ACM学习历程—POJ3565 Ants(最佳匹配KM算法)
Young naturalist Bill studies ants in school. His ants feed on plant-louses that live on apple trees. Each ant colony needs its own apple tree to feed itself.
Bill has a map with coordinates of n ant colonies and n apple trees. He knows that ants travel from their colony to their feeding places and back using chemically tagged routes. The routes cannot intersect each other or ants will get confused and get to the wrong colony or tree, thus spurring a war between colonies.
Bill would like to connect each ant colony to a single apple tree so that all n routes are non-intersecting straight lines. In this problem such connection is always possible. Your task is to write a program that finds such connection.
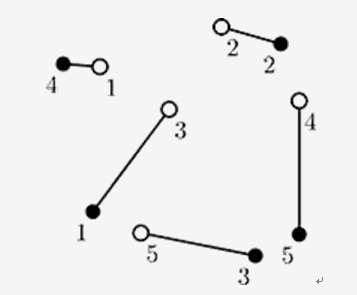
On this picture ant colonies are denoted by empty circles and apple trees are denoted by filled circles. One possible connection is denoted by lines.
Input
The first line of the input file contains a single integer number n (1 ≤ n ≤ 100) — the number of ant colonies and apple trees. It is followed by n lines describing n ant colonies, followed by n lines describing n apple trees. Each ant colony and apple tree is described by a pair of integer coordinates x and y (−10 000 ≤ x, y ≤ 10 000) on a Cartesian plane. All ant colonies and apple trees occupy distinct points on a plane. No three points are on the same line.
Output
Write to the output file n lines with one integer number on each line. The number written on i-th line denotes the number (from 1 to n) of the apple tree that is connected to the i-th ant colony.
Sample Input
5
-42 58
44 86
7 28
99 34
-13 -59
-47 -44
86 74
68 -75
-68 60
99 -60
Sample Output
4
2
1
5
3
题目就是求类似图中实心到空心圆的连线,一一映射,使两两线段不相交。
有一种思路就是一开始让所有点对随意连接,然后让相交的线段进行调整,这里比较好理解,比如AC与BD相交,那么AD与BC就必然不相交了。这样的话需要的调整的次数似乎不是很好计算。
但是可以肯定的是,最终状态必然是两两不相交了。
可以发现上面相交的AC与BD,必然满足AD+BC < AC+BD。这里可以用两次三角形两边之和大于第三边进行证明。这一步让点对里面边的权值和变小了。
于是考虑,逆命题:是否当边AC与BD可以减小成AD与BC时,一定是相交的?
事实证明这个命题是不一定的,但是可以发现当可以减小成AD与BC时,AD和BC一定是不相交的。否则会导致AD+BC > AC+BD。
所以只要能减小边权的和,一定能保证不相交。那么最终状态就变成了边权和最小的状态,也就是最小匹配。可以采用KM算法进行。
似乎是数据问题,不能使用边的平方进行处理。要用double保存边的大小,然后等于0的判断,改成小于eps。
代码:
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cmath>
#include <cstring>
#include <algorithm>
#include <set>
#include <map>
#include <queue>
#include <string>
#define LL long long using namespace std; const int maxN = ;
const double inf = 1e10;
int n;
struct Point
{
double x, y;
}x[maxN], y[maxN];
int nx, ny;
int link[maxN];
double lx[maxN], ly[maxN], slack[maxN], w[maxN][maxN];//link表示和y相接的x值,lx,ly为顶标,nx,ny分别为x点集y点集的个数
bool visx[maxN], visy[maxN]; inline double dis(int i, int j)
{
double ans = (x[i].x-y[j].x)*(x[i].x-y[j].x) + (x[i].y-y[j].y)*(x[i].y-y[j].y);
return -sqrt(ans);
} bool DFS(int x)
{
visx[x] = true;
for (int y = ; y <= ny; y++)
{
if (visy[y])
continue;
double t = lx[x]+ly[y]-w[x][y];
if (fabs(t) < 1e-)
{
visy[y] = true;
if (link[y] == - || DFS(link[y]))
{
link[y] = x;
return true;
}
}
else if (slack[y] > t)//不在相等子图中slack取最小的
slack[y] = t;
}
return false;
} void KM()
{
memset(link, -, sizeof(link));
memset(ly, , sizeof(ly));
for (int i = ; i <= nx; i++)//lx初始化为与它关联边中最大的
for (int j = ; j <= ny; j++)
if (j == || w[i][j] > lx[i])
lx[i] = w[i][j]; for (int x = ; x <= nx; x++)
{
for (int i = ; i <= ny; i++)
slack[i] = inf;
for (;;)
{
memset(visx, false, sizeof(visx));
memset(visy, false, sizeof(visy));
if (DFS(x))//若成功(找到了增广轨),则该点增广完成,进入下一个点的增广
break;//若失败(没有找到增广轨),则需要改变一些点的标号,使得图中可行边的数量增加。
//方法为:将所有在增广轨中(就是在增广过程中遍历到)的X方点的标号全部减去一个常数d,
//所有在增广轨中的Y方点的标号全部加上一个常数d
double d = inf;
for (int i = ; i <= ny; i++)
if (!visy[i] && d > slack[i])
d = slack[i];
for (int i = ; i <= nx; i++)
if (visx[i])
lx[i] -= d;
for (int i = ; i <= ny; i++)//修改顶标后,要把所有不在交错树中的Y顶点的slack值都减去d
if (visy[i])
ly[i] += d;
else
slack[i] -= d;
}
} for (int i = ; i <= n; ++i)
printf("%d\n", link[i]);
} void input()
{
nx = ny = n;
for (int i = ; i <= n; ++i)
scanf("%lf%lf", &y[i].x, &y[i].y);
for (int i = ; i <= n; ++i)
scanf("%lf%lf", &x[i].x, &x[i].y);
for (int i = ; i <= n; ++i)
for (int j = ; j <= n; ++j)
w[i][j] = dis(i, j);
} int main ()
{
//freopen("test.in", "r", stdin);
while (scanf ("%d", &n) != EOF)
{
input();
KM();
}
return ;
}
ACM学习历程—POJ3565 Ants(最佳匹配KM算法)的更多相关文章
- 二分图匹配之最佳匹配——KM算法
今天也大致学了下KM算法,用于求二分图匹配的最佳匹配. 何为最佳?我们能用匈牙利算法对二分图进行最大匹配,但匹配的方式不唯一,如果我们假设每条边有权值,那么一定会存在一个最大权值的匹配情况,但对于KM ...
- hdu2255 奔小康赚大钱 二分图最佳匹配--KM算法
传说在遥远的地方有一个非常富裕的村落,有一天,村长决定进行制度改革:重新分配房子.这可是一件大事,关系到人民的住房问题啊.村里共有n间房间,刚好有n家老百姓,考虑到每家都要有房住(如果有老百姓没房子住 ...
- POJ3565带权匹配——km算法
题目:http://poj.org/problem?id=3565 神奇结论:当总边权最小时,任意两条边不相交! 转化为求二分图带权最小匹配. 可以用费用流做.但这里学一下km算法. https:// ...
- 二分图最佳匹配KM算法 /// 牛客暑期第五场E
题目大意: 给定n,有n间宿舍 每间4人 接下来n行 是第一年学校规定的宿舍安排 接下来n行 是第二年学生的宿舍安排意愿 求满足学生意愿的最少交换次数 input 2 1 2 3 4 5 6 7 8 ...
- 【HDU 2255】奔小康赚大钱 (最佳二分匹配KM算法)
奔小康赚大钱 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Subm ...
- 训练指南 UVALive - 4043(二分图匹配 + KM算法)
layout: post title: 训练指南 UVALive - 4043(二分图匹配 + KM算法) author: "luowentaoaa" catalog: true ...
- 二分图最大权匹配——KM算法
前言 这东西虽然我早就学过了,但是最近才发现我以前学的是假的,心中感慨万千(雾),故作此篇. 简介 带权二分图:每条边都有权值的二分图 最大权匹配:使所选边权和最大的匹配 KM算法,全称Kuhn-Mu ...
- 二分图 最大权匹配 km算法
这个算法的本质还是不断的找增广路: KM算法的正确性基于以下定理:若由二分图中所有满足A[i]+B[j]=w[i,j]的边(i,j)构成的子图(称做相等子图)有完备匹配,那么这个完备匹配就是二分图的最 ...
- 二分图带权匹配 KM算法与费用流模型建立
[二分图带权匹配与最佳匹配] 什么是二分图的带权匹配?二分图的带权匹配就是求出一个匹配集合,使得集合中边的权值之和最大或最小.而二分图的最佳匹配则一定为完备匹配,在此基础上,才要求匹配的边权值之和最大 ...
随机推荐
- IOS发送带附件的邮件
本文转载至 http://blog.csdn.net/zltianhen/article/details/7693810 1.加入邮箱的框架 #import <MessageUI/MFMail ...
- php字符串操作: 去掉UTF-16的空格
$s = json_encode($s); $s = str_replace('\u00a0','',$s); $s = str_replace('\u3000','',$s); $s = str_r ...
- iOS 开发与H5交互(JavaScriptCore框架的使用)
现在的iOS项目中嵌入了越来越多的Web界面,当然是为了方便,那么为了迎合这一趋势,作为iOS开发程序员,我们必须要了解怎么样用OC去和这些Web界面进行交互.这里介绍的是JavaScriptCore ...
- 【python】-- 元组、字典
元组 元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表 用途:一般情况下用于自己写的程序能存下数据,但是又希望这些数据不会被改变,比如:数据库连接信息等 1.访问元 ...
- PBR探索
原理 根据能量守恒,以及一系列光照原理得出微表面BRDF(Bidirectional Reflectance Distribution Function)公式 // D(h) F(v,h) G(l,v ...
- 《linux 内核全然剖析》 fork.c 代码分析笔记
fork.c 代码分析笔记 verifiy_area long last_pid=0; //全局变量,用来记录眼下最大的pid数值 void verify_area(void * addr,int s ...
- python数据分析之:时间序列一
在处理很多数据的时候,我们都要用到时间的概念.比如时间戳,固定时期或者时间间隔.pandas提供了一组标准的时间序列处理工具和数据算法. 在python中datetime.datetime模块是用的最 ...
- Docker学习总结之docker创建私有仓库(private Repositories)
Docker 创建 Private Repositories 前言 基于GFW的缘故,国内大陆基本无法pull国外的镜像,更别说官方的index了.如果images无法pull下来,那么docker就 ...
- JVM性能优化, Part 2 ―― 编译器
作为JVM性能优化系列文章的第2篇,本文将着重介绍Java编译器,此外还将对JIT编译器常用的一些优化措施进行讨论(参见“JVM性能优化,Part 1″中对JVM的介绍).Eva Andreasson ...
- Python OOP(3) staticmethod和classmethod统计实例
staticmethod 统计实例 #!python2 #-*- coding:utf-8 -*- class c1: amount_instance=0 def __init__(self): c1 ...