应用.Net+Consul维护RabbitMq的高可用性
懒人学习的过程就是工作中老大让干啥让做啥就研究研究啥,国庆放假回来的周末老大通过钉钉给我布置了个任务, RabbitMQ高可用解决方案,我想说钉钉太坑了:

这是国庆过后9号周日晚上下班给的任务,我周一看到的时候一看,下周五,那岂不是21号,时间是如此的充裕!那不还早呢么。。恰巧同学要面试了9号晚上一起吃饭,然后问了我几个算法,然后被鄙视了。。他说我一个前端都比你做后台的算法牛逼,你请客吧-。-于是周一到周三光学算法了(程序员为了吹牛逼,哪有啥节操啊)直到周四老大说,明天任务到期了!研究咋样了!此时才恍然大悟,钉钉你个坑货,下周五是14号!!
RabbitMQ 高可用集群
简单配置
对于RabbitMQ 高可用集群的说明,我觉得这篇文章讲的挺详细的,就不说了。配置集群的方式看官网就可以了 ,为了采取所谓的Active/Active方案,所以只能选镜像模式了(3.x版本以上才支持).再抄一段解释过来(与普通集群相比,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在 consumer 取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用),在搭建好RabbitMq集群以后,
镜像模式可以通过命令行为队列添加同步策略,比如
为所有队列应用镜像模式的策略
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
或者指定指定队列名的:
rabbitmqctl set_policy yu-ha "^yu" '{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}'
或者直接在管理页面添加
点击Admin菜单-->右侧的Policies选项-->左侧最下下边的Add / update a policy

name就是队列名,Pattern就是匹配的规则,比如写个^yu就是以yu开头的队列,ha-mode=啥就是会同步什么队列,比如=all的话就是同步所有匹配的队列。
然后新建队列的时候就可以指定那台机器上跑主队列了。
所谓的坑
还是抄一下这篇文章的内容,常用的手段就是通过HAProxy+KeepAlive保证RabbitMq的集群高可用:
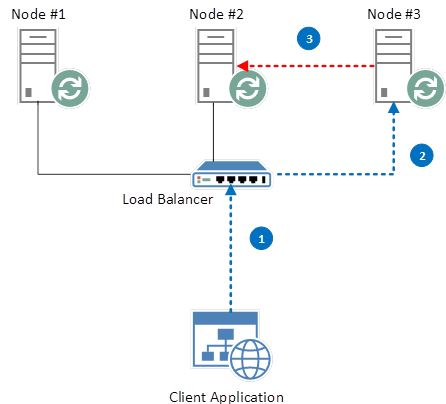
创建 queue 的过程:
- LB 将 client request 分发到 node 2,client 创建队列 “NewQueue”,然后开始向其中放入 message。
- 最终,后端服务会对 node 2 上的 “NewQueue” 创建一个快照,并在一段时间内将其拷贝到node 1 和 3 上。这时候,node2 上的队列是 master Queue,node 1 和 3 上的队列是 slave queue。
假如现在 node2 宕机了:
- node 2 不再响应心跳,它会被认为已经被从集群中移出了
- node 2 上的 master queue 不再可用
- RabbitMQ 将 node 1 或者 3 上的 salve instance 升级为 master instance
假设 master queue 还在 node 2 上,客户端通过 LB 访问该队列:
- 客户端连接到集群,要访问 “NewQueue” 队列
- LB 根据配置的轮询算法将请求分发到一个节点上
- 假设客户端请求被转到 node 3 上
- RabbitMQ 发现 “NewQueue” master node 是 node 2
- RabbitMQ 将消息转到 node 2 上
- 最终客户端成功连接到 node 2 上的 master 队列
可见,这种配置下,2/3 的客户端请求需要重定向,这会造成大概率的访问延迟,但是终究访问还是会成功的。要优化的话,总共有两种方式:
- 直接连到 master queue 所在的节点,这样就不需要重定向了。但是对这种方式,需要提前计算,然后告诉客户端哪个节点上有 master queue。
- 尽可能地在所有节点间平均分布队列,减少重定向概率
为了避免这种n-1/n的这种重定向,知道Master queue所在的节点很重要啊,接下来就不抄了。
思路
大致的意思就是这张图:

1.将RabbitMq注册到Consul中(步骤1),通过Consul对RabbitMq进行健康监测,同时Consul提供配置中心的服务,可以存储一些RabbitMq的配置信息,比如队列账号,密码,队列主机名,所在Ip等,举个例子:
将RabbitMq服务注册到Consul:
{
"services": [{
"id":"rabbit@rabbitmq1",
"name":"RabbitMqServer",
"tags":["rabbitMq"],
"address": "192.168.1.101",
"port": ,
"checks": [
{
"Http": "http://192.168.1.101:15672/",
"interval": "10s"
}
]
},
{
"id":"rabbit@rabbitmq2",
"name":"RabbitMqServer",
"tags":["rabbitMq"],
"address": "192.168.1.102",
"port": ,
"checks": [
{
"Http": "http://192.168.1.102:15672/",
"interval": "10s"
}
]
}
]
}
将RabbitMq的队列信息存入到Consul中:

2.业务服务需要配置QueueName+VirthHost,通过步骤2从RabbitMq网关进行队列信息的获取,然后才能通过步骤5与队列进行推拉操作,这里可以获取可用队列对应的Master队列所在的节点信息,避免n-1/n这种接受推送转发的问题。
3.RabbitMq网关接受到业务服务的请求后,通过Consul获取集群中任意一个健康的RabbitMq队列的信息(Consul提供的健康监测功能),然后根据该队列获得与RabbitMq通信的WebApi,RabbitMq的Http Api文档提供了获取队列详情的接口,比如获取队列对用的Master信息是可用通过接口:http://127.0.0.1:15672/api/queues/%2F/yu_queue,%2F对应的是VirthHost,是/的转码,yu_queue是队列名,这俩参数通过业务服务请求Api时提供,通过Api返回的Json字符串中包含了该队列Master的节点的对用信息,其中node属性对应的就是rabbitmq的节点名,如:rabbit@rabbitmq1,然后可以通过之前在consul中配置的RabbitMq信息来查找该节点对用的队列信息返回给业务服务。
这里会有个坑需要注意:
访问RabbitMq的Http Api是需要身份验证的,这个Basic验证的Token获取查了查文档没找到- -
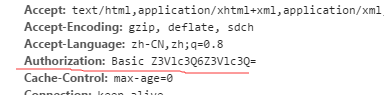
后来惊奇发现。。 Convert.ToBase64String(Encoding.ASCII.GetBytes(userName + ":" + password))); 哎。。不想多说了。。。
还有个Api参数中带/的问题,.net 4.5以上的版本用HttpClient没啥问题,4.5以下版本或者用HttpWebRequest的时候需要对Uri做下处理
public static void ForceCanonicalPathAndQuery(Uri uri)
{
string paq = uri.PathAndQuery; // need to access PathAndQuery
FieldInfo flagsFieldInfo = typeof(Uri).GetField("m_Flags", BindingFlags.Instance | BindingFlags.NonPublic);
ulong flags = (ulong)flagsFieldInfo.GetValue(uri);
flags &= ~((ulong)0x30); // Flags.PathNotCanonical|Flags.QueryNotCanonical
flagsFieldInfo.SetValue(uri, flags);
}
附加说明:
其实思路很简单,不过明明可以通过封装一个SDK(况且本来就得封装- -)就完成的事情为什么还要牵扯出Consul和多余的一个RabbitMq网关呢,况且有了RabbitMq网关岂不是说还要单点问题了?!
针对单点问题。。我觉得部署几份无状态的网关还是没啥压力的吧。。SKD封装的时候自己轮训去吧!
对于为什么要用到Consul,一方面是为了健康监测,健康监测可以让Consul通过Consul Http Api直接获取可用的RabbitMq的Http Api信息,还有就是配置中心,业务服务通过配置队列名,VirthHost,和获取队列服务的RabbitMq网关即可,RabbirMq网关负责通过配置中心获取队列信息,配置中心的数据是动态的,更新起来也比较方便。
对于为啥不通过SDK直连RabbitMq的Api而是通过网关作为一个中间代理,在通过Consul获取队列信息时可以做个定时缓存,而且像队列的用户名密码的这种信息通过业务服务配置的话维护不方便,业务服务通过SDK直接通过Consul获取的话,依赖关系也会变得略微错综复杂。通过RabbitMq的Api也可以动态获取队列的集群节点信息,权限信息等,在业务服务SDK里定期更新也未尝不可,但SDK终究变复杂了,你干那个多不累么。。
为什么参数要VirthHost+QueueName,不同部门的人总归不是同一个人。。
正在纠结的问题:
针对这种思路,对于RabbitMq中的Routing模式和Topic模式会有问题,单routekey对应单队列时可以通过队列获取Exhange下该routekey有效发送到某台服务器上的队列上,假如该routekey绑定的队列分布在多台服务器上,并且这些队列的主从分布在多台服务器上时,我通过获取到的“Master队列”只能针对某一队列时真Master,对于其他队列如果Master不在该ip上还是会存在转发的问题。这个问题在拉数据时没啥问题(拉数据我是需要队列名的!),推数据时只用到Exchange+RouteKey,谁还管你的队列是主是从呢?
参考链接:
http://www.cnblogs.com/sammyliu/p/4730517.html
https://insidethecpu.com/2014/11/17/load-balancing-a-rabbitmq-cluster/
应用.Net+Consul维护RabbitMq的高可用性的更多相关文章
- RabbitMQ镜像队列初始化连接时的“优化”
之前发过一篇帖子应用.Net+Consul维护RabbitMq的高可用性,然后最近老大问我当初我这么搞是抽的什么想法- -然后顺便贴了两行C#代码: var factory = new Connect ...
- RabbitMQ分布式集群架构和高可用性(HA)
(一) 功能和原理 设计集群的目的 允许消费者和生产者在RabbitMQ节点崩溃的情况下继续运行 通过增加更多的节点来扩展消息通信的吞吐量 1 集群配置方式 RabbitMQ可以通过三种方法来部署分布 ...
- 怎么保证RabbitMQ和kafuka集群的高可用性?
rabbitMQ有三种模式:单机模式,普通集群模式,镜像集群模式 RabbitMQ的高可用性 RabbitMQ是比较有代表性的,因为是基于主从做高可用性的,我们就以他为例子讲解第一种MQ的高可用性 ...
- Kafka、ActiveMQ、RabbitMQ、RocketMQ 区别以及高可用原理
为什么使用消息队列 其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么? 面试官问你这个问题,期望的一个回答是说,你们公司有个什么业务场景,这个业务 ...
- RabbitMQ面试题
1.为什么要引入MQ系统,直接读写数据库不行吗?其实就是问问你消息队列都有哪些使用场景,然后你项目里具体是什么场景,说说你在这个场景里用消息队列是什么? 面试官问你这个问题,期望的一个回答是说,你们公 ...
- Centos 7 RabbitMQ + Haproxy 集群高可用部署
一. 功能和原理介绍 RabbitMQ是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python.Ruby..NET.Java.JMS.C.PHP.ActionSc ...
- RabbitMQ面试问答(子文章)(持续更新)
-----> 总文章 入口 文章目录 [-----> 总文章 入口](https://blog.csdn.net/qq_37214567/article/details/90174445) ...
- springboot(八):RabbitMQ详解
RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用. 消息中间件在互联网公司的使用中越来越多,刚才还看到新闻阿里将RocketMQ捐献给了apa ...
- linux下安装rabbitmq
1.安装erlang虚拟机 Rabbitmq基于erlang语言开发,所有需要安装erlang虚拟机.安装erlang有两种方式: 第一种:使用yum安装: wget -O /etc/yum.repo ...
随机推荐
- Javascript中的valueOf与toString
基本上,javascript中所有数据类型都拥有valueOf和toString这两个方法,null除外.它们俩解决javascript值运算与显示的问题,本文将详细介绍,有需要的朋友可以参考下. t ...
- 初识git版本控制系统
当下git分布式版本控制系统越来越火,掌握git也是必须的一个技能.因此,对git做了如下学习. Git初级指南 1. 先安装git.(ps:在select cmponents处要勾选Git Bash ...
- 敏捷转型历程 - Sprint3 Grooming
我: Tech Leader 团队:团队成员分布在两个城市,我所在的城市包括我有4个成员,另外一个城市包括SM有7个成员.另外由于我们的BA离职了,我暂代IT 的PO 职位.PM和我在一个城市,但他不 ...
- nginx代理https站点(亲测)
nginx代理https站点(亲测) 首先,我相信大家已经搞定了nginx正常代理http站点的方法,下面重点介绍代理https站点的配置方法,以及注意事项,因为目前大部分站点有转换https的需要所 ...
- BZOJ 1391: [Ceoi2008]order [最小割]
1391: [Ceoi2008]order Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 1509 Solved: 460[Submit][Statu ...
- Linux不能上网ping:unknown host问题怎么解决?
Linux不能上网提示ping:unknown host 检查步骤 Linux系统跟windows平台有所不同的是,为了更好的做网络服务应用.Linux下多用于网络服务器,而且操作界面是字符界面.对于 ...
- 最新Angular2案例rebirth开源
在过去的几年时间里,Angular1.x显然是非常成功的.但由于最初的架构设计和Web标准的快速发展,逐渐的显现出它的滞后和不适应.这些问题包括性能瓶颈.滞后于极速发展的Web标准.移动化多平台应用, ...
- 自己写jquery插件之模版插件高级篇(一)
需求场景 最近项目改版中,发现很多地方有这样一个操作(见下图gif动画演示),很多地方都有用到.这里不讨论它的用户体验怎么样. 仅仅是从复用的角度,如果每个页面都去写text和select元素,两个b ...
- JavaScript的基准测试-不服跑个分?
原文:Bulletproof JavaScript benchmarks 做JavaScript的基准测试并没有想的那么简单.即使不考虑浏览器差异所带来的影响,也有很多难点-或者说陷阱需要面对. 这是 ...
- ABP(现代ASP.NET样板开发框架)系列之7、ABP Session管理
点这里进入ABP系列文章总目录 基于DDD的现代ASP.NET开发框架--ABP系列之7.ABP Session管理 ABP是“ASP.NET Boilerplate Project (ASP.NET ...