scrapy--json(喜马拉雅Fm)
已经开始听喜马拉雅Fm电台有2个月,听里面的故事,感觉能听到自己,特别是蕊希电台,始于声音,陷于故事,忠于总结。感谢喜马拉雅Fm陪我度过了这2个月,应该是太爱了,然后就开始对Fm下手了。QAQ
该博客基于以下博客,提取和修改。
https://www.jianshu.com/p/8ff95111b18a
https://www.imooc.com/article/48315
需要解决问题
1.m4a文件储存在json文本中 --f12审查元素,使用json.loads读取信息
2.将其他主播的所有音频文件也下载
3.下载文件时,对提取的文件进行分类 --提取主播id,使用meta进行传递
三、先给大家看看成果

一、提取网页源码
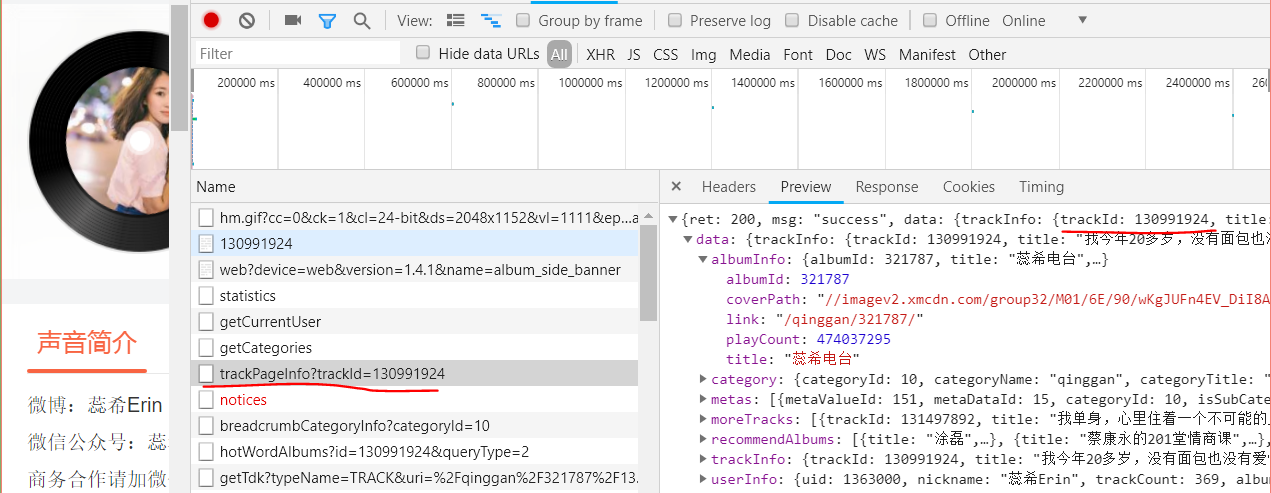
1.1_提取trackId:"https://www.ximalaya.com/qinggan/321787/130991924"
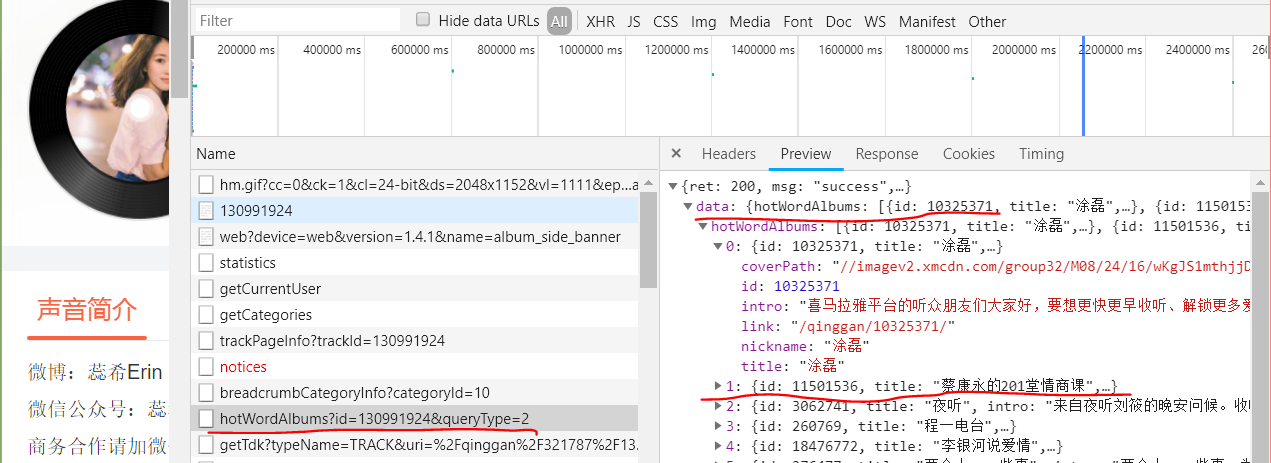
1.2_提取其他主播Id
1.3_主播所有作品的trackId:"http://www.ximalaya.com/revision/album/getTracksList?albumId=321787&pageNum=13"

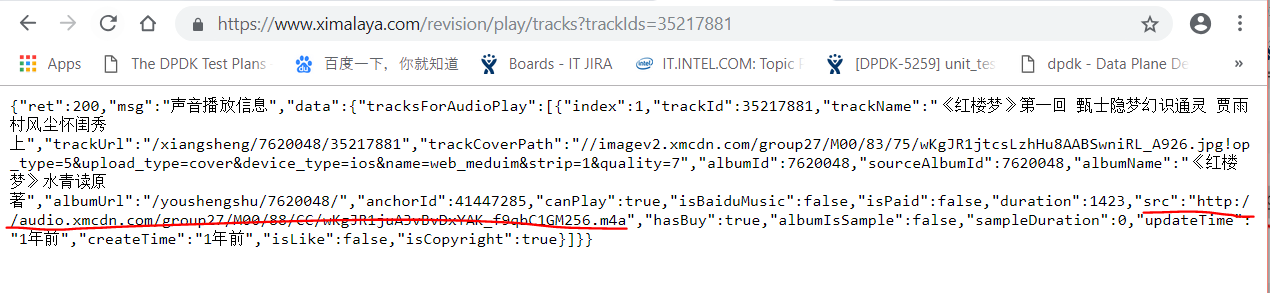
1.4_提取.m4a文件:https://www.ximalaya.com/revision/play/tracks?trackIds=35217881
二、代码设置:middlewares.py,settings.py,items.py就不细讲了,可以看我之前的博客。
2.1_pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import scrapy
from os.path import join,basename,dirname
import os
import urlparse
from scrapy.pipelines.files import FilesPipeline
from Xima.settings import FILES_STORE
from scrapy.exceptions import DropItem class XimaPipeline(FilesPipeline):
def get_media_requests(self,item,info):
yield scrapy.Request(item['m4_urls'],meta={"file_name":item['file_name'],'m4_urls':item['m4_urls']}) def file_path(self,request,response=None,info=None):
#get_media_requests函数是返回了一个request对象的,而这个request对象就是file_path函数接收的那个
item = request.meta
return join(FILES_STORE, item['file_name'] + '\\' + basename(item['m4_urls'])) def item_completed(self, results, item, info):
file_paths = [x['path'] for ok, x in results if ok]
if not file_paths:
raise DropItem("Item contains no files") return item
2.2_爬取代码
# -*- coding: utf-8 -*-
import scrapy
from Xima.items import XimaItem
import json
import pdb
from Xima.settings import USER_AGENT
import random class XimaSpider(scrapy.Spider):
name = 'xima'
allowed_domains = ['www.ximalaya.com']
start_urls = ['https://www.ximalaya.com/revision/seo/hotWordAlbums?id=321787&queryType=1'] headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.ximalaya.com',
'Origin': 'www.ximalaya.com',
'Referer': 'https://www.ximalaya.com/revision/seo/hotWordAlbums?id=321787&queryType=1',
'User-Agent': random.choice(USER_AGENT),
'X-Requested-With': 'XMLHttpRequest',
} def start_requests(self):
yield scrapy.Request(self.start_urls[0],callback=self.parse_1) def parse_1(self,response):
for each_url in json.loads(response.body)['data']['hotWordAlbums']:
for i in xrange(20):
new_url = 'http://www.ximalaya.com/revision/album/getTracksList?albumId='+str(each_url['id'])+'&pageNum='+str(i)
yield scrapy.Request(new_url,callback=self.parse,meta={'trackid':str(each_url['id'])}) def parse(self, response):
if json.loads(response.body)['data']['tracks']:
for sel in json.loads(response.body)['data']['tracks']:
stackids = sel['trackId']
meta1 = response.meta
yield scrapy.Request('https://www.ximalaya.com/revision/play/tracks?trackIds=%s'%stackids,callback=self.m4a,meta=meta1) def m4a(self,response):
xima = XimaItem()
if json.loads(response.body)['data']['tracksForAudioPlay'][0]['src']:
xima['file_name'] = response.meta['trackid']
xima['m4_urls'] = json.loads(response.body)['data']['tracksForAudioPlay'][0]['src'] yield xima
scrapy--json(喜马拉雅Fm)的更多相关文章
- scrapy--json(喜马拉雅Fm)(二)
学习了对数据的储存,感觉还不够深入,昨天开始对储存数据进行提取.整合和图像化显示.实例还是喜马拉雅Fm,算是对之前数据爬取之后的补充. 明确需要解决的问题 1,蕊希电台全部作品的进行储存 --scra ...
- 喜马拉雅FM抓包之旅
一.概述 最近学院组织安排大面积实习工作,今天刚刚发布了喜马拉雅FM实习生招聘的面试通知.通知要求:公司采用开放式题目的方式进行筛选,申请的同学须完成如下题目 写程序输出喜马拉雅FM上与"卓 ...
- [HMLY]5.模仿喜马拉雅 FM
项目介绍: 文:HansRove(github)XiMaLaYa-by-HansRove- 仿做喜马拉雅, 对AVFoundation框架的一次尝试 软件环境: iOS9.1硬件环境: Mac O ...
- iOS仿喜马拉雅FM做的毕业设计及总结(含新手福利源码)
其实仿喜马拉雅FM很早就开始了,从我刚接触iOS开始,就开始仿做了一部分,眼尖的人都从我的github找到了那个项目.随着找到实习iOS工作,仿写就落下了,但唯一的收获就是给过去打了一个响亮的耳光,因 ...
- 喜马拉雅FM接入
最近有考虑接入,但是一方面由于沟通不畅等,另一方面没有浏览开发者协议,品牌规范等,多走了很多弯路,所以记下接入的注意事项和关键点 一. 接入前准备工作 喜马拉雅FM开放平台地址:http://open ...
- JY播放器【喜马拉雅FM电脑端,附带下载功能】
今天给大家带来一款神器----JY播放器.可以不用打开网页就在电脑端听喜马拉雅FM的节目,而且可以直接下载,对于我这种强迫症患者来说真的是神器.我是真的不喜欢电脑任务栏上面密密麻麻的. 目前已经支持平 ...
- 喜马拉雅 FM 已购付费音频下载
如何下载在喜马拉雅 FM 中已购买的付费音频.之前想分享自己购买的付费音频给朋友听,碍于喜马拉雅 FM 的音频不能直接导出,所以准备自己搞个下载的小软件. 仅可下载已购买的付费音频.当然,如果你是会员 ...
- iOS涂色涂鸦效果、Swift仿喜马拉雅FM、抽屉转场动画、拖拽头像、标签选择器等源码
iOS精选源码 LeeTagView 标签选择控件 为您的用户显示界面添加美观的加载视图 Swift4: 可拖动头像,增加物理属性 Swift版抽屉效果,自定义转场动画管理器 Swift 仿写喜马拉雅 ...
- 做一个新产品需求,体验的分析文档?(例:喜马拉雅FM)
2.1 战略层 2.11 产品定位: 一款产品覆盖面广,收听节目种类齐全,资源丰富的电台APP. 以PGC为主流,通过合作方式吸纳专业的电台人,节目人,行业名人分享内容. 融合UGC,满足人们在空闲时 ...
随机推荐
- 解决MyEclipse报errors running builder ‘javascript validator’ on project
今天导入项目的时候,报了以下错误 MyEclipse测到功能代码变化(保存动作触发)就报错: errors running builder ‘javascript validator’ on proj ...
- Python学习笔记--语音处理初步
语音处理最基础的部分就是如何对音频文件进行处理. 声音的物理意义:声音是一种纵波,纵波是质点的振动方向与传播方向同轴的波.如敲锣时,锣的振动方向与波的传播方向就是一致的,所以声波是纵波.纵波是波动的一 ...
- Oauth服务端协议开发
授权流程图 AS : Authorization Server (权限服务器) RS : Resource Server (资源服务器) Client :Client RS(资源服务器)流程图 以上仅 ...
- Java入门之IDE集成开发环境安装及配置
常用的开发工具 一.Eclipse Eclipse 是一个开放源代码的.基于 Java 的可扩展开发平台.就其本身而言,它只是一个框架和一组服务,用于通过插件组件构建开发环境.幸运的是,Eclipse ...
- 利用自定义特性实现List的多属性排序
知道linq有order by的功能,但是还是动手研究了一下,算是多实践实践反射.这篇算是笔记,直接上代码: using System; using System.Collections.Concur ...
- 函数的返回值 return
布尔类型返回 return 0:返回假: return 1:返回真:
- tomcat启动部署APP报错:This is very likely to create a memory leak
This is very likely to create a memory leak的错误,网上很多,原因也是各种各样,这里也仅提供一个解决的思路. 问题描述:启动tomcat时,不能访问部署的AP ...
- ZIP文件压缩和解压
最近要做一个文件交互,上传和下载, 都是zip压缩文件,所以研究了下,写了如下的示例 注意引用 ICSharpCode.SharpZipLib.dll 文件 该dll文件可以到官方网站去下载, 我这 ...
- eclipse中Tomcat启动了 但看不到tomcat首页
症状: tomcat在eclipse里面能正常启动,而在浏览器中访问http://localhost:8080/不能访问,且报404错误.同时其他项目页面也不能访问. 关闭eclipse里面的tomc ...
- May 1 2017 Week 18 Monday
The very essence of romance is uncertainty. 浪漫的精髓就在于它充满了种种可能. Yesterday my girl friend told me that ...