[Hadoop源码解读](三)MapReduce篇之Job类
下面,我们只涉及MapReduce 1,而不涉及YARN。
当我们在写MapReduce程序的时候,通常,在main函数里,我们会像下面这样做。建立一个Job对象,设置它的JobName,然后配置输入输出路径,设置我们的Mapper类和Reducer类,设置InputFormat和正确的输出类型等等。然后我们会使用job.waitForCompletion()提交到JobTracker,等待job运行并返回,这就是一般的Job设置过程。JobTracker会初始化这个Job,获取输入分片,然后将一个一个的task任务分配给TaskTrackers执行。TaskTracker获取task是通过心跳的返回值得到的,然后TaskTracker就会为收到的task启动一个JVM来运行。
Configuration conf = getConf();
Job job = new Job(conf, "SelectGradeDriver");
job.setJarByClass(SelectGradeDriver.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setMapperClass(SelectGradeMapper.class);
job.setReducerClass(SelectGradeReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(InstituteAndGradeWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(InstituteAndGradeWritable.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true)? 0 : 1);
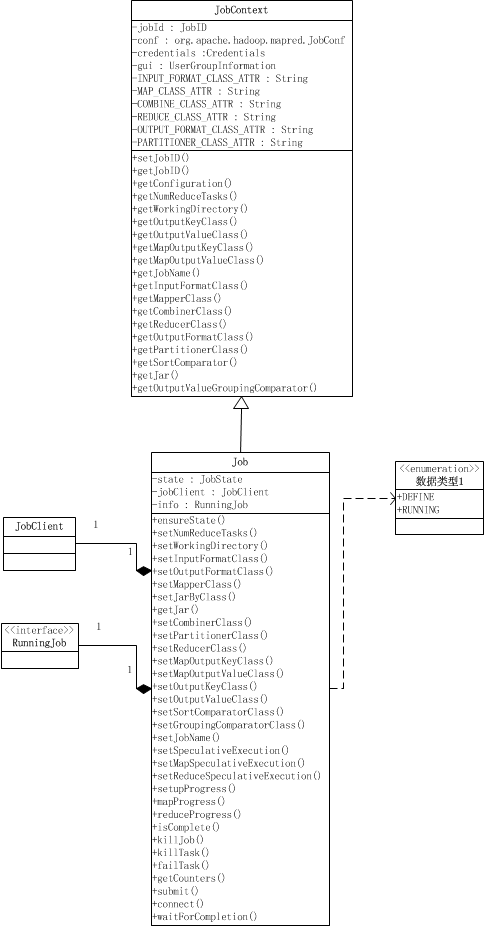
Job其实就是提供配置作业、获取作业配置、以及提交作业的功能,以及跟踪作业进度和控制作业。Job类继承于JobContext类。JobContext提供了获取作业配置的功能,如作业ID,作业的Mapper类,Reducer类,输入格式,输出格式等等,它们除了作业ID之外,都是只读的。 Job类在JobContext的基础上,提供了设置作业配置信息的功能、跟踪进度,以及提交作业的接口和控制作业的方法。
public class Job extends JobContext {
public static enum JobState {DEFINE, RUNNING};
private JobState state = JobState.DEFINE;
private JobClient jobClient;
private RunningJob info;
public float setupProgress() throws IOException {
ensureState(JobState.RUNNING);
return info.setupProgress();
}
public float mapProgress() throws IOException {
ensureState(JobState.RUNNING);
return info.mapProgress();
}
public float reduceProgress() throws IOException {
ensureState(JobState.RUNNING);
return info.reduceProgress();
}
public boolean isComplete() throws IOException {
ensureState(JobState.RUNNING);
return info.isComplete();
}
public boolean isSuccessful() throws IOException {
ensureState(JobState.RUNNING);
return info.isSuccessful();
}
public void killJob() throws IOException {
ensureState(JobState.RUNNING);
info.killJob();
}
public TaskCompletionEvent[] getTaskCompletionEvents(int startFrom
) throws IOException {
ensureState(JobState.RUNNING);
return info.getTaskCompletionEvents(startFrom);
}
public void killTask(TaskAttemptID taskId) throws IOException {
ensureState(JobState.RUNNING);
info.killTask(org.apache.hadoop.mapred.TaskAttemptID.downgrade(taskId),
false);
}
public void failTask(TaskAttemptID taskId) throws IOException {
ensureState(JobState.RUNNING);
info.killTask(org.apache.hadoop.mapred.TaskAttemptID.downgrade(taskId),
true);
}
public Counters getCounters() throws IOException {
ensureState(JobState.RUNNING);
return new Counters(info.getCounters());
}
public void submit() throws IOException, InterruptedException,
ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
// Connect to the JobTracker and submit the job
connect();
info = jobClient.submitJobInternal(conf);
super.setJobID(info.getID());
state = JobState.RUNNING;
}
private void connect() throws IOException, InterruptedException {
ugi.doAs(new PrivilegedExceptionAction<Object>() {
public Object run() throws IOException {
jobClient = new JobClient((JobConf) getConfiguration());
return null;
}
});
}
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) {
jobClient.monitorAndPrintJob(conf, info);
} else {
info.waitForCompletion();
}
return isSuccessful();
}
//lots of setters and others
}
一个Job对象有两种状态,DEFINE和RUNNING,Job对象被创建时的状态时DEFINE,当且仅当Job对象处于DEFINE状态,才可以用来设置作业的一些配置,如Reduce task的数量、InputFormat类、工作的Mapper类,Partitioner类等等,这些设置是通过设置配置信息conf来实现的;当作业通过submit()被提交,就会将这个Job对象的状态设置为RUNNING,这时候作业以及提交了,就不能再设置上面那些参数了,作业处于调度运行阶段。处于RUNNING状态的作业我们可以获取作业、map task和reduce task的进度,通过代码中的*Progress()获得,这些函数是通过info来获取的,info是RunningJob对象,它是实际在运行的作业的一组获取作业情况的接口,如Progress。
在waitForCompletion()中,首先用submit()提交作业,然后等待info.waitForCompletion()返回作业执行完毕。verbose参数用来决定是否将运行进度等信息输出给用户。submit()首先会检查是否正确使用了new API,这通过setUseNewAPI()检查旧版本的属性是否被设置来实现的[设置是否使用newAPI是因为执行Task时要根据使用的API版本来执行不同版本的MapReduce,在后面讲MapTask时会说到],接着就connect()连接JobTracker并提交。实际提交作业的是一个JobClient对象,提交作业后返回一个RunningJob对象,这个对象可以跟踪作业的进度以及含有由JobTracker设置的作业ID。
getCounter()函数是用来返回这个作业的计数器列表的,计数器被用来收集作业的统计信息,比如失败的map task数量,reduce输出的记录数等等。它包括内置计数器和用户定义的计数器,用户自定义的计数器可以用来收集用户需要的特定信息。计数器首先被每个task定期传输到TaskTracker,最后TaskTracker再传到JobTracker收集起来。这就意味着,计数器是全局的。
关于Counter相关的类,为了保持篇幅简短,放在下一篇讲。
[Hadoop源码解读](三)MapReduce篇之Job类的更多相关文章
- [Hadoop源码解读](六)MapReduce篇之MapTask类
MapTask类继承于Task类,它最主要的方法就是run(),用来执行这个Map任务. run()首先设置一个TaskReporter并启动,然后调用JobConf的getUseNewAPI()判断 ...
- Hadoop源码解读系列目录
Hadoop源码解读系列 1.hadoop源码|common模块-configuration详解2.hadoop源码|core模块-序列化与压缩详解3.hadoop源码|core模块-远程调用与NIO ...
- go语言 nsq源码解读三 nsqlookupd源码nsqlookupd.go
从本节开始,将逐步阅读nsq各模块的代码. 读一份代码,我的思路一般是: 1.了解用法,知道了怎么使用,对理解代码有宏观上有很大帮助. 2.了解各大模块的功能特点,同时再想想,如果让自己来实现这些模块 ...
- Hadoop2源码分析-MapReduce篇
1.概述 前面我们已经对Hadoop有了一个初步认识,接下来我们开始学习Hadoop的一些核心的功能,其中包含mapreduce,fs,hdfs,ipc,io,yarn,今天为大家分享的是mapred ...
- [Hadoop源码解读](一)MapReduce篇之InputFormat
平时我们写MapReduce程序的时候,在设置输入格式的时候,总会调用形如job.setInputFormatClass(KeyValueTextInputFormat.class);来保证输入文件按 ...
- [Hadoop源码解读](五)MapReduce篇之Writable相关类
前面讲了InputFormat,就顺便讲一下Writable的东西吧,本来应当是放在HDFS中的. 当要在进程间传递对象或持久化对象的时候,就需要序列化对象成字节流,反之当要将接收到或从磁盘读取的字节 ...
- spring beans源码解读之--总结篇
spring beans下面有如下源文件包: org.springframework.beans, 包含了操作java bean的接口和类.org.springframework.beans.anno ...
- Vue.js 源码分析(三) 基础篇 模板渲染 el、emplate、render属性详解
Vue有三个属性和模板有关,官网上是这样解释的: el ;提供一个在页面上已存在的 DOM 元素作为 Vue 实例的挂载目标 template ;一个字符串模板作为 Vue 实例的标识使用.模板将会 ...
- jQuery源码解读三选择器
直接上jQuery源码截取代码 // Map over jQuery in case of overwrite _jQuery = window.jQuery, // Map over the $ i ...
- Python Web Flask源码解读(三)——模板渲染过程
关于我 一个有思想的程序猿,终身学习实践者,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. Github:https:/ ...
随机推荐
- 2) LINQ编程技术内幕--yield return
yield return 使用.NET的状态机生成器 yield return关键词组自动实现IDisposable,使用这个可枚举的地方, 还存在一个隐含的try finally块. 示例代码: c ...
- 14_Request对象
[HttpServletRequest简介] HttpServletRequest对象代表客户端的请求,当客户端通过HTTP协议访问服务器时,HTTP请求头中的所有信息都封装在这个对象中,开发人员通过 ...
- C++输入结束
通过判断输入是否等于EOF,可以结束输入. EOF 是个宏,其意思是:End Of File,文件尾标志. 从数值上来看,就是整数-1. 在C语言的头文件中对其进行了宏定义: libio.h: ...
- Objective-C 之同步请求、异步请求、GET请求、POST请求
本篇文章由:http://www.sollyu.com/objective-c-synchronization-requests-requests-for-asynchronous-requests- ...
- HTML5之图像处理
--- 内嵌图像 - drawImage可以绘制图像context.drawImage(image,dx,dy)context.drawImage(image,dx,dy,dw,dh)context. ...
- 判断UserAgent是否来自微信
iso: Mozilla/5.0 (iPhone; CPU iPhone OS 7_0_4 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko ...
- js实现克隆一个对象
var app={}; app.cloneobj= function(obj){ var o; if(typeof obj == "object"){ if(obj===null) ...
- 我对TCP CDG拥塞控制算法的改进和优化
其实这不是我的优化,我是借用了BBR之力. 借了什么力呢?这是我一再强调的,BBR最大的共享不是为Linux贡献了一个TCP拥塞控制算法(它同时在也BSD上被实现...),而是它重构了 ...
- 三个PHP常用代码样例
作为一个正常的程序员,会好几种语言是十分正常的,相信大部分程序员也都会编写几句PHP程序,如果是WEB程序员,PHP一定是必备的.尽管PHP经常被人诟病,被人贬低,被人当玩笑开,事实证明,PHP是全世 ...
- 原创:Javascript循环队列类
需要滚动显示最多一定数量的信息,于弄了个这个 var LeesCircleQueue=function(size) { // 队列数组 var _queue=[]; // 队首索引 var _fron ...