机器学习笔记P1(李宏毅2019)
该博客将介绍机器学习课程by李宏毅的前两个章节:概述和回归。
视屏链接1-Introduction
视屏链接2-Regression
该课程将要介绍的内容如下所示:
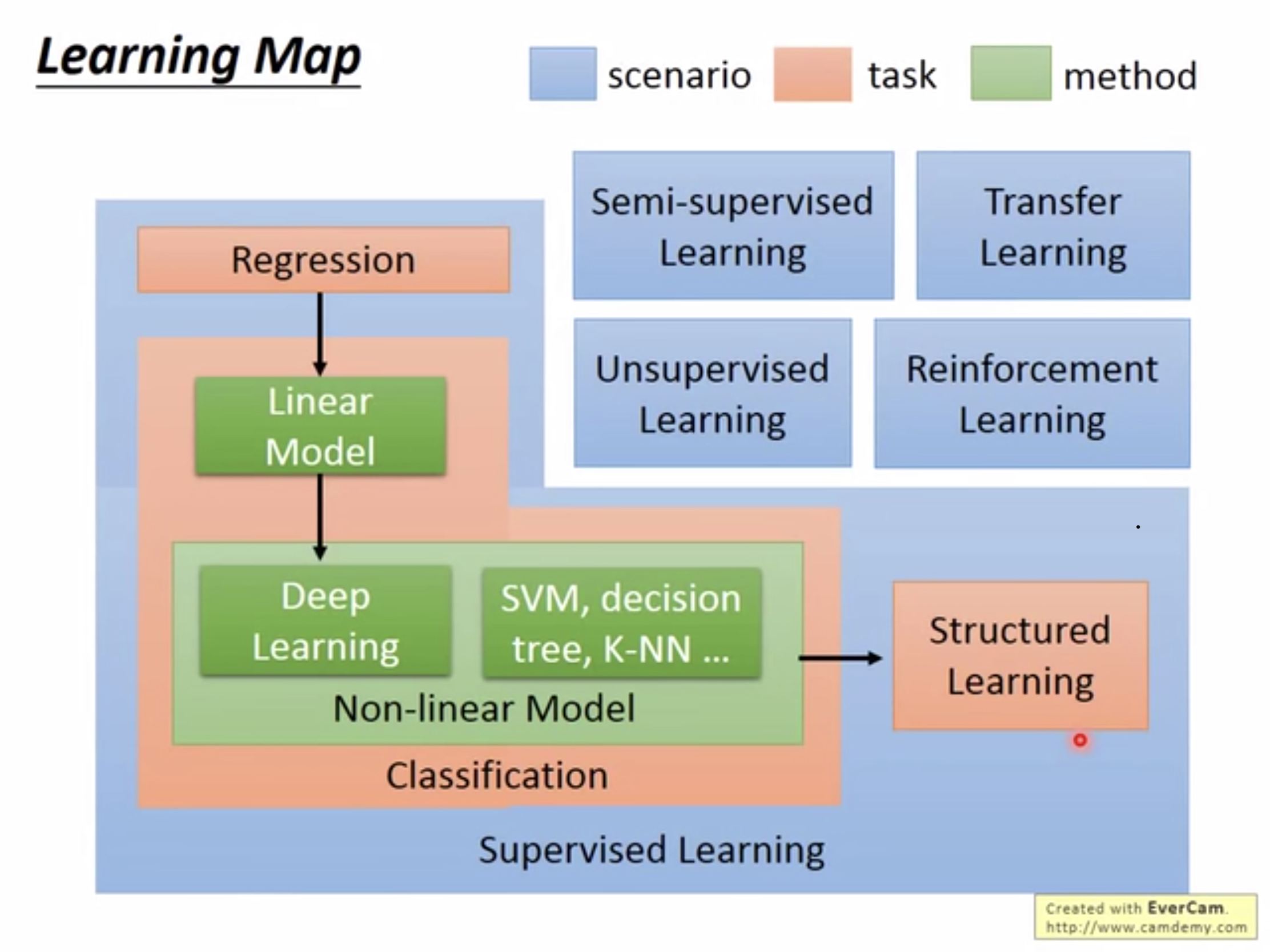
从最左上角开始看:
Regression(回归):输出的目标是一个数值。如预测明天的PM2.5数值。
接下来是Classification(分类):该任务的目标是将数据归为某一类,如进行猫狗分类。
在分类任务中,将涉及线性和非线性的模型。其中,非线性的模型包含了Deep-Learning,SVM,决策树,K-NN等等。
结构化学习相对于回归或者分类来说,输出的是一个向量,结构化学习的输出可以是图像、语句、树结构等等。目前最火的的GAN就是一个典型的结构化学习样例。
回归、分类和结构化学习可以归为有监督任务,除此之外还有半监督任务以及无监督任务。
有监督模型对于模型的输入全部都是有标签的数据,半监督模型对于模型的输入,部分是有标签的数据,部分是没有标签的数据。无监督模型对于模型的输入全部都是没有标签的数据。
除此之外,因为手动对数据进行标注的代价很大,因此可以考虑将其他领域以及训练好的模型迁移到自己的任务中来,这叫做迁移学习。
目下,还有另外一个当下很火的技术叫做Reinforcement Learning(增强学习)。增强学习和监督学习的主要区别是:在有监督学习中,我们会对数据给出标签,然后拿模型得到的结果与结果进行对比,将结果进行一些处理之后用来优化模型。而在增强学习中,我们不会给模型正确的答案,取而代之的是我们会给模型一个分数,以此来表示模型结果的好坏程度。在增强学习中,模型并不知道为什么不好,只知道最终的结果评分。
(Regression)回归
对于一个回归问题,我们假设已经有的数据为\(x\),其对应的真实标签为\(\hat y\)。我们需要寻找一组函数\(f(.)\)以使得\(f(x)\)尽可能相等或者接近真实值\(\hat y\)。我们将函数值定义为\(y\),则有\(y=f(x)=b+wx\)。其中,\(b,w,x\)均为向量,代表着数据的某个特征。同时,我们将\(w\)称为权重,\(b\)称为偏差。我们的目标就是找到这样的一组\(f(.)\)使得,任意给出一个数据\(x\),都有\(y=\hat y\)。我们将这样的一组函数\(f(.)\)称之为模型(Model)。因为\(b\)和\(w\)可以取得任意值,我们很难人工去设定这样的一组参数,所以我们可以先让它们取得一组随机值,然后通过损失函数(\(loss\))来将参数进行调整优化。我们可以简单的将损失函数定义为:
\[
L(w, b) = \sum_{i=1}^{i=n}{(\hat y^i-(b+w*x^i))^2}
\]
公式中的\(n\)表示样本个数,同时我们使用了平方差来作为损失函数,当然也可以选取其它的形式。这样,我们可以通过最小化损失函数值来优化模型参数。
为了最小化损失函数,我们可以使用梯度下降法。通过梯度下降法,我们每次更新参数之前都首先计算一下模型中的各个参数对\(loss\)的影响程度,选择能够使得\(loss\)下降最快的方向来更新参数。这样,我们就能够快速地优化模型。
在这个过程中,我们会计算参数\(w\)和\(b\)对于\(loss\)的微分,这可以简单地视作有一个有一条曲线是\(loss\)和\(w\)的关系曲线,\(loss\)随着\(w\)的变化而变化,计算微分就算为了计算沿着曲线的切线。 当切线的斜率为负数时,显然将\(w\)沿着该方向改变会使得\(loss\)变小。
在此,我们将参数更新的公式设置为:
\[
w^{k+1} =w^k - \eta \frac{dL}{dw}|_{w=w^k}
\]
其中\(\eta\)为学习率,是一个超参数。对于偏差\(b\)的优化也是进行同样的处理。
经过一定轮数的参数更新之后,\(\frac{dL}{dw}\)将会趋近于0,这时候,我们认为模型性能已经达到了最佳。但是需要注意的是,这种方法很容易就会使得模型陷入局部最小而无法达到全局最小的情形。当然,对于凸优化是完全不存在这个问题的,因为它的局部极小点就是全局最小点。
详细参数对于损失的计算公式为:
已知:
\[
L(w, b) = \sum_{k=1}^{n}(\hat y^k - (b + w*x^k))^2
\]
则:
\[
\frac{dL}{dw} = 2\sum_{k=1}^{n}(\hat y^k - (b + w*x^k))(-x^k)
\]
\[
\frac{dL}{db} = -2\sum_{k=1}{n}{(\hat y^k - (b+w*x^k))}
\]
为了使我们的模型能够很好的拟合训练集数据,我们总是会有很多的方法,最简单的就是直接增大模型的复杂度,比如,将线性的规则更新为二次、三次的函数等等,即我们能够很容易地使得模型能够很好的拟合训练集数据,只要我们的模型够复杂。然而,我们更想要看到的情况是,我们模型在测试集或者说在模型没有见到过的数据集合上会表现出良好的性能。过为复杂的模型有更大的可能性出现对于训练集过拟合的情况,当两个模型都能很好地拟合训练集时,我们总是偏向于选择复杂度低的模型。
模型的过拟合是很难避免的,我们也能够使用很多方法来降低过拟合,提高模型的泛化能力。如:
正则化(Regularization)
正则化就是更改\(loss\)函数,以约束模型的复杂度,公式如下:
\[
L = \sum_{k=1}^n (\hat y^k- (b + \sum w_kx_k))^2 + \lambda \sum(w_k)^2
\]
后面的项即为用于约束模型复杂度的项。可以看到,我们期望\(w_k\)越小越好。当参数值较小且接近于0的时候,对应的曲线是比较平滑的,这时候,当输入的数据出现变化时,输出对于这些变化是比较不敏感的。这个\(\lambda\)值越大,表明我们越希望参数值更小。显然,这也是一个需要我们进行尝试的超参数。
机器学习笔记P1(李宏毅2019)的更多相关文章
- 李宏毅机器学习笔记6:Why deep、Semi-supervised
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记5:CNN卷积神经网络
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记4:Brief Introduction of Deep Learning、Backpropagation(后向传播算法)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记3:Classification、Logistic Regression
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记2:Gradient Descent(附带详细的原理推导过程)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习笔记1:Regression、Error
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- 机器学习笔记:Gradient Descent
机器学习笔记:Gradient Descent http://www.cnblogs.com/uchihaitachi/archive/2012/08/16/2642720.html
随机推荐
- VXLAN IBGP RR 实验
网络拓扑图: SPINE1配置 ====================================================== hostname SPINE-1nv overlay ev ...
- 魅族--魅蓝metal
评论:金属潮流平民化
- 利用docker容器运行.net core webapi
利用docker容器运行.net core webapi :first-child { margin-top: 0 !important; } > :last-child { margin-bo ...
- flask的url处理器(url_defaults和url_value_preprocessor)
url处理器的作用:对于一部分资源, 你并不是很清楚该如何设定其 URL 相同的部分.例如可能有一些URL包含了几个字母来指定的多国语言语种,但是你不想在每个函数里都手动识别到底是哪个语言 rom f ...
- 【题解】JXOI2018游戏(组合数)
[题解]JXOI2018游戏(组合数) 题目大意 对于\([l,r]\)中的数,你有一种操作,就是删除一个数及其所有倍数.问你删除所有数的所有方案的步数之和. 由于这里是简化题意,有一个东西没有提到: ...
- 用本地自定义域名访问远程服务器,并支持websocket和cookie
场景 在公司会有很多测试的机器,或者一些OA服务,Confluence,Jenkins,各种中间件的后台等等,都使用HTTP访问,且由于是内网机器没有域名,输入IP又要输入不同端口,访问起来比较麻烦. ...
- Matlab学习过程中的一些小问题
1.Overload your functions by having variable number of input and output argumernt.Not only can we ov ...
- schedule of 2016-09-19~2016-09-25(Monday~Sunday)——1st semester of 2nd Grade
2016/9/19 Monday 1.make ppt for today's group meeting 2.recite 100 words 3.review <图解机器学习>ch1~ ...
- 利用 Hexo 或者 hugo 搭建个人博客
我们无法选择生活的样子,但我们可以记下来. 博客的开始 其实,一切都是为了更好的装逼.好吧,我着相了. 最开始想做一个自己博客,主要是因为看到了很多人都有,觉得自己没有太 Low 了.于是申请了 CS ...
- pqsql 防注入
在数据库查询时经常会遇到根据传入的参数查询内容的情况,传入的参数有可能会带有恶意代码,比如or 1=1,这样where判断为true,就会返还所有的记录.为了解决这个问题,可以在参数外面包一层单引号, ...