HDFS写入数据
HDFS副本摆放策略
不同的版本副本摆放策略可能并不一致,HDFS主要采用一种机架感知(rack-ware)的机制来实现摆放策略。
由于不同的机架上节点间通信要通过交换机(switches),同一机架上的通信带宽要优于不同机架。
HDFS默认采用3副本策略(参考2.9.1 & 3.2.1):
1.若操作的机器(writer)为一个DataNode,则将一个副本放在该机器上,否则任选一个DataNode;
2.将第二个副本放在与第一个不同的机架上;
3.第三个副本放置在与第二个同一机架但不同的节点上。
机架故障的可能性远小于节点故障的可能性。
如果复制因子大于3,则在确定每个机架的副本数量低于上限(基本上是(副本-1)/机架+ 2)的同时,随机确定第4个及以下副本的位置。
由于NameNode并不允许同一DataNode存放多于一个副本,因此副本数不能超过DataNode数。
HDFS写数据流程
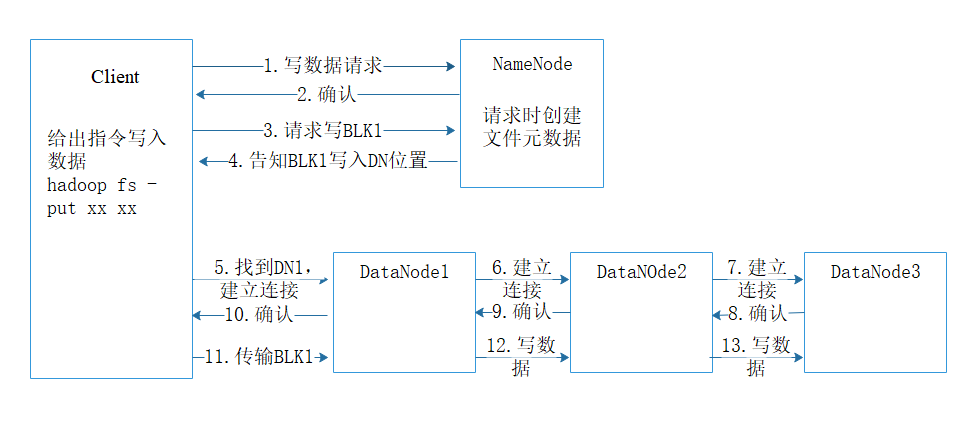
1. client发起文件上传请求,通过RPC与NameNode建立通信连接;
2. NameNode检查目标文件是否已存在等,是否可以上传;
2. client向NameNode请求写入第一个block位置;
4. NameNode根据配置文件中指定的备份数量及机架感知原理进行文件分配,返回可用的DataNode的地址告知client如:DN1,DN2,DN3;
5. client请求3台DataNode中的一台DN1上传数据(本质上是一个RPC调用,建立pipeline),DN1收到请求会继续调用DN2,然后DN2调用DN3,将整个pipeline建立完成,后逐级返回client;
6. client开始往DN1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位(默认64K),DN1收到一个packet就会传给DN2,DN2传给DN3;N1每传一个packet会放入一个应答队列等待应答。
7. 数据被分割成一个个packet数据包在pipeline上依次传输,在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点DN1将pipelineack发送给client;
8. 当一个block传输完成之后,client再次请求NameNode上传第二个block到服务器。
HDFS元数据(metadata)
元数据即数据的数据,是维护HDFS中的文件和目录所需要的信息。用于描述和组织具体的文件内容。元数据的可用性直接决定了HDFS的可用性。
形式上分为内存元数据和元数据文件两类,其中NameNode在内存中维护整个文件系统的元数据镜像,用于HDFS的管理;元数据文件则用于持久化存储。
元数据上保存信息分为以下三类:
- 文件与目录自身的属性信息,如文件名、目录名、文件大小、创建时间等;
- 文件内容存储的相关信息,如分块情况、副本个数、副本存放位置等;
- HDFS所有DataNodes的信息,用于DataNodes管理。
从来源上讲,元数据主要来源于NameNode磁盘上的元数据文件(它包括元数据镜像fsimage和元数据操作日志edits两个文件)以及各个DataNode的上报信息
参考来源:
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
https://www.cnblogs.com/mediocreWorld/p/10946647.html
http://blog.sina.com.cn/s/blog_a94476040101cco2.html
HDFS写入数据的更多相关文章
- sqoop往远程hdfs写入数据时出现Permission denied 的问题
猜测出现该问题的原因是sqoop工具用的是执行sqoop工具所用的本地用户名. 如果远程hdfs用的用户是hdfs,那么我本地还需要建一个名为hdfs的用户? 其实不需要,只要为用户增加一个环境变量就 ...
- Hadoop源码分析之客户端向HDFS写数据
转自:http://www.tuicool.com/articles/neUrmu 在上一篇博文中分析了客户端从HDFS读取数据的过程,下面来看看客户端是怎么样向HDFS写数据的,下面的代码将本地文件 ...
- spark读取hdfs上的文件和写入数据到hdfs上面
def main(args: Array[String]): Unit = { val conf = new SparkConf() conf.set("spark.master" ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- Hadoop源代码分析:HDFS读取和写入数据流控制(DataTransferThrottler类别)
DataTransferThrottler类别Datanode读取和写入数据时控制传输数据速率.这个类是线程安全的,它可以由多个线程共享. 用途是构建DataTransferThrottler对象,并 ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- HDFS写入和读取流程
HDFS写入和读取流程 一.HDFS HDFS全称是Hadoop Distributed System.HDFS是为以流的方式存取大文件而设计的.适用于几百MB,GB以及TB,并写一次读多次的场合.而 ...
- 使用Hadoop的MapReduce与HDFS处理数据
hadoop是一个分布式的基础架构,利用分布式实现高效的计算与储存,最核心的设计在于HDFS与MapReduce,HDFS提供了大量数据的存储,mapReduce提供了大量数据计算的实现,通过Java ...
随机推荐
- codewars--js--Simple string expansion+ repeat(),includes()方法
问题描述: Consider the following expansion: solve("3(ab)") = "ababab" -- "ab&qu ...
- 微信小程序组件构建UI界面小练手 —— 表单登录注册微信小程序
通过微信小程序中丰富的表单组件来完成登录界面.手机快速注册界面.企业用户注册界面的微信小程序设计. 将会用到view视图容器组件.button按钮组件.image图片组件.input输入框组件.che ...
- SDMask(iOS蒙层遮罩弹出引导)
SDMask介绍 地址 针对iOS项目,大部分弹出视图三方都把弹出内容作为了项目的一部分,这种耦合局限性较大.该项目对此解耦,围绕我何时需要使用蒙层而展开设计.将弹出内容和动画和事件完全分离出去让co ...
- 表关联使用INNER JOIN实现更新功能
准备一些数据,创建2张表,表1为学生表: CREATE TABLE [dbo].[Student] ( [SNO] INT NOT NULL PRIMARY KEY, ) NOT NULL, ,) N ...
- [Contract] Solidity 变量类型的默认值
变量的默认值一般都代表 “零值”. 比如 bool 就是 false,uint.int 就是 0,string 就是空字符串. 其它组合的参考 Solidity 判断 mapping 值的存在 Ref ...
- python格式化输出保留2位小数
我是小白就不用多说了,学习python做了个练习题,结果运行了一遍,发现输入金额后得到的有很多位小数, 虽然不知道为什么,但是看得很不舒服, 就想到应该把让小数点后只保留2位数 找到了方法:将{0}改 ...
- 刷题79. Word Search
一.题目说明 题目79. Word Search,给定一个由字符组成的矩阵,从矩阵中查找一个字符串是否存在.可以连续横.纵找.不能重复使用,难度是Medium. 二.我的解答 惭愧,我写了很久总是有问 ...
- zabbix默认监控负载取值不准确
今天碰到个负载高引起的问题但是查看zabbix监控并没有报警,检查后发现监控取值与实际服务器内负载不一致. 使用zabbix_get命令在服务器内测试 zabbix默认模板键值 取值内容 [root@ ...
- AOV拓扑排序实验总结-1
AOV拓扑排序实验总结-1 实验数据:1.实验输入数据在input.txt文件中2.对于n是指有顶点n个,数据的结束标志是一行0 0. 实验目的:获取优秀的AOV排序算法模板 数据结构安排 ...
- KindEditor配置和使用
1下载kindeditor包,目前最新版本是kindeditor-3.5.5.下载地址:http://www.kindsoft.net/ 2.解压之后,解压目录kindeditor如下图所示. 3.开 ...