[LeetCode 115] - 不同子序列(Distinct Subsequences)
问题
给出字符串S和T,计算S中为T的不同的子序列的个数。
一个字符串的子序列是一个由该原始字符串通过删除一些字母(也可以不删)但是不改变剩下字母的相对顺序产生的一个新字符串。如,ACE是ABCDE的一个子序列,但是AEC不是。
这里有一个例子:
S=“rabbbit”,T=“rabbit”
返回值应为3
初始思路
要找出子序列的个数,首先要有找出S中为T的子序列的方法。T是S的子序列,首先其每一个字母肯定会在S中出现,通过遍历T的每一个字母即可完成这个检查。而根据不能乱序的要求,下一个字母在S中出现的位置不能在上一个字母在S中出现的位置之前。由此,我们得到下面的算法:
循环遍历T
如果当前字母在S中,而且在S中的位置大于前一个字母在S中的位置
继续循环
否则
返回
循环结束
确认T为S的子序列
上面的算法用来找S中存不存在唯一的T子序列没有问题,但是如果T中的字母在S中出现多次就不靠谱了。当T中字母多次出现在S时,意味着出现了分支。如S:doggy,T:dog。当我们遍历到g字母时,其实出现了取S中两个不同g字母的分支。看到分支,我们可以想到递归:把循环遍历T的过程改为递归,每次递归调用要处理的T的位置加1,递归结束条件为走到T的结尾。经过这样变化,每次递归条件达成意味着一个子序列出现,这样也达到了我们计算子序列个数的目的。
查找子序列(T,要查找的字母在T中的位置,上一个字母在S中的位置)
如果 要查找的字母在T中的位置 > T的长度
子序列个数加1
返回
如果当前字母在S中
循环遍历S中所有该字母的位置
如果当前位置 <= 上一个字母在S中的位置
继续循环
查找子序列(T,要查找的字母在T中的位置 + 1, 当前位置)
在上面的伪代码中,我们发现判断当前字母是否在S中并获取它在S中的位置这个功能将会被频繁调用。在具体实现时,我们应该联想到使用关联容器(如map)这种查找速度比较快的数据结构(用以字母为下标的数组也可以,查找速度更快。但是需要考虑大小写字母,非英文字母等情况)。字母可以作为关联容器的key,而一个存放位置信息的序列容器(如vector)可以作为关联容器的值。在进行正式计算前,先遍历S生成这个存放信息的关联容器,这样以后我们就不再需要S本身了。最后得到代码如下:
class Solution {
public:
int numDistinct(std::string S, std::string T)
{
if(T.size() >= S.size())
{
if(S == T)
{
return ;
}
else
{
return ;
}
}
positionInfo_.clear();
count_ = ;
for(int i = ; i < S.size(); ++i)
{
if(positionInfo_.find(S[i]) == positionInfo_.end())
{
positionInfo_[S[i]] = {i};
}
else
{
positionInfo_[S[i]].push_back(i);
}
}
FindDistinct(T, , -);
return count_;
}
private:
void FindDistinct(std::string& T, int pos, int previousPosInS)
{
if(pos > T.size() - )
{
++count_;
return;
}
const auto iter = positionInfo_.find(T[pos]);
for(auto posIter = iter->second.begin(); posIter != iter->second.end(); ++posIter)
{
if(*posIter <= previousPosInS)
{
continue;
}
FindDistinct(T, pos + , *posIter);
}
}
std::map<char, std::vector<int>> positionInfo_;
int count_;
};
numDistinct
提交后Judge Small顺利通过,但是Judge Large超时了。
优化
针对递归计算的优化方法,通过以前题目的分析我们应该比较有经验了:无非就是通过缓存计算结果避免在递归分支中的重复计算。让我们用例子中的S和T来看看递归过程:
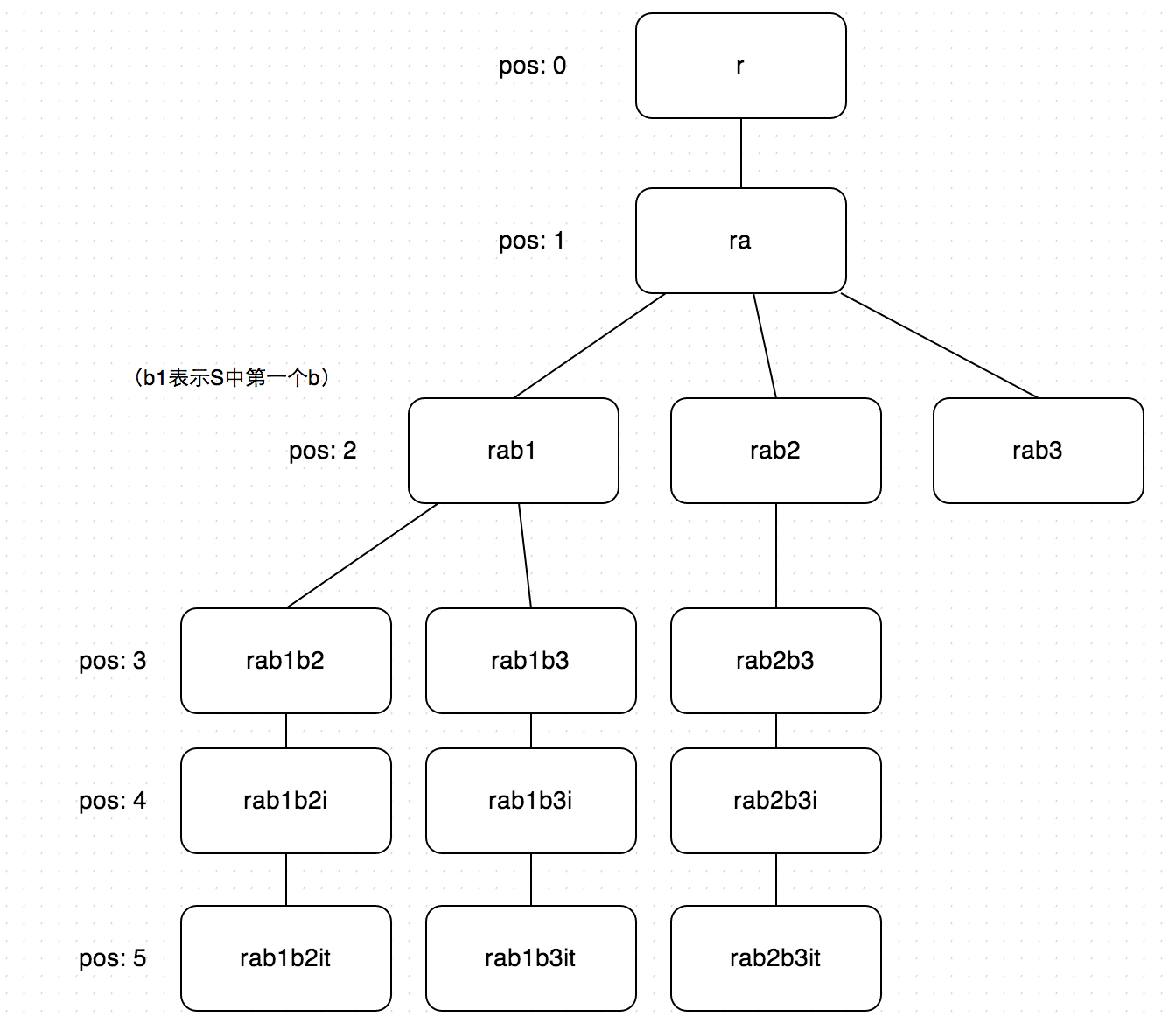
可以看到从T的pos为4的地方存在重复计算,由rab1b2已经可以知道取i后只有1种子序列了。这样看起来似乎可以用T的pos作为key,在rab1b2的递归序列中纪录count[4]=1。随后在rab1b3的递归中到达pos3层后不用继续递归pos4层即可查表得到本次的子序列数1,看起来似乎没有问题。但是当我们回到pos为2的rab1时,就可以发现隐藏的错误了,此时我们记录count[3]=2。紧接着我们开始处理pos2层的rab2的递归,经过查表得到子序列个数为count[3]=2。这显然是错误的,rab2继续递归并没有两种子序列。
分析一下错误的原因,我们发现其实某点开始的子序列的个数不但和当时T的位置有关,还和当时在S中选取的字母在S中的位置有关。因此处理完rab1递归时我们的缓存应该为count[2, 2] = 2(2为第一个b在S中的位置)。这样在处理rab2时,[2,3]是没有缓存的,我们通过递归可以得到正确的值1。而前面提到的count[4]=1的缓存变为count[4, 5]=1(5为i在S中的位置),不会影响结果。
现在可以开始实现代码了,由于需要缓存数据,我们得在原来基础上做一些小修改,不再使用成员变量纪录子序列个数,而是使用返回值。这样子才有办法缓存不同递归序列中的中间结果。至于缓存,使用一个std::map<std::pair<int, int>, int>即可。完成后的代码如下:
class SolutionV3 {
public:
int numDistinct(std::string S, std::string T)
{
if(T.size() >= S.size())
{
if(S == T)
{
return ;
}
else
{
return ;
}
}
positionInfo_.clear();
cachedResult_.clear();
for(int i = ; i < S.size(); ++i)
{
if(positionInfo_.find(S[i]) == positionInfo_.end())
{
positionInfo_[S[i]] = {i};
}
else
{
positionInfo_[S[i]].push_back(i);
}
}
return FindDistinct(T, , -);
}
private:
int FindDistinct(std::string& T, int pos, int posInS)
{
if(pos > T.size() - )
{
return ;
}
int count = ;
int result = ;
const auto iter = positionInfo_.find(T[pos]);
for(auto posIter = iter->second.begin(); posIter != iter->second.end(); ++posIter)
{
if(*posIter <= posInS)
{
continue;
}
CacheKey cacheKey(pos, *posIter);
if(cachedResult_.find(cacheKey) != cachedResult_.end())
{
count += cachedResult_[cacheKey];
continue;
}
result = FindDistinct(T, pos + , *posIter);
cachedResult_[cacheKey] = result;
count += result;
}
return count;
}
std::map<char, std::vector<int>> positionInfo_;
std::map<std::pair<int, int>, int> cachedResult_;
typedef std::pair<int, int> CacheKey;
};
numDistinct_cached
顺利通过Judge Large。
[LeetCode 115] - 不同子序列(Distinct Subsequences)的更多相关文章
- leetcode@ [72/115] Edit Distance & Distinct Subsequences (Dynamic Programming)
https://leetcode.com/problems/edit-distance/ Given two words word1 and word2, find the minimum numbe ...
- [Swift]LeetCode115. 不同的子序列 | Distinct Subsequences
Given a string S and a string T, count the number of distinct subsequences of S which equals T. A su ...
- LeetCode之“动态规划”:Distinct Subsequences
题目链接 题目要求: Given a string S and a string T, count the number of distinct subsequences of T in S. A s ...
- 不同的子序列 · Distinct Subsequences
[抄题]: 给出字符串S和字符串T,计算S的不同的子序列中T出现的个数. 子序列字符串是原始字符串通过删除一些(或零个)产生的一个新的字符串,并且对剩下的字符的相对位置没有影响.(比如,“ACE”是“ ...
- [LeetCode] 115. Distinct Subsequences 不同的子序列
Given a string S and a string T, count the number of distinct subsequences of S which equals T. A su ...
- [leetcode]115. Distinct Subsequences 计算不同子序列个数
Given a string S and a string T, count the number of distinct subsequences of S which equals T. A su ...
- [LeetCode] Distinct Subsequences 不同的子序列
Given a string S and a string T, count the number of distinct subsequences of T in S. A subsequence ...
- 子序列 sub sequence问题,例:最长公共子序列,[LeetCode] Distinct Subsequences(求子序列个数)
引言 子序列和子字符串或者连续子集的不同之处在于,子序列不需要是原序列上连续的值. 对于子序列的题目,大多数需要用到DP的思想,因此,状态转移是关键. 这里摘录两个常见子序列问题及其解法. 例题1, ...
- 【LeetCode】115. Distinct Subsequences 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 动态规划 日期 题目地址:https://leetc ...
随机推荐
- icinga 被动模式 nsca 安装
本文假设读者已安装好icinga,此外nsca本身nagios插件,icinga/nagios都适用 一.编译安装nsca1.编译,拷贝文件tar -vxzf nsca-2.7.2.tar.gz./c ...
- Project Euler problem 61
题意很明了. 然后我大概的做法就是暴搜了 先把每个几边形数中四位数的处理出来. 然后我就DFS回溯着找就行了. 比较简单吧. #include <cstdio> #include < ...
- ceph主要数据结构解析3-Ceph_fs.h文件
(1)集群内部子版本协议类型宏定义:与公共协议保持独立性,以便消息类型和协议升级受影响 #define CEPH_OSDC_PROTOCOL 24 /* server/client */OSD服务 ...
- [RxJS] Creation operator: create()
We have been using Observable.create() a lot in previous lessons, so let's take a closer look how do ...
- 01标题背包水章 HDU2955——Robberies
原来是dp[i],它代表的不被抓的概率i这最大的钱抢(可能1-100) 客是dp[i]表示抢了i钱最大的不被抓概率,嗯~,弱菜水题都刷不动. 那么状态转移方程就是 dp[i]=max(dp[i],dp ...
- 招一位安防软件project师,嵌入式开发project师
岗位职责 1.负责海思平台IPC产品应用层软件设计及维护 2.私有平台协议对接及为第三方提供技术支持. 任职资格: 1.较强的学习.领悟能力,能够高速熟悉公司现有代码. 2.熟练掌握C.C++开发语言 ...
- 【iOS】Resumable Doanloads(断点下载)
这里我们只讨论iOS平台下的通用app,我们可以自己写代码来实现resume downloads,解释如下. resume一个HTTP下载不难,但必须要理解一些关键的HTTP概念: entity ta ...
- Chapter 8. Introduction to multi-project builds 多工程构建介绍
Only the smallest of projects has a single build file and source tree, unless it happens to be a mas ...
- MyEclipse修改servlet模版
找到myeclipse安装目录中的 然后把这个jar包复制到桌面 以压缩包的方式打开 之后保存, 然后把修改的这个jar包放到刚开的路径,替换已经存在的! 完成!
- HTML CSS样式基础
一.css 1.什么是css? Cascading Style Sheet 级联样式表 改变样式的一个工具,说白了,就是为了让我们的页面好看, HTML底层封装了css这样一个工具. 2.怎么使用cs ...