浅谈堆-Heap(一)
应用场景和前置知识复习
堆排序
排序我们都很熟悉,如冒泡排序、选择排序、希尔排序、归并排序、快速排序等,其实堆也可以用来排序,严格来说这里所说的堆是一种数据结构,排序只是它的应用场景之一
Top N的求解
优先队列
堆得另一个重要的应用场景就是优先队列
我们知道普通队列是:先进先出
而 优先队列:出队顺序和入队顺序无关;和优先级相关
实际生活中有很多优先队列的场景,如医院看病,急诊病人是最优先的,虽然这一类病人可能比普通病人到的晚,但是他们可能随时有生命危险,需要及时进行治疗. 再比如 操作系统要"同时"执行多个任务,实际上现代操作系统都会将CPU的执行周期划分成非常小的时间片段,每个时间片段只能执行一个任务,究竟要执行哪个任务,是有每个任务的优先级决定的.每个任务都有一个优先级.操作系统动态的每一次选择一个优先级最高的任务执行.要让操作系统动态的选择优先级最高的任务去执行,就需要维护一个优先队列,也就是说所有任务都会进入这个优先队列.
基本实现
首先堆是一颗二叉树,这个二叉树必须满足两个两条件
这个二叉树必须是一颗完全二叉树,所谓完全二叉树就是除了最后一层外,其他层的节点的个数必须是最大值,且最后一层的节点都必须集中在左侧.即最后一层从左往右数节点必须是紧挨着的,不能是中间空出一个,右边还有兄弟节点.
这个二叉树必须满足 左右子树的节点值必须小于或等于自身的值(大顶堆) 或者 左右子树的节点值必须大于或等于自身的值(小顶堆)
下图分别是一个大顶堆和小顶堆的示例

看到这两颗二叉树,我们首先就能定义出树节点的结构:
Class Node {
//节点本身的值
private Object value;
private Node left;
private Node right;
....getter and setter
}
但是这里我们利用完全二叉树的性质用数组来构建这棵树.先从上到下,自左至右的来给树的每一个节点编上号.
以大顶堆为例
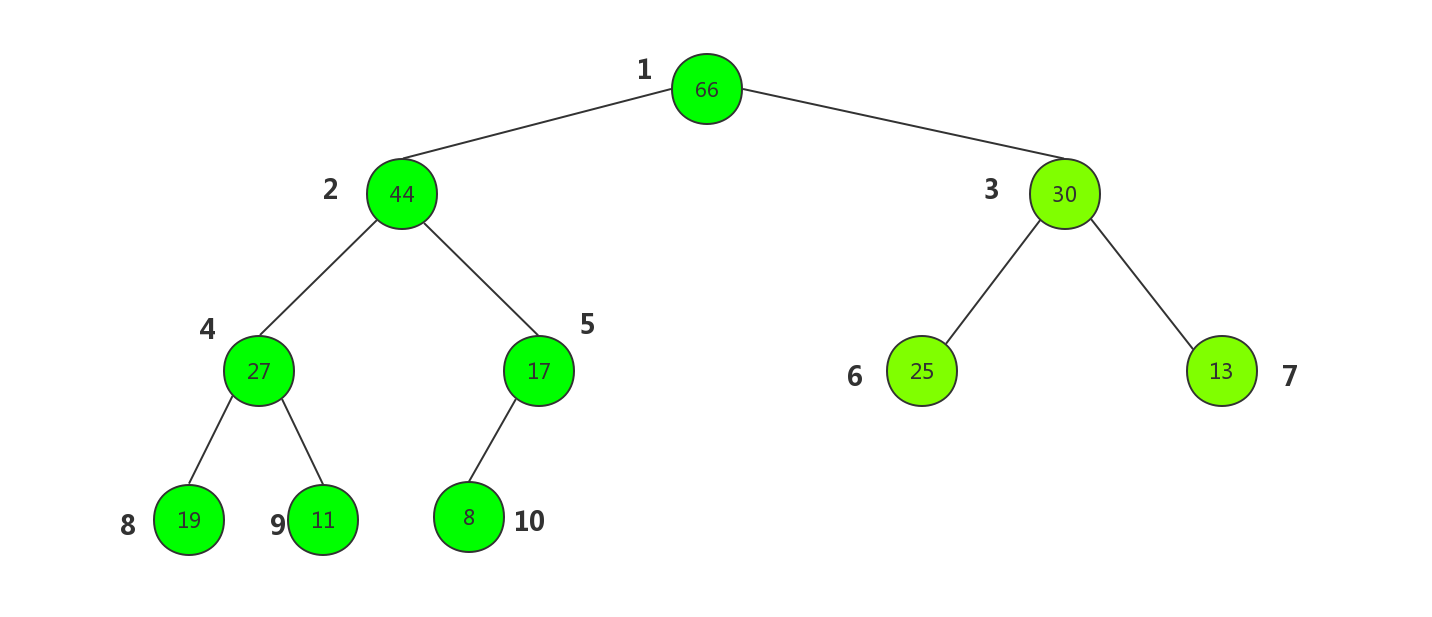
标上编号后,我们发现每个节点的左子节点(如果存在)的序号都是其自身的2倍,右子节点(如果存在)的序号是其自身的2倍加1. 相反,如果已知某个节点的序号,父节点的序号是其自身的二分之一(计算机中整型相除,舍弃余数)下面来用代码构建一个堆的骨骼
public class MaxHeap {
/*
* 堆中有多少元素
*/
private int count;
/*
* 存放堆数据的数组
*/
private Object[] data;
public MaxHeap(int capacity) {
/*
* 因为序号是从1 开始的,我们不用下标是0的这个位置的数
*/
this.data = new Object[capacity + 1];
}
/**
* 返回堆中有多少数据
* @return
*/
public int size() {
return count;
}
/**
* 堆是否还有元素
* @return
*/
public boolean isEmpty() {
return count == 0;
}
}
骨骼是构建好了,乍一看堆中存放的数据是一个object类型的数据, 父子节点按节点值 无法比较,这里再调整一下
public class MaxHeap<T extends Comparable<T>> {
/*
* 堆中有多少元素
*/
private int count;
/*
* 存放堆数据的数组
*/
private Object[] data;
/**
* 堆的容量
*/
private int capacity;
/**
* @param clazz 堆里放的元素的类型
* @param capacity 堆的容量
*/
public MaxHeap(int capacity) {
/*
* 因为序号是从1 开始的,我们不用下标是0的这个位置的数
*/
this.data = new Object[capacity + 1];
this.capacity = capacity;
}
/**
* 返回堆中有多少数据
*
* @return
*/
public int size() {
return count;
}
/**
* 堆是否还有元素
*
* @return
*/
public boolean isEmpty() {
return count == 0;
}
public Object[] getData() {
return data;
}
}
这样骨架算是相对完好了,下面实现向堆中添加数据的过程,首先我们先把上面的二叉树的形式按标号映射成数组的形式如图对比(已经说了0号下标暂时不用)

现在这个大顶堆被映射成数组,所以向堆中插入元素,相当于给数组添加元素,这里我们规定每新插入一个元素就插在当前数组最后面,也即数组最大标 + 1的位置处.对于一颗完全二叉树来说就是插在最后一层的靠左处,如果当前二叉树是一颗满二叉树,则新开辟一层,插在最后一层最左侧.但是这样插入有可能破坏堆的性质. 如插入节点45
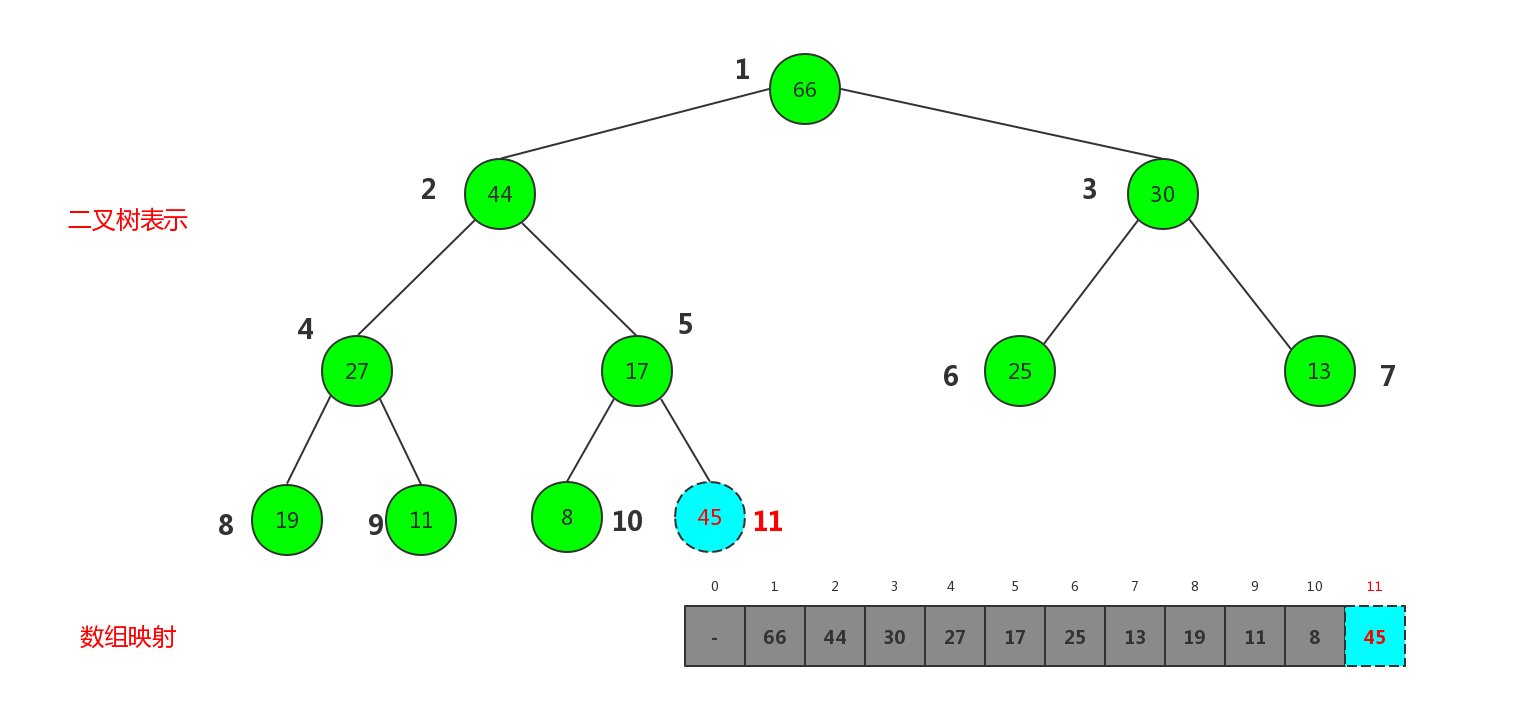
插入新节点后已经破坏了大顶堆的性质,因为45比父节点17大, 这里我们只要把新插入的节点45和父节点17 交换,类似依次比较与父节点的大小做交换即可
第一次交换:
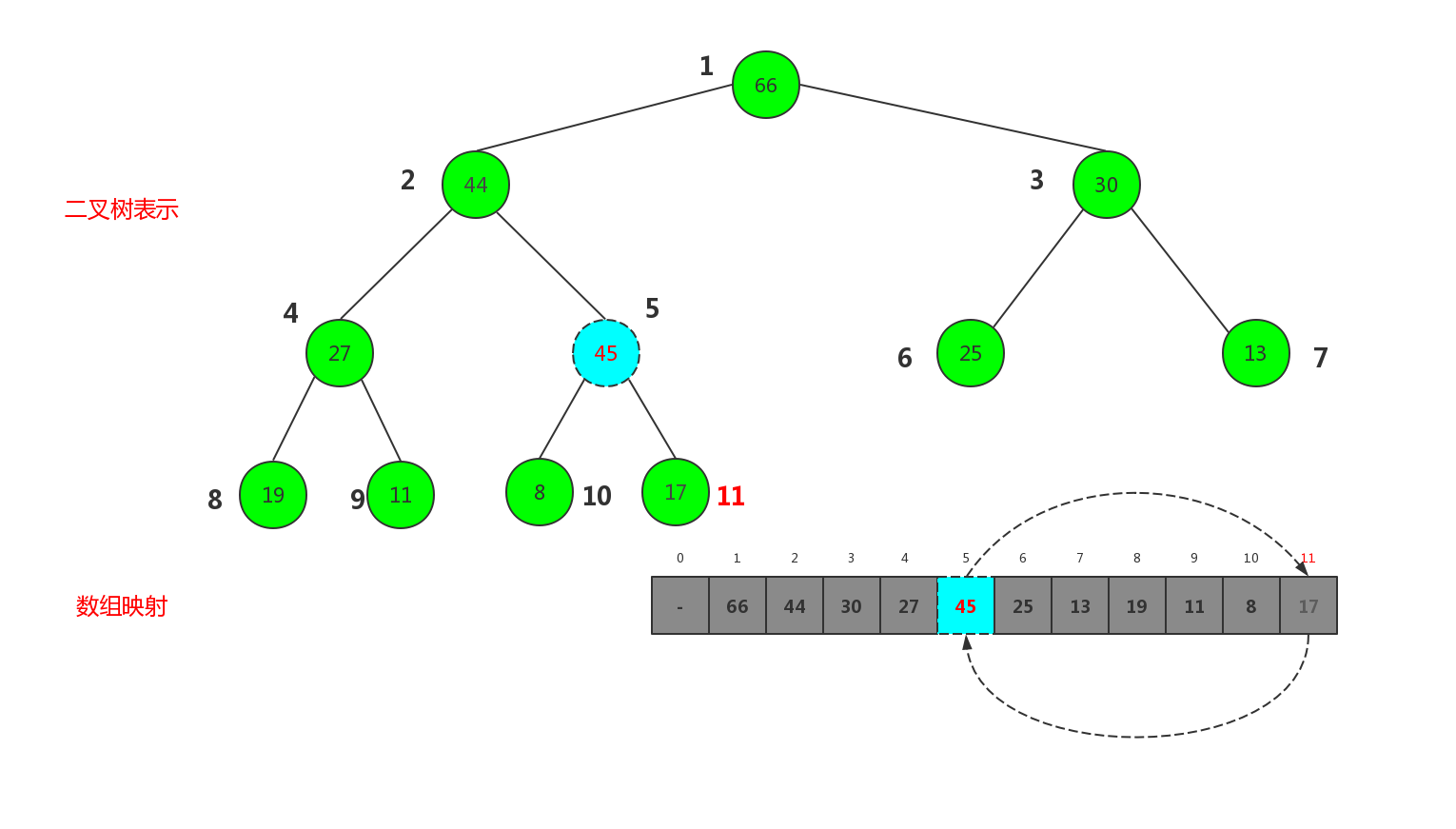
第二次交换:
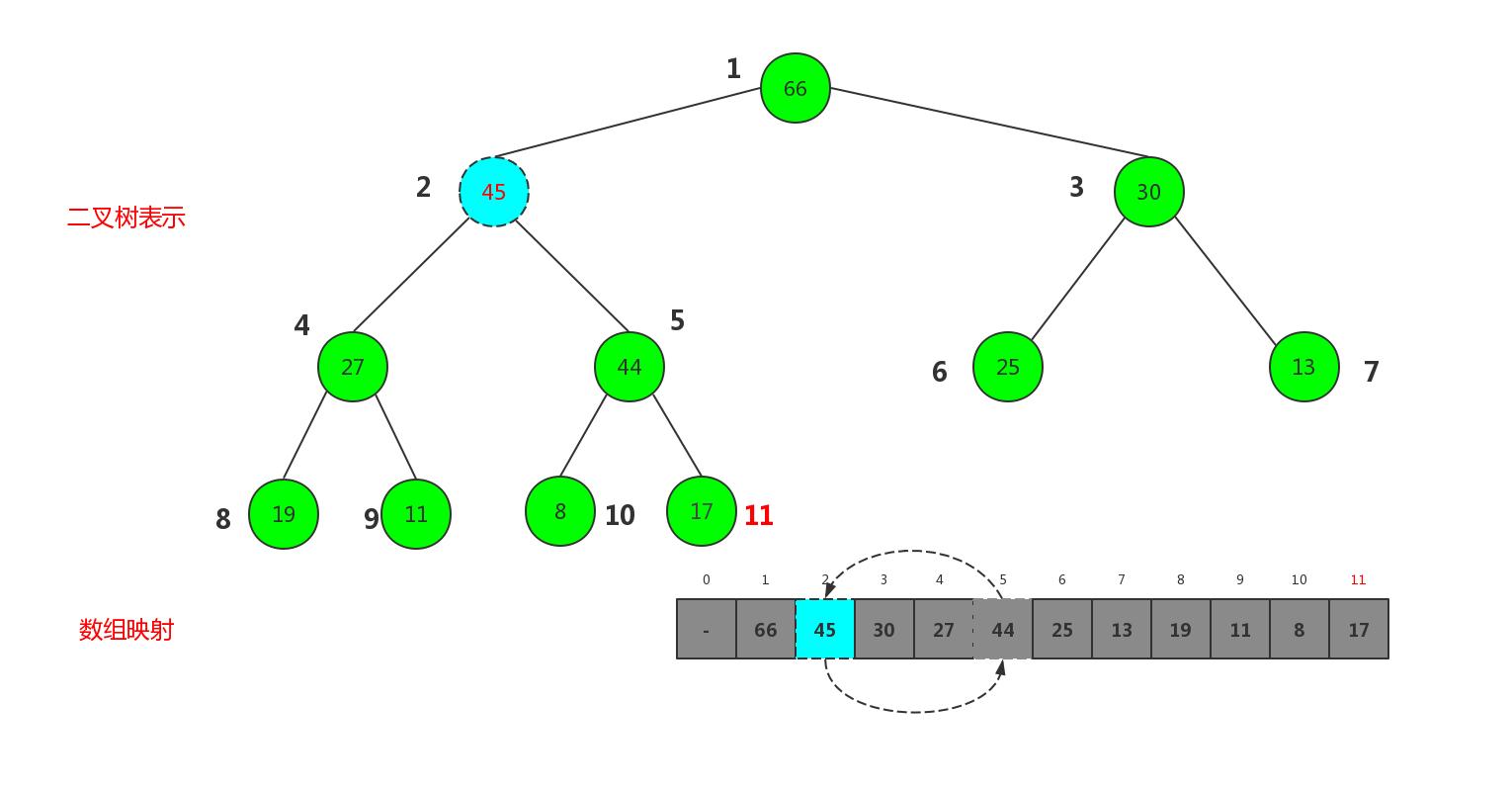
这里我们发现经过两次交换,已经满足了堆的性质,这样我们就完成了一次插入,这个过程,我们发现待插入的元素至底向顶依次向树根上升,我们给这个过程起个名叫shiftUp,用代码实现便是:
/**
* 插入元素t到堆中
* @param t
*/
public void insert(T t) {
//把这个元素插入到数组的尾部,这时堆的性质可能被破坏
data[count + 1] = t;
//插入一个元素,元素的个数增加1
count++;
//移动数据,进行shiftUp操作,修正堆
shiftUp(count); } private void shiftUp(int index) {
while (index > 1 && ((((T) data[index]).
compareTo((T) data[index >> 1]) > 0))) {
swap(index, index >>> 1);
index >>>= 1;
}
} /**
* 这里使用引用交换,防止基本类型值传递
* @param index1
* @param index2
*/
private void swap(int index1, int index2) {
T tmp = (T) data[index1];
data[index1] = data[index2];
data[index2] = tmp;
}
这里有一个隐藏的问题,初始化我们指定了存放数据数组的大小,随着数据不断的添加,总会有数组越界的这一天.具体体现在以上代码 data[count + 1] = t 这一行
/**
* 插入元素t到堆中
* @param t
*/
public void insert(T t) {
//把这个元素插入到数组的尾部,这时堆的性质可能被破坏
data[count + 1] = t; //这一行会引发数组越界异常
//插入一个元素,元素的个数增加1
count++;
//移动数据,进行shiftUp操作,修正堆
shiftUp(count); }
我们可以考虑在插入之前判断一下容量
/**
* 插入元素t到堆中
* @param t
*/
public void insert(T t) {
//插入的方法加入容量限制判断
if(count + 1 > capacity)
throw new IndexOutOfBoundsException("can't insert a new element...");
//把这个元素插入到数组的尾部,这时堆的性质可能被破坏
data[count + 1] = t; //这一行会引发数组越界异常
//插入一个元素,元素的个数增加1
count++;
//移动数据,进行shiftUp操作,修正堆
shiftUp(count); }
至此,整个大顶堆的插入已经还算完美了,来一波儿数据测试一下,应该不是问题
可能上面插入时我们看到有shiftUp这个操作,可能会想到从堆中删除元素是不是shiftDown这个操作. 没错就是shiftDown,只不过是删除堆中元素只能删除根节点元素,对于大顶堆也就是剔除最大的元素.下面我们用图说明一下.

删除掉根节点,那根节点的元素由谁来补呢. 简单,直接剁掉原来数组中最后一个元素,也就是大顶堆中最后一层最后一个元素,摘了补给根节点即可,相应的堆中元素的个数要减一
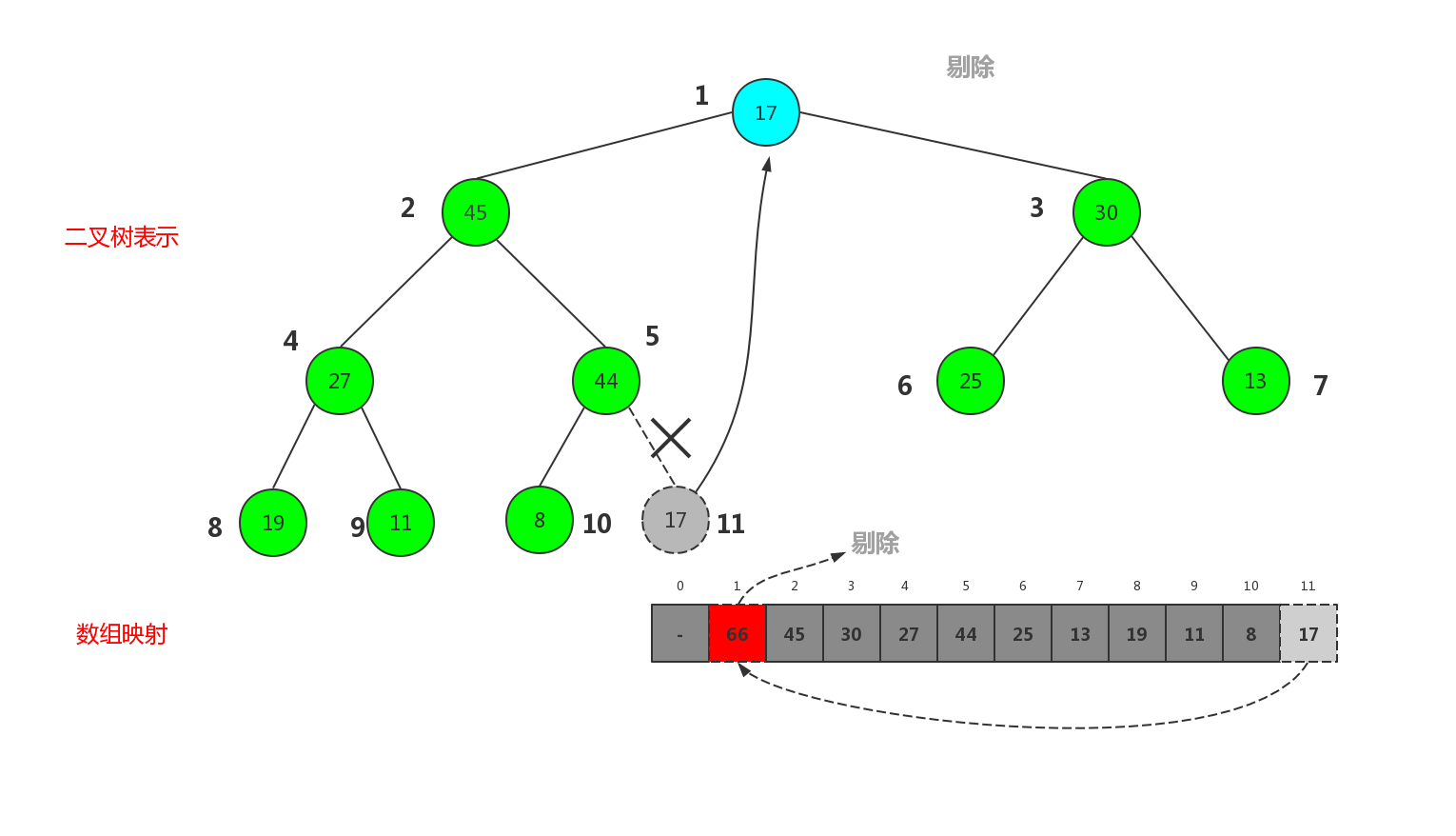
最终我们删除了大顶堆中最大的元素,也就是根节点,堆中序号最大的元素变成了根节点.
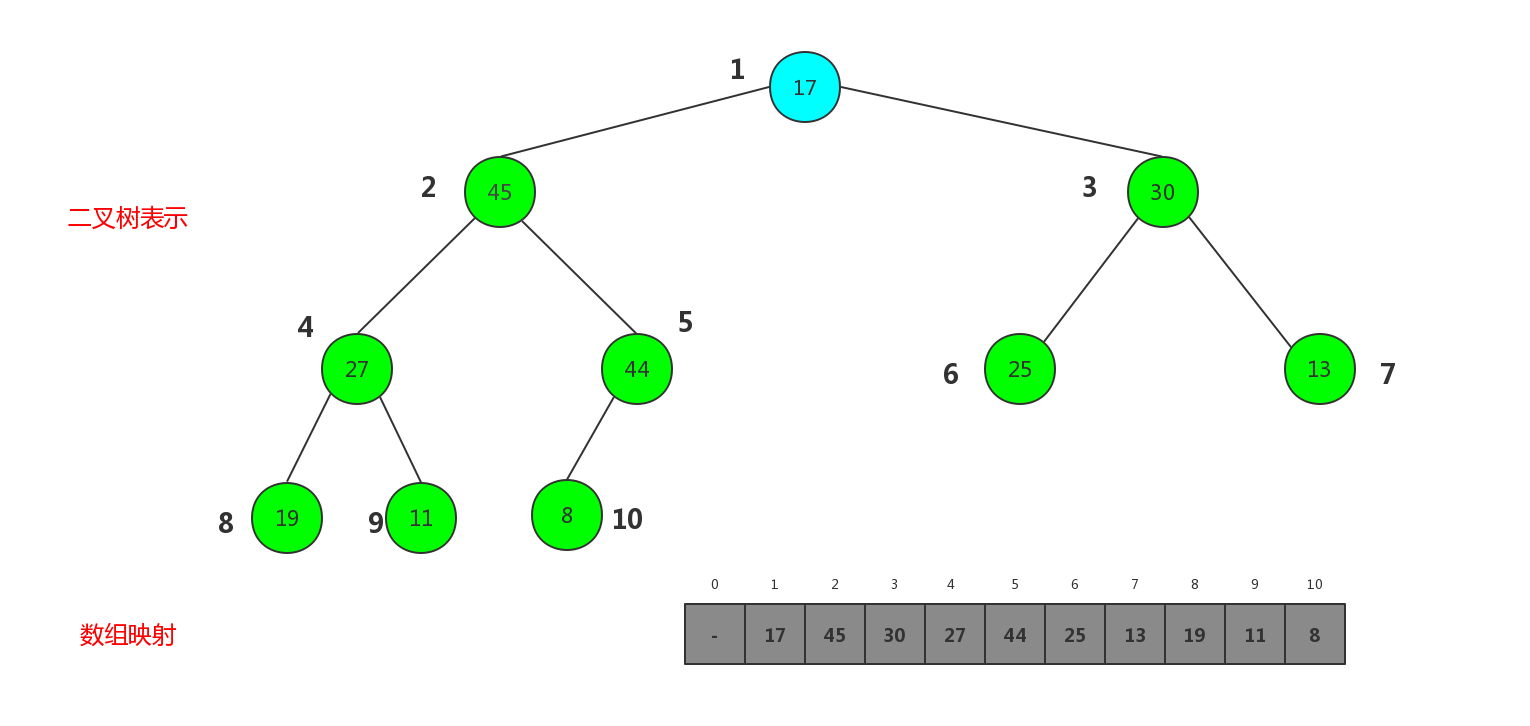
此时整个堆不满足大顶堆的性质,因为根节点17比其子节点小,这时,shiftDown就管用了,只需要把自身与子节点交换即可,可是子节点有两个,与哪个交换呢,如果和右子节点30交换,30变成父节点,比左子节点45小,还是不满足大顶堆的性质.所以应该依次与左子节点最大的那个交换,直至父节点比子节点大才可.所以剔除后新被替换的根节点依次下沉,所以这个过程被称为shiftDown,最终变成
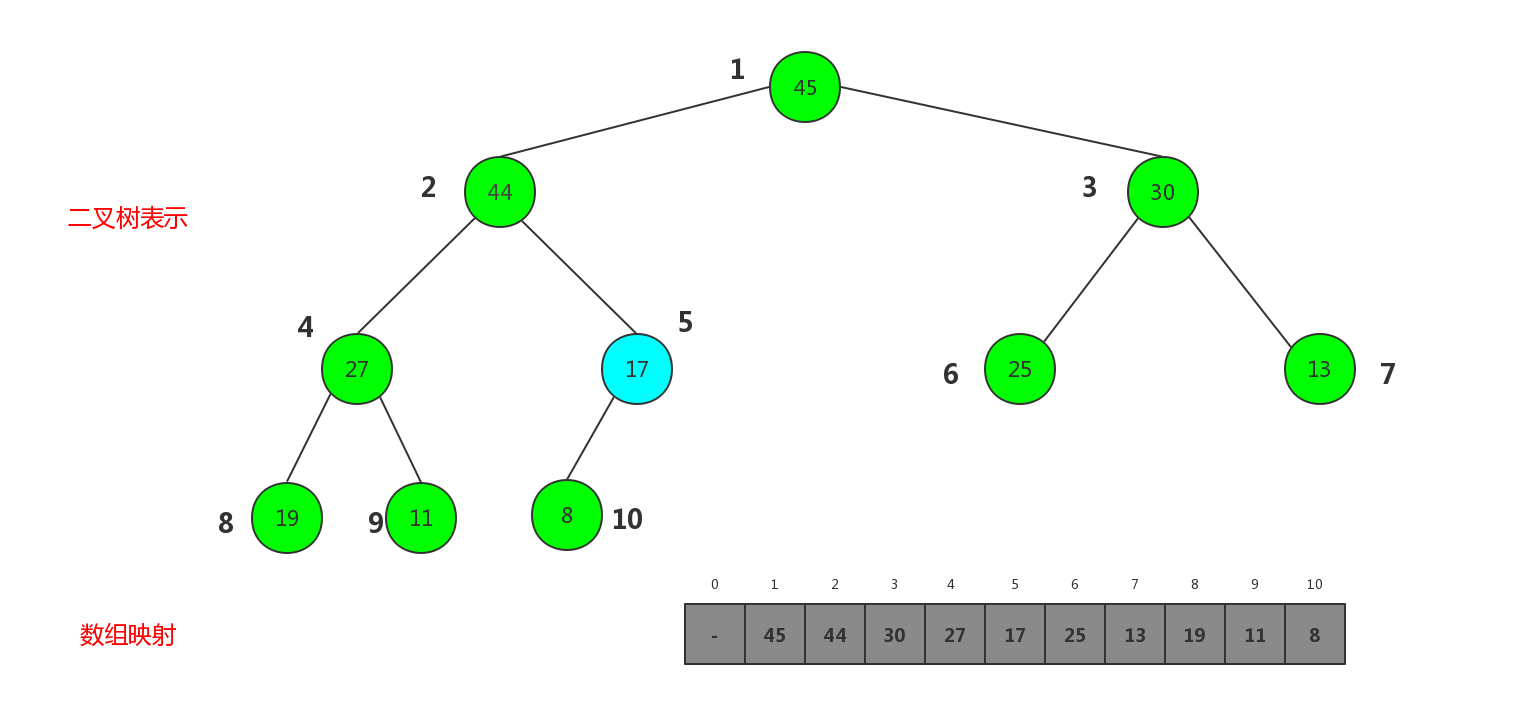
所以移除最大元素的方法实现:
/**
* 弹出最大的元素并返回
*
* @return
*/
public T popMax() {
if (count <= 0)
throw new IndexOutOfBoundsException("empty heap");
T max = (T) data[1];
//把最后一个元素补给根节点
swap(1, count);
//补完后元素个数减一
count--;
//下沉操作
shiftDown(1);
return max;
} /**
* 下沉
*
* @param index
*/
private void shiftDown(int index) {
//只要这个index对应的节点有左子节点(完全二叉树中不存在 一个节点只有 右子节点没有左子节点)
while (count >= (index << 1)) {
//比较左右节点谁大,当前节点跟谁换位置
//左子节点的inedx
int left = index << 1;
//右子节点则是
int right = left + 1;
//如果右子节点存在,且右子节点比左子节点大,则当前节点与右子节点交换
if (right <= count) {
//有右子节点
if ((((T)data[left]).compareTo((T)data[right]) < 0)) {
//左子节点比右子节点小,且节点值比右子节点小
if (((T)data[index]).compareTo((T)data[right]) < 0) {
swap(index, right);
index = right;
} else
break; } else {
//左子节点比右子节点大
if (((T)data[index]).compareTo((T)data[left]) < 0) {
swap(index, left);
index = left;
} else
break;
}
} else {
//右子节点不存在,只有左子节点
if (((T)data[index]).compareTo((T)data[left]) < 0) {
swap(index, left);
index = left;
} else
//index 的值大于左子节点,终止循环
break;
}
}
}
至此,大顶堆的插入和删除最大元素就都实现完了.来写个测试
public static void main(String[] args) {
MaxHeap<Integer> mh = new MaxHeap<Integer>(Integer.class, 12);
mh.insert(66);
mh.insert(44);
mh.insert(30);
mh.insert(27);
mh.insert(17);
mh.insert(25);
mh.insert(13);
mh.insert(19);
mh.insert(11);
mh.insert(8);
mh.insert(45);
Integer[] data = mh.getData();
for (int i = 1 ; i <= mh.count ; i++ ) {
System.err.print(data[i] + " ");
}
mh.popMax();
for (int i = 1 ; i <= mh.count ; i++ ) {
System.err.print(data[i] + " ");
}
}
嗯,还不错,结果跟上面图上对应的数组一样.结果倒是期望的一样,但总感觉上面的shiftDown的代码比shiftUp的代码要多几倍,而且看着很多类似一样的重复的代码, 看着难受.于是乎想个办法优化一下. 对我这种强迫症来说,不干这件事,晚上老是睡不着觉.
思路: 上面我们不断的循环条件是这个index对应的节点有子节点.如果节点堆的性质破坏,最终是要用这个值与其左子节点或者右子节点的值交换,所以我们计算出了左子节点和右子节点的序号.其实不然,我们定义一个抽象的最终要和父节点交换的变量,这个变量可能是左子节点,也可能是右子节点,初始化成左子节点的序号,只有在其左子节点的值小于右子节点,且父节点的值也左子节点,父节点才可能与右子节点,这时让其这个交换的变量加1变成右子节点的序号即可,其他情况则要么和左子节点交换,要么不作交换,跳出循环,所以shiftDown简化成:
/**
* 下沉
*
* @param index
*/
private void shiftDown(int index) {
//只要这个index对应的节点有左子节点(完全二叉树中不存在 一个节点只有 右子节点没有左子节点)
while (count >= (index << 1)) {
//比较左右节点谁大,当前节点跟谁换位置
//左子节点的inedx
int left = index << 1;
//data[index]预交换的index的序号
int t = left;
//如果右子节点存在,且右子节点比左子节点大,则当前节点可能与右子节点交换
if (((t + 1) <= count) && (((T) data[t]).compareTo((T) data[t + 1]) < 0))
t += 1;
//如果index序号节点比t序号的节点小,才交换,否则什么也不作, 退出循环
if (((T) data[index]).compareTo((T) data[t]) >= 0)
break;
swap(index, t);
index = t;
}
}
嗯,还不错,这下完美了.简单多了.其他还有待优化的地方留在下篇讨论
总结
首先复习了堆的应用场景,具体的应用场景代码实现留在下一篇.
引入堆的概念,性质和大顶堆,小顶堆的概念,实现了大顶堆的元素添加和弹出
根据堆的性质和弹出时下沉的规律,优化下沉方法代码.
下一篇优化堆的构建,用代码实现其应用场景,如排序, topN问题,优先队列等
浅谈堆-Heap(一)的更多相关文章
- 浅谈Java中的栈和堆
人们常说堆栈堆栈,堆和栈是内存中两处不一样的地方,什么样的数据存在栈,又是什么样的数据存在堆中? 这里浅谈Java中的栈和堆 首先,将结论写在前面,后面再用例子加以验证. Java的栈中存储以下类型数 ...
- ehcache的heap、off-heap、desk浅谈
ehcache的heap.off-heap.desk浅谈 答: 从读取速度上比较:heap > off-heap > disk heap堆内内存: heap表示使用堆内内存,heap( ...
- 浅谈C#堆栈与托管堆的工作方式(转)
C#初学者经常被问的几道辨析题,值类型与引用类型,装箱与拆箱,堆栈,这几个概念组合之间区别,看完此篇应该可以解惑. 俗话说,用思想编程的是文艺程序猿,用经验编程的是普通程序猿,用复制粘贴编程的是2B程 ...
- JVM的堆(heap)、栈(stack)和方法区(method)
JVM主要由类加载器子系统.运行时数据区(内存空间).执行引擎以及与本地方法接口等组成.其中运行时数据区又由方法区Method Area.堆Heap.Java stack.PC寄存器.本地方法栈组成. ...
- 浅谈new operator、operator new和placement new 分类: C/C++ 2015-05-05 00:19 41人阅读 评论(0) 收藏
浅谈new operator.operator new和placement new C++中使用new来产生一个存在于heap(堆)上对象时,实际上是调用了operator new函数和placeme ...
- 浅谈JavaScript中的内存管理
一门语言的内存存储方式是我们学习他必须要了解的,接下来让我浅谈一下自己对他的认识. 首先说,JavaScript中的变量包含两种两种类型: 1)值类型或基本类型:undefined.null.numb ...
- 浅谈SQL Server数据内部表现形式
在上篇文章 浅谈SQL Server内部运行机制 中,与大家分享了SQL Server内部运行机制,通过上次的分享,相信大家已经能解决如下几个问题: 1.SQL Server 体系结构由哪几部分组成? ...
- 浅谈SQL Server---1
浅谈SQL Server优化要点 https://www.cnblogs.com/wangjiming/p/10123887.html 1.SQL Server 体系结构由哪几部分组成? 2.SQL ...
- 浅谈javascript的原型及原型链
浅谈javascript的原型及原型链 这里,我们列出原型的几个概念,如下: prototype属性 [[prototype]] __proto__ prototype属性 只要创建了一个函数,就会为 ...
随机推荐
- influxdb api
https://influxdb-python.readthedocs.io/en/latest/examples.html
- VisualGDB系列1:VisualGDB总体概述
根据VisualGDB官网(https://visualgdb.com)的帮助文档大致翻译而成.主要是作为个人学习记录.有错误的地方,Robin欢迎大家指正. 本文总体介绍VisualGDB能给你带来 ...
- event.keyCode 事件属性
转自:http://www.runoob.com/jsref/event-key-keycode.html <!DOCTYPE html> <html> <head> ...
- C#笔记(二)
转换操作符:操作符重载,可自定义实现从一种类型到另一种类型的显示或者隐式转换 : true/false也可进行操作符重载: LINQ中大部分查询运算符都有一个非常重要的特性:延迟执行.这意味着,他们不 ...
- nfs(Network FileSystem)的简单配置
如果想要在window和linux之间共享文件,那么用samba.如果仅仅想在Unix like系统之间共享文件,那么可以用NFS. 这篇文章分为两个部分,第一部分只是简单的用:照着写的步骤一步步来就 ...
- Vmware克隆Centos 不能上网的解决方案
问题:用Vmware克隆Centos 6.4后,发现系统内只有eth1,而且/etc/sysconfig/network-scripts/下只有,ifcfg-eth0文件,虽然可以上网,但无法设置静态 ...
- webAPI中使用FormsAuthenticationTicket作为登录权限票据
最近在做的项目得到经验,在做登录的时候,使用FormsAuthenticationTicket, 登录成功以后生成cookia作为登录态维护,票据作为调用其他接口的凭据,票据生成后传到前台作为调用接口 ...
- 6.7 使用IDEA导入工程
打开IDEA->File->new -> Project from existing ..->选择你的工程,导入: 请注意,在130或者40上面的项目并不是最新的,sunny也 ...
- Windows使用Github
首先,你需要执行下面两条命令,作为 git 的基础配置,作用是告诉 git 你是谁,你输入的信息将出现在你创建的提交中. git config --global user.name "你的名 ...
- Object—C 块在函数中作为参数时的分析
暂时对这个有了一些粗浅的理解,记下来一边后面学习时学习,改正. 先举个例子: A类: .h文件: @interface A : NSObject - (void)Paly1:(void (^)(do ...