后再hash定位到指定的HashEntry,遍历该HashEntry下的链表进行对比,成功就返回,不成功就返回null。
public V put(K key, V value)
先得到所属的table,加锁,
判断table是否要扩容
如果table要扩容,则产生newTable,
hash值相同的slot整体移到newTable,
hash值不同的slot,把oldTable中的所有Entry都复制到newTable中。
因为有可能其它线程在历遍这个table,所以不能把原来的链表拆断。
更深入的,Segment实现了ReentrantLock,也就带有锁的功能,当执行put操作时,会进行第一次key的hash来定位Segment的位置,如果该Segment还没有初始化,即通过CAS操作进行赋值,然后进行第二次hash操作,找到相应的HashEntry的位置,这里会利用继承过来的锁的特性,在将数据插入指定的HashEntry位置时(链表的尾端),会通过继承ReentrantLock的tryLock()方法尝试去获取锁,如果获取成功就直接插入相应的位置,如果已经有线程获取该Segment的锁,那当前线程会以自旋的方式去继续的调用tryLock()方法去获取锁,超过指定次数就挂起,等待唤醒。
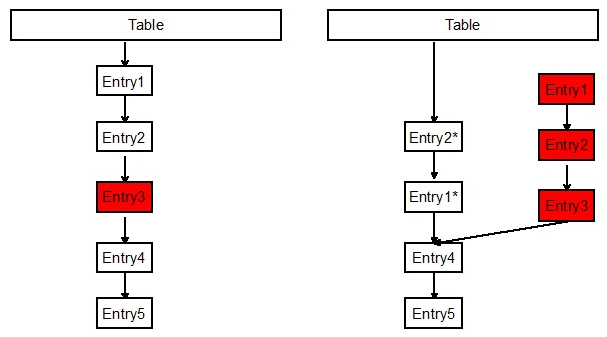
public V remove(Object key)
remove操作,如下图,要删除Entry3,则先复制Entry1为Entry1*,Entry1*指向Entry4,再复制Entry2为Entry2*,Entry2*指向Entry1*,最终形成一个两叉的链表。原本的Entry1,Entry2,Entry3会被GC自动回收。
迭代操作
ConcurrentHashMap的历遍是从后向前历遍的,因为如果有另一个线程B在执行clear操作时,会把table中的所有slot都置为null,这个操作是从前向后执行
如果线程A在历遍Map时也是从前向后,则有可能会出现追赶现象。
size操作
计算ConcurrentHashMap的元素大小是一个有趣的问题,因为他是并发操作的,就是在你计算size的时候,他还在并发的插入数据,可能会导致你计算出来的size和你实际的size有相差(在你return size的时候,插入了多个数据),要解决这个问题,JDK1.7版本用两种方案。
第一种方案他会使用不加锁的模式去尝试多次计算ConcurrentHashMap的size,最多三次,比较前后两次计算的结果,结果一致就认为当前没有元素加入,计算的结果是准确的;
第二种方案是如果第一种方案不符合,他就会给每个Segment加上锁,然后计算ConcurrentHashMap的size返回。
JDK1.8的实现
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本。
其实可以看出JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言,总结如下思考:
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
- JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点:
- 因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
- JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
- 在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据
ConcurrentHashMap的使用和原理的更多相关文章
- ConcurrentHashMap——浅谈实现原理及源码
本文整理自漫画:什么是ConcurrentHashMap? - 小灰的文章 - 知乎 .已获得作者授权. HashMap 在高并发下会出现链表环,从而导致程序出现死循环.高并发下避免HashMap 出 ...
- Java ConcurrentHashMap
通过分析Hashtable就知道,synchronized是针对整张Hash表的,即每次锁住整张表让线程独占, ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术. ...
- Java_深度剖析ConcurrentHashMap
本文基于Java 7的源码做剖析. ConcurrentHashMap的目的 多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用Hash ...
- Java:ConcurrentHashMap
ConcurrentHashMap的目的 多线程环境下,使用Hashmap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap.虽然已经有一个线程安全的Ha ...
- java并发包研究之-ConcurrentHashMap
概述 HashMap是非线程安全的,HashTable是线程安全的. 那个时候没怎么写Java代码,所以根本就没有听说过ConcurrentHashMap,只知道面试的时候就记住这句话就行了…至于为什 ...
- 深度剖析ConcurrentHashMap(转)
概述 还记得大学快毕业的时候要准备找工作了,然后就看各种面试相关的书籍,还记得很多面试书中都说到: HashMap是非线程安全的,HashTable是线程安全的. 那个时候没怎么写Java代码,所以根 ...
- 同步容器类ConcurrentHashMap及CopyOnWriteArrayList
ConcurrentHashMap Java5在java.util.concurrent包中提供了多种并发容器类来改进同步容器的性能.其中应用最为广泛的为ConcurrentHashMap,Concu ...
- Java并发分析—ConcurrentHashMap
LZ在 https://www.cnblogs.com/xyzyj/p/6696545.html 中简单介绍了List和Map中的常用集合,唯独没有CurrentHashMap.原因是CurrentH ...
- [Java并发包学习八]深度剖析ConcurrentHashMap
转载自https://blog.csdn.net/WinWill2012/article/details/71626044 还记得大学快毕业的时候要准备找工作了,然后就看各种面试相关的书籍,还记得很多 ...
随机推荐
- Vue之$set使用
背景 后端参与前端开发的小白,在开发过程中遇到了如下情况:当vue的data里边声明或者已经赋值过的对象或者数组(数组里边的值是对象)时,向对象中添加新的属性,如果更新此属性的值,是不会更新视图的. ...
- JDBC完整版实现
package songyan.jdbc.test; import java.sql.Connection; import java.sql.DriverManager; import java.sq ...
- Linux下防止文件误删方法
转载:http://coolsky.blog.51cto.com/177347/1230332 Linux系统中,在root帐号下使用rm * -rf是非常危险的,一不小心就可能删除系统中的重要文件. ...
- windows下如何添加、删除和修改静态路由
1.添加一条路由表 route add 192.168.100.0 mask 255.255.255.248 192.168.1.1 metric 3 if 2 1 2 添加一条路由记录,所有到192 ...
- Eclipse下的java工程目录
对新手来讲,一个Java工程内部的多个文件夹经常会让大家困惑.更可恶的是莫名其妙的路径问题,在Eclipse编写Java程序中,出现频率最高的错误很可能就是路径问题. 这些问题原因其实都是一个,就是关 ...
- Snapdragon connect to android devices
怎么都连不上,连不上连不上... 用adb devices是列出来的,开发者选项也设置了, 后来查了下 把adb的路径拖到系统环境变量里就可以了.终于连上了,今天不用加班了...
- Jsp中如何在<c:forEach>标签内获取集合的长度
利用jstl标签functions的prefix属性的length属性值 1.首先在jsp页面导入jstl function标签 <%@ taglib prefix="fn" ...
- Manthan, Codefest 16 D. Fibonacci-ish(暴力)
题目链接:点击打开链接 题意:给你n个数, 问最长的题目中定义的斐波那契数列. 思路:枚举開始的两个数, 由于最多找90次, 所以能够直接暴力, 用map去重. 注意, 该题卡的时间有点厉害啊. ...
- java 中文转Unicode 以及 Unicode转中文
package com.sun; public class Snippet { public static void main(String[] args) { String cn ...
- Gacutil.exe(全局程序集缓存工具)
全局程序集缓存 .NET Framework (current version) 其他版本 安装有公共语言运行时的每台计算机都具有称为全局程序集缓存的计算机范围内的代码缓存.全局程序集缓存中存储了专门 ...