Elasticsearch同义词词汇单元过滤器
1 简单扩展
"jump,hop,leap"
搜索jump会检索出包含jump、hop或leap的词
1.1 扩展应用在索引阶段
1.2 扩展应用在查询阶段
1.3 对比

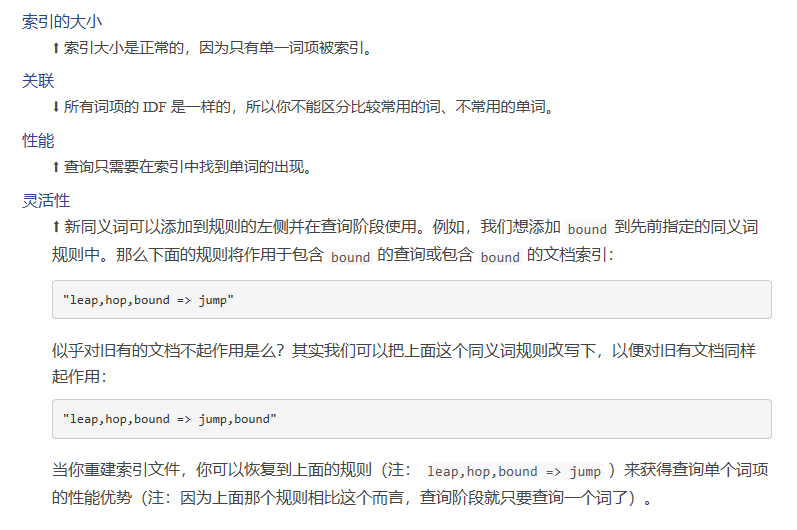
2 简单收缩
把左边的多个同义词映射到了右边的单个词:
"leap,hop => jump"
必须同时应用于索引和查询阶段,以确保查询词项映射到索引中存在的同一个值。
优缺点:
3 类型扩展
"cat => cat,pet",
"kitten => kitten,cat,pet",
"dog => dog,pet"
"puppy => puppy,dog,pet"
如第一行,所有包含cat的文档ID会被索引到倒排索引cat和pet里面。
注意,右边扩大了左边词的的范围。因此,倘若你在索引和查询阶段都使用类型扩展,当你搜索某个词(如cat)的时候,由于cat的IDF值就是cat本来的IDF值,pet的IDF值会比实际上pet的IDF值偏小,因此,包含cat的文档的分数会比包含pet的文档,因而排在更前面。
4 注意
4.1 PET->pet词义变化
经过lowercase过滤器后,包含PET(正电子发射断层扫描)的文档ID会被索引到倒排索引pet中。
解决方案:
在lowercase过滤器之前,利用使用一层同义词词汇单元过滤器,将特殊的单词转化为特殊的词单元,如:
"CAT,CAT scan => cat_scan"
"PET,PET scan => pet_scan"
"Johnny Little,J Little => johnny_little"
"Johnny Small,J Small => johnny_small"
经过lowercase过滤器之后,在进行一次常规的同义词词汇单元过滤器,如:
"cat => cat,pet"
"dog => dog,pet"
"cat scan,cat_scan scan => cat_scan"
"pet scan,pet_scan scan => pet_scan"
"little,small"
4.2 短语查询
如果同义词中有短语词组,如:
"usa,united states,u s a,united states of america"
一定要在分词之前,使用词义收缩,否则会造成严重不匹配(原因)
"united states,u s a,united states of america=>usa"
这个方法的缺点是,因为把 united states of america 转换成了同义词 usa, 你就不能使用 united states of america 去搜索出 united 或者 states 。 你需要使用一个额外的字段并用另一个解析器链来达到这个目的。
4.3 符号同义词
符号表情能够很好地表示语义。为了在分词过程中损失掉这部分信息。可以通过映射字符过滤器将表情符号转化为一个表示它的特殊同义词。如,
":)=>emoticon_happy"
Elasticsearch同义词词汇单元过滤器的更多相关文章
- Python Elasticsearch api,组合过滤器,term过滤器,正则查询 ,match查询,获取最近一小时的数据
Python Elasticsearch api 描述:ElasticSearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.下 ...
- elasticsearch同义词及动态更新
第一种:参考地址:http://dev.paperlesspost.com/setting-up-elasticsearch-synonyms/271.Add a synonyms file.2.Cr ...
- Elasticsearch:使用 IP 过滤器限制连接
文章转载自:https://elasticstack.blog.csdn.net/article/details/107154165
- Elasticsearch自定义分析器
关于分析器 ES中默认使用的是标准分析器(standard analyzer).如果需要对某个字段使用其他分析器,可以在映射中该字段下说明.例如: PUT /my_index { "mapp ...
- ElasticSearch 处理自然语言流程
ES处理人类语言 ElasticSearch提供了很多的语言分析器,这些分析器承担以下四种角色: 文本拆分为单词 The quick brown foxes → [ The, quick, brown ...
- ElasticSearch最全分词器比较及使用方法
介绍:ElasticSearch 是一个基于 Lucene 的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于 RESTful web 接口.Elasticsearch 是用 Java 开 ...
- elasticsearch索引和映射
目录 1. elasticsearch如何实现搜索 1.1 搜索实例 1.2 es中数据的类型 1.3 倒排索引 1.4 分析与分析器 1.4.1 什么是分析器 1.4.2 内置分析器种类 1.4.3 ...
- Elasticsearch查询优化总结
查询优化 1 从提高查询精确度进行优化: 本部分主要针对全文搜索进行探究. 1.1 倒排索引 1.1.1 什么是倒排索引: 一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文 ...
- Elasticsearch中的分词器比较及使用方法
Elasticsearch 默认分词器和中分分词器之间的比较及使用方法 https://segmentfault.com/a/1190000012553894 介绍:ElasticSearch 是一个 ...
随机推荐
- 2017.10.27 C语言精品集
第一章 程序设计和C语言 1.1 什么是计算机程序? @ ······ 所谓程序,就是一组计算机能识别和执行的指令.每一条指令使计算机执行特定的操作. 计算机的一切操作都是由程序控制的.所以计算机的本 ...
- 20145238-荆玉茗 《Java程序设计》第五次实验报告
实验五 Java网络编程及安全 一.实验内容 1.运行下载的TCP代码,结对进行,一人服务器,一人客户端: 2.利用加解密代码包,编译运行代码,一人加密,一人解密: 3.集成代码,一人加密后通过TCP ...
- ajax(form)图片上传(spring)
第一步:spring-web.xml <!--配置上传下载--> <bean id="multipartResolver" class="org.spr ...
- C#中 property 与 attribute的区别?
C#中 property 与 attribute的区别?答:attribute:自定义属性的基类;property :类中的属性
- 一篇SSM框架整合友好的文章(三)
###一.SpringMVC理论 它始终是围绕 handler. 数据模型 model. 页面view进行开发的. 运行流程图: 通过mvc配置文件,配置"中央处理器"dispat ...
- Python 统计不同url svn代码变更数
#!/bin/bash/python # -*-coding:utf-8-*- #svn统计不同url代码行数变更脚本,过滤空行,不过滤注释. import subprocess,os,sys,tim ...
- Java分享笔记:使用缓冲流复制文件
[1] 程序设计 /*------------------------------- 1.缓冲流是一种处理流,用来加快节点流对文件操作的速度 2.BufferedInputStream:输入缓冲流 3 ...
- 【杂题总汇】Codeforces-67A Partial Teacher
[Codeforces-67A]Partial Teacher 上周刷了一大堆小紫薯的动态规划的题
- mongodb多个查询语句
db.getCollection('costitems').find({"created":{"$gte":ISODate("2019-01-02T0 ...
- springMVC入门二
一.准备工作 参考springMVC入门一,搭建maven项目如下: 前台结构如下: 项目介绍:使用springMVC实现前后台数据交互,例如controller返回json,页面传入pojo 二.具 ...