[LeetCode 115] - 不同子序列(Distinct Subsequences)
问题
给出字符串S和T,计算S中为T的不同的子序列的个数。
一个字符串的子序列是一个由该原始字符串通过删除一些字母(也可以不删)但是不改变剩下字母的相对顺序产生的一个新字符串。如,ACE是ABCDE的一个子序列,但是AEC不是。
这里有一个例子:
S=“rabbbit”,T=“rabbit”
返回值应为3
初始思路
要找出子序列的个数,首先要有找出S中为T的子序列的方法。T是S的子序列,首先其每一个字母肯定会在S中出现,通过遍历T的每一个字母即可完成这个检查。而根据不能乱序的要求,下一个字母在S中出现的位置不能在上一个字母在S中出现的位置之前。由此,我们得到下面的算法:
循环遍历T
如果当前字母在S中,而且在S中的位置大于前一个字母在S中的位置
继续循环
否则
返回
循环结束
确认T为S的子序列
上面的算法用来找S中存不存在唯一的T子序列没有问题,但是如果T中的字母在S中出现多次就不靠谱了。当T中字母多次出现在S时,意味着出现了分支。如S:doggy,T:dog。当我们遍历到g字母时,其实出现了取S中两个不同g字母的分支。看到分支,我们可以想到递归:把循环遍历T的过程改为递归,每次递归调用要处理的T的位置加1,递归结束条件为走到T的结尾。经过这样变化,每次递归条件达成意味着一个子序列出现,这样也达到了我们计算子序列个数的目的。
查找子序列(T,要查找的字母在T中的位置,上一个字母在S中的位置)
如果 要查找的字母在T中的位置 > T的长度
子序列个数加1
返回
如果当前字母在S中
循环遍历S中所有该字母的位置
如果当前位置 <= 上一个字母在S中的位置
继续循环
查找子序列(T,要查找的字母在T中的位置 + 1, 当前位置)
在上面的伪代码中,我们发现判断当前字母是否在S中并获取它在S中的位置这个功能将会被频繁调用。在具体实现时,我们应该联想到使用关联容器(如map)这种查找速度比较快的数据结构(用以字母为下标的数组也可以,查找速度更快。但是需要考虑大小写字母,非英文字母等情况)。字母可以作为关联容器的key,而一个存放位置信息的序列容器(如vector)可以作为关联容器的值。在进行正式计算前,先遍历S生成这个存放信息的关联容器,这样以后我们就不再需要S本身了。最后得到代码如下:
class Solution {
public:
int numDistinct(std::string S, std::string T)
{
if(T.size() >= S.size())
{
if(S == T)
{
return ;
}
else
{
return ;
}
}
positionInfo_.clear();
count_ = ;
for(int i = ; i < S.size(); ++i)
{
if(positionInfo_.find(S[i]) == positionInfo_.end())
{
positionInfo_[S[i]] = {i};
}
else
{
positionInfo_[S[i]].push_back(i);
}
}
FindDistinct(T, , -);
return count_;
}
private:
void FindDistinct(std::string& T, int pos, int previousPosInS)
{
if(pos > T.size() - )
{
++count_;
return;
}
const auto iter = positionInfo_.find(T[pos]);
for(auto posIter = iter->second.begin(); posIter != iter->second.end(); ++posIter)
{
if(*posIter <= previousPosInS)
{
continue;
}
FindDistinct(T, pos + , *posIter);
}
}
std::map<char, std::vector<int>> positionInfo_;
int count_;
};
numDistinct
提交后Judge Small顺利通过,但是Judge Large超时了。
优化
针对递归计算的优化方法,通过以前题目的分析我们应该比较有经验了:无非就是通过缓存计算结果避免在递归分支中的重复计算。让我们用例子中的S和T来看看递归过程:
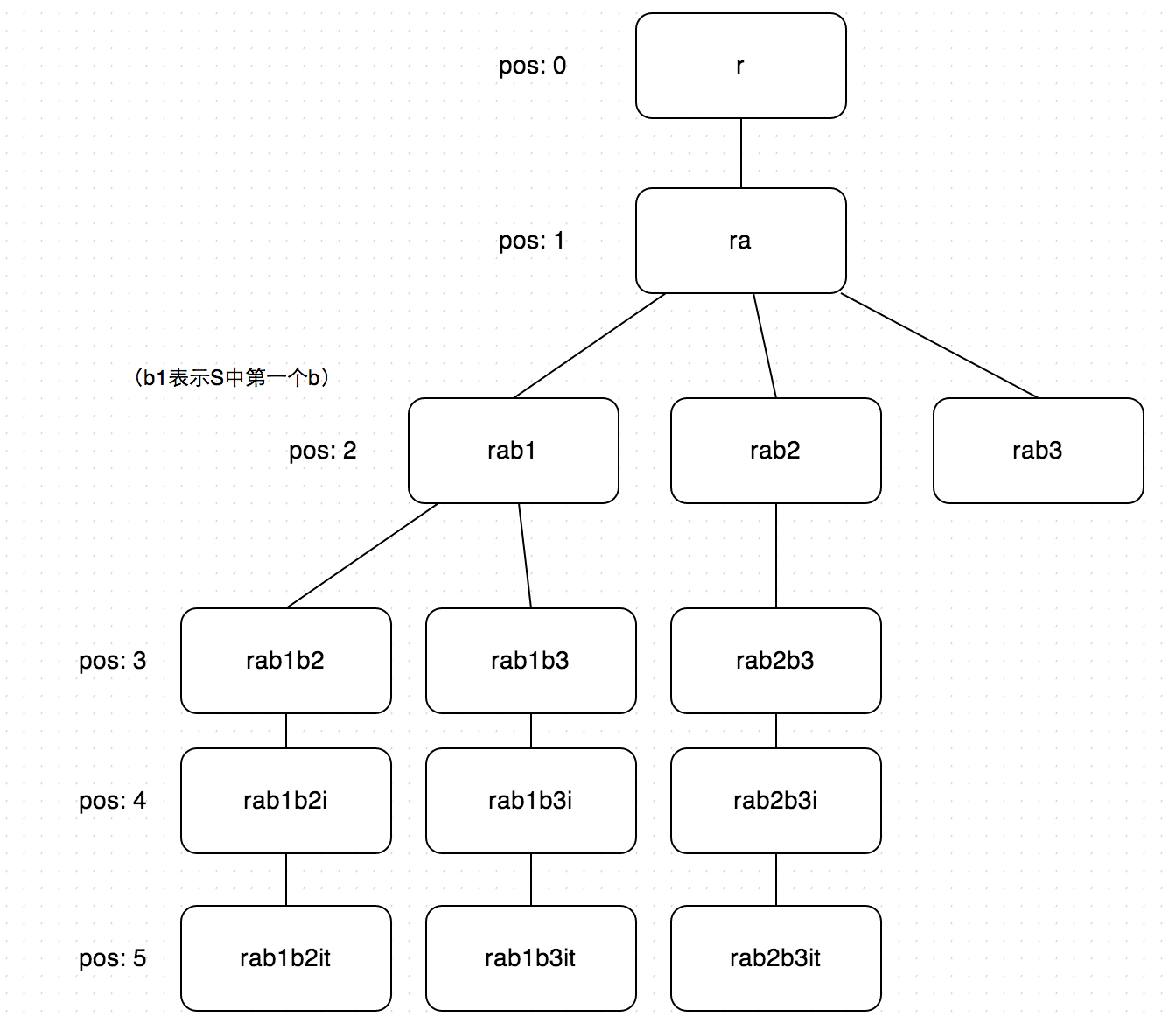
可以看到从T的pos为4的地方存在重复计算,由rab1b2已经可以知道取i后只有1种子序列了。这样看起来似乎可以用T的pos作为key,在rab1b2的递归序列中纪录count[4]=1。随后在rab1b3的递归中到达pos3层后不用继续递归pos4层即可查表得到本次的子序列数1,看起来似乎没有问题。但是当我们回到pos为2的rab1时,就可以发现隐藏的错误了,此时我们记录count[3]=2。紧接着我们开始处理pos2层的rab2的递归,经过查表得到子序列个数为count[3]=2。这显然是错误的,rab2继续递归并没有两种子序列。
分析一下错误的原因,我们发现其实某点开始的子序列的个数不但和当时T的位置有关,还和当时在S中选取的字母在S中的位置有关。因此处理完rab1递归时我们的缓存应该为count[2, 2] = 2(2为第一个b在S中的位置)。这样在处理rab2时,[2,3]是没有缓存的,我们通过递归可以得到正确的值1。而前面提到的count[4]=1的缓存变为count[4, 5]=1(5为i在S中的位置),不会影响结果。
现在可以开始实现代码了,由于需要缓存数据,我们得在原来基础上做一些小修改,不再使用成员变量纪录子序列个数,而是使用返回值。这样子才有办法缓存不同递归序列中的中间结果。至于缓存,使用一个std::map<std::pair<int, int>, int>即可。完成后的代码如下:
class SolutionV3 {
public:
int numDistinct(std::string S, std::string T)
{
if(T.size() >= S.size())
{
if(S == T)
{
return ;
}
else
{
return ;
}
}
positionInfo_.clear();
cachedResult_.clear();
for(int i = ; i < S.size(); ++i)
{
if(positionInfo_.find(S[i]) == positionInfo_.end())
{
positionInfo_[S[i]] = {i};
}
else
{
positionInfo_[S[i]].push_back(i);
}
}
return FindDistinct(T, , -);
}
private:
int FindDistinct(std::string& T, int pos, int posInS)
{
if(pos > T.size() - )
{
return ;
}
int count = ;
int result = ;
const auto iter = positionInfo_.find(T[pos]);
for(auto posIter = iter->second.begin(); posIter != iter->second.end(); ++posIter)
{
if(*posIter <= posInS)
{
continue;
}
CacheKey cacheKey(pos, *posIter);
if(cachedResult_.find(cacheKey) != cachedResult_.end())
{
count += cachedResult_[cacheKey];
continue;
}
result = FindDistinct(T, pos + , *posIter);
cachedResult_[cacheKey] = result;
count += result;
}
return count;
}
std::map<char, std::vector<int>> positionInfo_;
std::map<std::pair<int, int>, int> cachedResult_;
typedef std::pair<int, int> CacheKey;
};
numDistinct_cached
顺利通过Judge Large。
[LeetCode 115] - 不同子序列(Distinct Subsequences)的更多相关文章
- leetcode@ [72/115] Edit Distance & Distinct Subsequences (Dynamic Programming)
https://leetcode.com/problems/edit-distance/ Given two words word1 and word2, find the minimum numbe ...
- [Swift]LeetCode115. 不同的子序列 | Distinct Subsequences
Given a string S and a string T, count the number of distinct subsequences of S which equals T. A su ...
- LeetCode之“动态规划”:Distinct Subsequences
题目链接 题目要求: Given a string S and a string T, count the number of distinct subsequences of T in S. A s ...
- 不同的子序列 · Distinct Subsequences
[抄题]: 给出字符串S和字符串T,计算S的不同的子序列中T出现的个数. 子序列字符串是原始字符串通过删除一些(或零个)产生的一个新的字符串,并且对剩下的字符的相对位置没有影响.(比如,“ACE”是“ ...
- [LeetCode] 115. Distinct Subsequences 不同的子序列
Given a string S and a string T, count the number of distinct subsequences of S which equals T. A su ...
- [leetcode]115. Distinct Subsequences 计算不同子序列个数
Given a string S and a string T, count the number of distinct subsequences of S which equals T. A su ...
- [LeetCode] Distinct Subsequences 不同的子序列
Given a string S and a string T, count the number of distinct subsequences of T in S. A subsequence ...
- 子序列 sub sequence问题,例:最长公共子序列,[LeetCode] Distinct Subsequences(求子序列个数)
引言 子序列和子字符串或者连续子集的不同之处在于,子序列不需要是原序列上连续的值. 对于子序列的题目,大多数需要用到DP的思想,因此,状态转移是关键. 这里摘录两个常见子序列问题及其解法. 例题1, ...
- 【LeetCode】115. Distinct Subsequences 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 动态规划 日期 题目地址:https://leetc ...
随机推荐
- Jenkins错误“editable email notification aborted due to exception”的问题解决
如果出现:“editable email notification aborted due to exception”这样的错误,尝试升级一下jenkins,估计是这个导致的. 解决思路: http: ...
- XML自己定义检查器语法+约束(1)
每次使用它检查xml文件时,仅仅需改动xmldoc.load("xml文件名称");中的文件名称,然后将该文件放在浏览器中执行就可以. 依据浏览器弹出的对话框进行推断自己写的xml ...
- [Angular 2] A Simple Form in Angular 2
When you create a Form in Angular 2, you can easily get all the values from the Form using ControlGr ...
- PHP5.4的变化关注---What has changed in PHP 5.4.x(转)
What has changed in PHP 5.4.x Most improvements in PHP 5.4.x have no impact on existing code. There ...
- 1629 - Cake slicing(DP)
花了近2个小时终于AC,好爽.. 一道类似于最优矩阵链乘的题目,受<切木棍>那道题的启示,该题的原理也是一样的,仅仅只是变成了且面积.那么对应的也要添加维度 . 显然要完整的表示状态,最少 ...
- (转) [教程] Unity3D中角色的动画脚本的编写(一)
ps: 这两天研究unity3d,对动画处理特别迷糊,不知FBX导入以后,接下来应该怎么操作,看到这篇文章,感觉非常好,讲解的很详细. 已有好些天没写什么了,今天想起来该写点东西了.这次我所介绍的内容 ...
- Shell基本的命令
ubuntu 中文乱码 如果使用的是 PuTTY,可以通过修改 font, character set 设置来解决. Window -> Appearance -> Font settin ...
- C#学习(三)
通过类创建对象的过程称为类的实例化 匿名类型提供了一种方便的方法,可用来将一组只读属性封装到单个对象中,而无需首先显式定义一个类型. 要将匿名类型或包含匿名类型的集合作为参数传递给某一方法,可将参数作 ...
- iOS之使用QLPreviewController打开文件,处理txt文件出现乱码的情况
iOS之使用QLPreviewController打开文件,处理txt文件出现乱码的情况 主要代码: - (id <QLPreviewItem>)previewController:(QL ...
- HP SimpleXML
PHP SimpleXML PHP SimpleXML 处理最普通的 XML 任务,其余的任务则交由其它扩展处理. 什么是 PHP SimpleXML? SimpleXML 是 PHP 5 中的新特性 ...