mysql分区partition
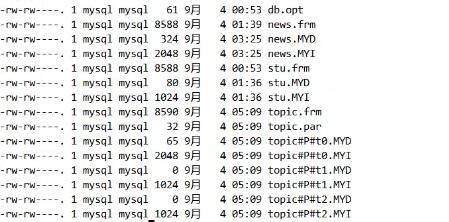
分区后 会产生多个 数据存储文件MYD,MYI ,把内容读取分散到多个文件上,这样减少并发读取,文件锁的概率,提高IO
=== 水平分区的几种模式:===
1. Range(范围) – 这种模式允许DBA将数据划分不同范围。例如DBA可以将一个表通过年份划分成三个分区,80年代(1980's)的数据,90年代(1990's)的数据以及任何在2000年(包括2000年)后的数据。
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) (
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2 VALUES LESS THAN (9000000)
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3 VALUES LESS THAN MAXVALUE DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
在这里,将用户表分成4个分区,以每300万条记录为界限,每个分区都有自己独立的数据、索引文件的存放目录,与此同时,这些目录所在的物理磁盘分区可能也都是完全独立的,可以提高磁盘IO吞吐量。
2.Hash(哈希) – 这中模式允许DBA通过对表的一个或多个列的Hash Key进行计算,最后通过这个Hash码不同数值对应的数据区域进行分区,。例如DBA可以建立一个对表主键进行分区的表。
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY HASH (uid) PARTITIONS 4 (
PARTITION p0
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
分成4个区,数据文件和索引文件单独存放。
3. Key(键值) – 上面Hash模式的一种延伸,这里的Hash Key是MySQL系统产生的。
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY KEY (uid) PARTITIONS 4 (
PARTITION p0
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
)
分成4个区,数据文件和索引文件单独存放。
4.List(预定义列表) – 这种模式允许系统通过DBA定义的列表的值所对应的行数据进行分割。例如:DBA建立了一个横跨三个分区的表,分别根据2004年2005年和2006年值所对应的数据。
CREATE TABLE category (
cid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY LIST (cid) (
PARTITION p0 VALUES IN (0,4,8,12)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES IN (1,5,9,13)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx',
PARTITION p2 VALUES IN (2,6,10,14)
DATA DIRECTORY = '/data4/data'
INDEX DIRECTORY = '/data5/idx',
PARTITION p3 VALUES IN (3,7,11,15)
DATA DIRECTORY = '/data6/data'
INDEX DIRECTORY = '/data7/idx'
);
分成4个区,数据文件和索引文件单独存放。
5. Composite(复合模式) - 很神秘吧,哈哈,其实是以上模式的组合使用而已,就不解释了。举例:在初始化已经进行了Range范围分区的表上,我们可以对其中一个分区再进行hash哈希分区。
= 垂直分区(按列分)=
举个简单例子:一个包含了大text和BLOB列的表,这些text和BLOB列又不经常被访问,这时候就要把这些不经常使用的text和BLOB了划分到另一个分区,在保证它们数据相关性的同时还能提高访问速度。
6.* 子分区
子分区是针对 RANGE/LIST 类型的分区表中每个分区的再次分割。再次分割可以是 HASH/KEY 等类型。例如:
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) SUBPARTITION BY HASH (uid % 4) SUBPARTITIONS 2(
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx'
); 对 RANGE 分区再次进行子分区划分,子分区采用 HASH 类型。
或者
CREATE TABLE users (
uid INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(30) NOT NULL DEFAULT '',
email VARCHAR(30) NOT NULL DEFAULT ''
)
PARTITION BY RANGE (uid) SUBPARTITION BY KEY(uid) SUBPARTITIONS 2(
PARTITION p0 VALUES LESS THAN (3000000)
DATA DIRECTORY = '/data0/data'
INDEX DIRECTORY = '/data1/idx',
PARTITION p1 VALUES LESS THAN (6000000)
DATA DIRECTORY = '/data2/data'
INDEX DIRECTORY = '/data3/idx'
); 对 RANGE 分区再次进行子分区划分,子分区采用 KEY 类型。
= 分区管理 == 分区管理 == 分区管理 == 分区管理 =
1.删除分区 ALERT TABLE users DROP PARTITION p0; 删除分区 p0。
2.重建分区
RANGE 分区重建
ALTER TABLE users REORGANIZE PARTITION p0,p1 INTO (PARTITION p0 VALUES LESS THAN (6000000));
将原来的 p0,p1 分区合并起来,放到新的 p0 分区中。
LIST 分区重建
ALTER TABLE users REORGANIZE PARTITION p0,p1 INTO (PARTITION p0 VALUES IN(0,1,4,5,8,9,12,13));
将原来的 p0,p1 分区合并起来,放到新的 p0 分区中。
HASH/KEY 分区重建
ALTER TABLE users REORGANIZE PARTITION COALESCE PARTITION 2;
用 REORGANIZE 方式重建分区的数量变成2,在这里数量只能减少不能增加。想要增加可以用 ADD PARTITION 方法。
3.新增分区
新增 RANGE 分区
ALTER TABLE category ADD PARTITION (PARTITION p4 VALUES IN (16,17,18,19)
DATA DIRECTORY = '/data8/data'
INDEX DIRECTORY = '/data9/idx');
新增一个RANGE分区。
新增 HASH/KEY 分区
ALTER TABLE users ADD PARTITION PARTITIONS 8;
将分区总数扩展到8个。
4.给已有的表加上分区
alter table results partition by RANGE (month(ttime))
(PARTITION p0 VALUES LESS THAN (1),
PARTITION p1 VALUES LESS THAN (2) , PARTITION p2 VALUES LESS THAN (3) ,
PARTITION p3 VALUES LESS THAN (4) , PARTITION p4 VALUES LESS THAN (5) ,
PARTITION p5 VALUES LESS THAN (6) , PARTITION p6 VALUES LESS THAN (7) ,
PARTITION p7 VALUES LESS THAN (8) , PARTITION p8 VALUES LESS THAN (9) ,
PARTITION p9 VALUES LESS THAN (10) , PARTITION p10 VALUES LESS THAN (11),
PARTITION p11 VALUES LESS THAN (12),
PARTITION P12 VALUES LESS THAN (13) );
默认分区限制分区字段必须是主键(PRIMARY KEY)的一部分,为了去除此
http://blog.csdn.net/tjcyjd/article/details/11194489
mysql分区partition的更多相关文章
- 实战mysql分区(PARTITION)
http://lobert.iteye.com/blog/1955841 前些天拿到一个表,将近有4000w数据,没有任何索引,主键.(建这表的绝对是个人才) 这是一个日志表,记录了游戏中物品的产出与 ...
- 【转载】实战mysql分区(PARTITION)
转载地址:http://lobert.iteye.com/blog/1955841 前些天拿到一个表,将近有4000w数据,没有任何索引,主键.(建这表的绝对是个人才) 这是一个日志表,记录了游戏中物 ...
- mysql分区partition详解
分区管理 论坛 1. RANGE和LIST分区的管理 针对非整形字段进行RANG\LIST分区建议使用COLUMNS分区. RANGE COLUMNS是RANGE分区的一种特殊类型,它与RANGE ...
- 深入解析MySQL分区(Partition)功能
自5.1开始对分区(Partition)有支持 = 水平分区(根据列属性按行分)= 举个简单例子:一个包含十年发票记录的表可以被分区为十个不同的分区,每个分区包含的是其中一年的记录. === 水平分区 ...
- MySQL分区(Partition)功能
引用地址:http://blog.csdn.net/tjcyjd/article/details/11194489 自5.1开始对分区(Partition)有支持 = 水平分区(根据列属性按行分)=举 ...
- 理解MySQL——并行数据库与分区(Partition)
1.并行数据库 1.1.并行数据库的体系结构并行机的出现,催生了并行数据库的出现,不对,应该是关系运算本来就是高度可并行的.对数据库系统性能的度量主要有两种方式:(1)吞吐量(Throughput), ...
- mysql的partition分区
前言:当一个表里面存储的数据特别多的时候,比如单个.myd数据都已经达到10G了的话,必然导致读取的效率很低,这个时候我们可以采用把数据分到几张表里面来解决问题.方式一:通过业务逻辑根据数据的大小通过 ...
- mysql表分区 partition
表分区 partition 当一张表的数据非常多的时候,比如单个.myd文件都达到10G, 这时,必然读取起来效率降低. 可不可以把表的数据分开在几张表上? 1: 从业务角度可以解决.. (分表,水平 ...
- Atitit 分区后的查询 mysql分区记录的流程与原理
Atitit 分区后的查询 mysql分区记录的流程与原理 1.1.1. ibd是MySQL数据文件.索引文件1 1.2. 已经又数据了,如何分区? 给已有的表加上分区 ]1 1.3. 分成4个区, ...
随机推荐
- Rabbitmq消息队列(一) centos下安装rabbitmq
1.简介 AMQP,即Advanced Message Queuing Protocol,高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计.消息中间件主要用于组件之间的解耦,消息的 ...
- C++井字棋游戏,DOS界面版
据说有一个能保证不败的算法.明天看看先再写个PVC版的. 正题.今天无聊写了个井字棋游戏,顺便逐渐让自己习惯良好的代码风格,放上来给新手学习学习. jzq2.cpp /* N字棋游戏PVP版,DOS版 ...
- SVN 钩子操作-同步更新web目录
一个简单的钩子演示:也可以网上搜索其他高级的 本次想要达到的功能是:每次用户commit 到仓库后,仓库的钩子会自动把程序又更新的www/的web发布目录 1.现在web目录下创建一个test.com ...
- storm RollingTopWords 实时top-N计算任务窗口设计
转发请注明原创地址 http://www.cnblogs.com/dongxiao-yang/p/6381037.html 流式计算中我们经常会遇到需要将数据根据时间窗口进行批量统计的场景,窗口性质一 ...
- Cannot lock storage /tmp/hadoop-root/dfs/name. The directory is already locked.
[root@nn01 bin]# ./hadoop namenode -format 12/05/21 06:13:51 INFO namenode.NameNode: STARTUP_MSG: /* ...
- 关于工作与生活——HP大中华区总裁孙振耀撰文谈退休并畅谈人生
转自:http://blog.csdn.net/adaptiver/article/details/7494121 我有个有趣的观察,外企公司多的是25-35岁的白领, 40岁以上的员工很少,二三十岁 ...
- erlang实现一个进程池 pool
erlang的实现一个简单的进程池. erlang进程是非常轻量级的,这个进程池的主要目的是用一种通用的方式去管理和限制系统中运行的资源占用.当运行的工作者进程数量达到上限,进程池还可以把任务放到队列 ...
- 利用socket.io实现消息实时推送
最近在写的项目中存在着社交模块,需要实现这样的一个功能:当发生了用户被点赞.评论.关注等操作时,需要由服务器向用户实时地推送一条消息.最终完成的项目地址为:socket-message-push,这里 ...
- JVM调优- jstat(转)
jstat的用法 用以判断JVM是否存在内存问题呢?如何判断JVM垃圾回收是否正常?一般的top指令基本上满足不了这样的需求,因为它主要监控的是总体的系统资源,很难定位到java应用程序. Jstat ...
- xpath 获取父级,和同级
XPath轴(XPath Axes)可定义某个相对于当前节点的节点集: 1.child 选取当前节点的所有子元素 2.parent 选取当前节点的父节点 3.descendant 选取当前节点的所有后 ...