(转)KL散度的理解
KL散度(KL divergence)
全称:Kullback-Leibler Divergence。
用途:比较两个概率分布的接近程度。
在统计应用中,我们经常需要用一个简单的,近似的概率分布 f * 来描述。
观察数据 D 或者另一个复杂的概率分布 f 。这个时候,我们需要一个量来衡量我们选择的近似分布 f * 相比原分布 f 究竟损失了多少信息量,这就是KL散度起作用的地方。
熵(entropy)
想要考察信息量的损失,就要先确定一个描述信息量的量纲。
在信息论这门学科中,一个很重要的目标就是量化描述数据中含有多少信息。
为此,提出了熵的概念,记作 H 。
一个概率分布所对应的熵表达如下: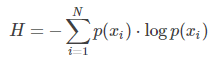
如果我们使用 log 2 作为底,熵可以被理解为:我们编码所有信息所需要的最小位数(minimum numbers of bits)。
需要注意的是:通过计算熵,我们可以知道信息编码需要的最小位数,却不能确定最佳的数据压缩策略。怎样选择最优数据压缩策略,使得数据存储位数与熵计算的位数相同,达到最优压缩,是另一个庞大的课题。
KL散度的计算
现在,我们能够量化数据中的信息量了,就可以来衡量近似分布带来的信息损失了。
KL散度的计算公式其实是熵计算公式的简单变形,在原有概率分布 p 上,加入我们的近似概率分布 q ,计算他们的每个取值对应对数的差:
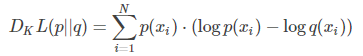
换句话说,KL散度计算的就是数据的原分布与近似分布的概率的对数差的期望值。
在对数以2为底时, log 2 ,可以理解为“我们损失了多少位的信息”。
写成期望形式:
更常见的是以下形式: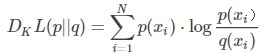
现在,我们就可以使用KL散度衡量我们选择的近似分布与数据原分布有多大差异了。
散度不是距离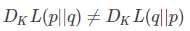
因为KL散度不具有交换性,所以不能理解为“距离”的概念,衡量的并不是两个分布在空间中的远近,更准确的理解还是衡量一个分布相比另一个分布的信息损失(infomation lost)。
使用KL散度进行优化
通过不断改变预估分布的参数,我们可以得到不同的KL散度的值。
在某个变化范围内,KL散度取到最小值的时候,对应的参数是我们想要的最优参数。
这就是使用KL散度优化的过程。
神经网络进行的工作很大程度上就是“函数的近似”(function approximators)。
因此我们可以使用神经网络学习很多复杂函数,学习过程的关键就是设定一个目标函数来衡量学习效果。
也就是通过最小化目标函数的损失来训练网络(minimizing the loss of the objective function)。
而KL散度可以作为正则化项(regularization term)加入损失函数之中,即使用KL散度来最小化我们近似分布时的信息损失,让我们的网络可以学习很多复杂的分布。
一个典型应用是VAE(变分自动编码)。
(转)KL散度的理解的更多相关文章
- KL散度的理解(GAN网络的优化)
原文地址Count Bayesie 这篇文章是博客Count Bayesie上的文章Kullback-Leibler Divergence Explained 的学习笔记,原文对 KL散度 的概念诠释 ...
- KL散度相关理解以及视频推荐
以下内容基于对[中字]信息熵,交叉熵,KL散度介绍||机器学习的信息论基础这个视频的理解,请务必先看几遍这个视频. 假设一个事件可能有多种结果,每一种结果都有其发生的概率,概率总和为1,也即一个数据分 ...
- 【原】浅谈KL散度(相对熵)在用户画像中的应用
最近做用户画像,用到了KL散度,发现效果还是不错的,现跟大家分享一下,为了文章的易读性,不具体讲公式的计算,主要讲应用,不过公式也不复杂,具体可以看链接. 首先先介绍一下KL散度是啥.KL散度全称Ku ...
- PRML读书会第十章 Approximate Inference(近似推断,变分推断,KL散度,平均场, Mean Field )
主讲人 戴玮 (新浪微博: @戴玮_CASIA) Wilbur_中博(1954123) 20:02:04 我们在前面看到,概率推断的核心任务就是计算某分布下的某个函数的期望.或者计算边缘概率分布.条件 ...
- 浅谈KL散度
一.第一种理解 相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,简称KLD),信息散度(information divergence) ...
- 非负矩阵分解(1):准则函数及KL散度
作者:桂. 时间:2017-04-06 12:29:26 链接:http://www.cnblogs.com/xingshansi/p/6672908.html 声明:欢迎被转载,不过记得注明出处哦 ...
- KL散度、JS散度、Wasserstein距离
1. KL散度 KL散度又称为相对熵,信息散度,信息增益.KL散度是是两个概率分布 $P$ 和 $Q$ 之间差别的非对称性的度量. KL散度是用来 度量使用基于 $Q$ 的编码来编码来自 $P$ 的 ...
- 相对熵(KL散度)
https://blog.csdn.net/weixinhum/article/details/85064685 上一篇文章我们简单介绍了信息熵的概念,知道了信息熵可以表达数据的信息量大小,是信息处理 ...
- ELBO 与 KL散度
浅谈KL散度 一.第一种理解 相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,简称KLD),信息散度(information dive ...
随机推荐
- POJ-1741 树上分治--点分治(算法太奇妙了)
给你1e5个节点的树,(⊙﹏⊙) 你能求出又几对节点的距离小于k吗??(分治NB!) 这只是一个板子题,树上分治没有简单题呀!(一个大佬说的) #include<cstdio> #incl ...
- Java 从入门到进阶之路(二十)
在之前的文章我们介绍了一下 Java 中的包装类,本章我们来看一下 Java 中的日期操作. 在我们日常编程中,日期使我们非常常用的一个操作,比如读写日期,输出日志等,那接下来我们就看一下 Java ...
- Wireshark抓包,带你快速入门
前言 关于抓包我们平时使用的最多的可能就是Chrome浏览器自带的Network面板了(浏览器上F12就会弹出来).另外还有一大部分人使用Fiddler,Fiddler也是一款非常优秀的抓包工具.但是 ...
- React实现座位排布组件
React实现座位排布组件 最近在开发一个影院系统的后台管理系统,该后台可以设置一个影厅的布局. 后台使用的是react框架,一位大神学长在几天之内就把这个控件研究出来了,并进行了较为严密的封装,佩服 ...
- Math&Random&ThreadLocalRandom类
Math类 //绝对值值运算: Math.abs(18.999); //返回19.999这个数的绝对值 Math.abs(-12.58); // 返回-12.58这个数的绝对值,为12.58 //取值 ...
- TypeScript 源码详细解读(1)总览
TypeScript 由微软在 2012 年 10 月首发,经过几年的发展,已经成为国内外很多前端团队的首选编程语言.前端三大框架中的 Angular 和 Vue 3 也都改用了 TypeScript ...
- Some collections were archived because you’ve reached the shared requests limits.错误解决
今天打开我的postman 发现我的一个collection不见了,左下角出现一个提示, Some collections were archived because you’ve reached t ...
- 【设计模式】 (2)关于UML
UML -- Unified Modeling Lanaguage(统计建模语言),是一种软件系统分析和设计的语言工具,他用于帮助软件开发人员进行思考和记录思路的结果. UML本身是一套符号的规定,就 ...
- 奇葩的Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured.
启动springboot的时候莫名其妙出现这个错误,我properties里面也没配置数据源啥的,但就是出现这个错误 解决方法: 在启动类上加@SpringBootApplication(exclud ...
- 自学 JAVA 的几点建议
微信公众号:一个优秀的废人 如有问题或建议,请后台留言,我会尽力解决你的问题. 前言 许久不见,最近公众号多了很多在校的师弟师妹们.有很多同学都加了我微信问了一些诸如 [如何自学 Java ]的问题, ...