从头学pytorch(二十二):全连接网络dense net
DenseNet
论文传送门,这篇论文是CVPR 2017的最佳论文.
resnet一文里说了,resnet是具有里程碑意义的.densenet就是受resnet的启发提出的模型.
resnet中是把不同层的feature map相应元素的值直接相加.而densenet是将channel维上的feature map直接concat在一起,从而实现了feature的复用.如下所示:
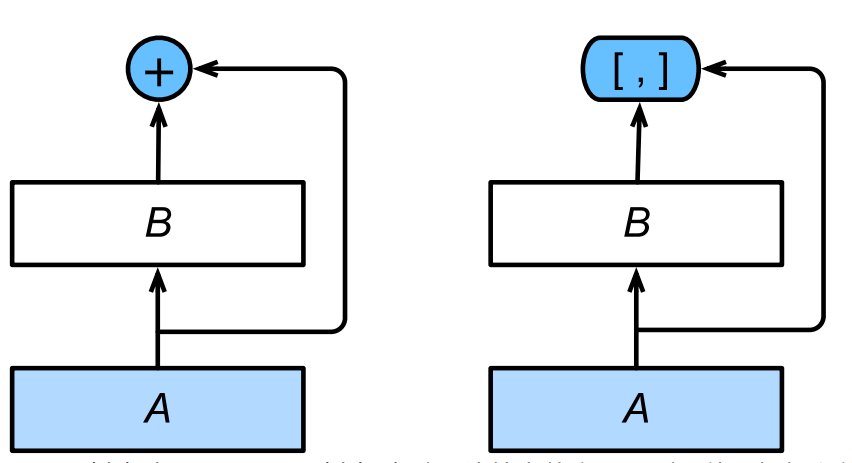

注意,是连接dense block内输出层前面所有层的输出,不是只有输出层的前一层
网络结构


首先实现DenseBlock
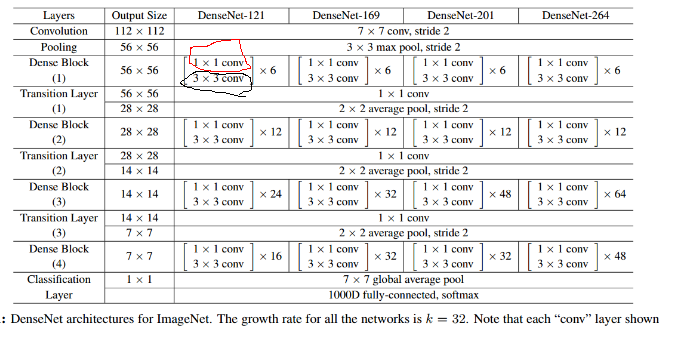
先解释几个名词
bottleneck layer
即上图中红圈的1x1卷积核.主要目的是对输入在channel维度做降维.减少运算量.

卷积核的数量为4k,k为该layer输出的feature map的数量(也就是3x3卷积核的数量)growth rate
即上图中黑圈处3x3卷积核的数量.假设3x3卷积核的数量为k,则每个这种3x3卷积后,都得到一个channel=k的输出.假如一个denseblock有m组这种结构,输入的channel为n的话,则做完一次连接操作后得到的输出的channel为n + k + k +...+k = n+m*k.所以又叫做growth rate.conv
论文里的conv指的是BN-ReLU-Conv
实现DenseBlock
DenseLayer
class DenseLayer(nn.Module):
def __init__(self,in_channels,bottleneck_size,growth_rate):
super(DenseLayer,self).__init__()
count_of_1x1 = bottleneck_size
self.bn1 = nn.BatchNorm2d(in_channels)
self.relu1 = nn.ReLU(inplace=True)
self.conv1x1 = nn.Conv2d(in_channels,count_of_1x1,kernel_size=1)
self.bn2 = nn.BatchNorm2d(count_of_1x1)
self.relu2 = nn.ReLU(inplace=True)
self.conv3x3 = nn.Conv2d(count_of_1x1,growth_rate,kernel_size=3,padding=1)
def forward(self,*prev_features):
# for f in prev_features:
# print(f.shape)
input = torch.cat(prev_features,dim=1)
# print(input.device,input.shape)
# for param in self.bn1.parameters():
# print(param.device)
# print(list())
bottleneck_output = self.conv1x1(self.relu1(self.bn1(input)))
out = self.conv3x3(self.relu2(self.bn2(bottleneck_output)))
return out
首先是1x1卷积,然后是3x3卷积.3x3卷积核的数量即growth_rate,bottleneck_size即1x1卷积核数量.论文里是bottleneck_size=4xgrowth_rate的关系. 注意forward函数的实现
def forward(self,*prev_features):
# for f in prev_features:
# print(f.shape)
input = torch.cat(prev_features,dim=1)
# print(input.device,input.shape)
# for param in self.bn1.parameters():
# print(param.device)
# print(list())
bottleneck_output = self.conv1x1(self.relu1(self.bn1(input)))
out = self.conv3x3(self.relu2(self.bn2(bottleneck_output)))
return out
我们传进来的是一个元祖,其含义是[block的输入,layer1输出,layer2输出,...].前面说过了,一个dense block内的每一个layer的输入是前面所有layer的输出和该block的输入在channel维度上的连接.这样就使得不同layer的feature map得到了充分的利用.
tips:
函数参数带*表示可以传入任意多的参数,这些参数被组织成元祖的形式,比如
## var-positional parameter
## 定义的时候,我们需要添加单个星号作为前缀
def func(arg1, arg2, *args):
print arg1, arg2, args
## 调用的时候,前面两个必须在前面
## 前两个参数是位置或关键字参数的形式
## 所以你可以使用这种参数的任一合法的传递方法
func("hello", "Tuple, values is:", 2, 3, 3, 4)
## Output:
## hello Tuple, values is: (2, 3, 3, 4)
## 多余的参数将自动被放入元组中提供给函数使用
## 如果你需要传递元组给函数
## 你需要在传递的过程中添加*号
## 请看下面例子中的输出差异:
func("hello", "Tuple, values is:", (2, 3, 3, 4))
## Output:
## hello Tuple, values is: ((2, 3, 3, 4),)
func("hello", "Tuple, values is:", *(2, 3, 3, 4))
## Output:
## hello Tuple, values is: (2, 3, 3, 4)
DenseBlock
class DenseBlock(nn.Module):
def __init__(self,in_channels,layer_counts,growth_rate):
super(DenseBlock,self).__init__()
self.layer_counts = layer_counts
self.layers = []
for i in range(layer_counts):
curr_input_channel = in_channels + i*growth_rate
bottleneck_size = 4*growth_rate #论文里设置的1x1卷积核是3x3卷积核的4倍.
layer = DenseLayer(curr_input_channel,bottleneck_size,growth_rate).cuda()
self.layers.append(layer)
def forward(self,init_features):
features = [init_features]
for layer in self.layers:
layer_out = layer(*features) #注意参数是*features不是features
features.append(layer_out)
return torch.cat(features, 1)
一个Dense Block由多个Layer组成.这里注意forward的实现,init_features即该block的输入,然后每个layer都会得到一个输出.第n个layer的输入由输入和前n-1个layer的输出在channel维度上连接组成.
最后,该block的输出为各个layer的输出为输入以及各个layer的输出在channel维度上连接而成.
TransitionLayer
很显然,dense block的计算方式会使得channel维度过大,所以每一个dense block之后要通过1x1卷积在channel维度降维.
class TransitionLayer(nn.Sequential):
def __init__(self, in_channels, out_channels):
super(TransitionLayer, self).__init__()
self.add_module('norm', nn.BatchNorm2d(in_channels))
self.add_module('relu', nn.ReLU(inplace=True))
self.add_module('conv', nn.Conv2d(in_channels, out_channels,kernel_size=1, stride=1, bias=False))
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2))
Dense Net
dense net的基本组件我们已经实现了.下面就可以实现dense net了.
class DenseNet(nn.Module):
def __init__(self,in_channels,num_classes,block_config):
super(DenseNet,self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels,64,kernel_size=7,stride=2,padding=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.pool1 = nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.dense_block_layers = nn.Sequential()
block_in_channels = in_channels
growth_rate = 32
for i,layers_counts in enumerate(block_config):
block = DenseBlock(in_channels=block_in_channels,layer_counts=layers_counts,growth_rate=growth_rate)
self.dense_block_layers.add_module('block%d' % (i+1),block)
block_out_channels = block_in_channels + layers_counts*growth_rate
transition = TransitionLayer(block_out_channels,block_out_channels//2)
if i != len(block_config): #最后一个dense block后没有transition layer
self.dense_block_layers.add_module('transition%d' % (i+1),transition)
block_in_channels = block_out_channels // 2 #更新下一个dense block的in_channels
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=(1,1))
self.fc = nn.Linear(block_in_channels,num_classes)
def forward(self,x):
out = self.conv1(x)
out = self.pool1(x)
for layer in self.dense_block_layers:
out = layer(out)
# print(out.shape)
out = self.avg_pool(out)
out = torch.flatten(out,start_dim=1) #相当于out = out.view((x.shape[0],-1))
out = self.fc(out)
return out
首先和resnet一样,首先是7x7卷积接3x3,stride=2的最大池化,然后就是不断地dense block + tansition.得到feature map以后用全局平均池化得到n个feature.然后给全连接层做分类使用.
可以用
X=torch.randn(1,3,224,224).cuda()
block_config = [6,12,24,16]
net = DenseNet(3,10,block_config)
net = net.cuda()
out = net(X)
print(out.shape)
测试一下,输出如下,可以看出feature map的变化情况.最终得到508x7x7的feature map.全局平均池化后,得到508个特征,通过线性回归得到10个类别.
torch.Size([1, 195, 112, 112])
torch.Size([1, 97, 56, 56])
torch.Size([1, 481, 56, 56])
torch.Size([1, 240, 28, 28])
torch.Size([1, 1008, 28, 28])
torch.Size([1, 504, 14, 14])
torch.Size([1, 1016, 14, 14])
torch.Size([1, 508, 7, 7])
torch.Size([1, 10])
总结:
核心就是dense block内每一个layer都复用了之前的layer得到的feature map,因为底层细节的feature被复用,所以使得模型的特征提取能力更强. 当然坏处就是计算量大,显存消耗大.
从头学pytorch(二十二):全连接网络dense net的更多相关文章
- 智课雅思词汇---二十二、-al即是名词性后缀又是形容词后缀
智课雅思词汇---二十二.-al即是名词性后缀又是形容词后缀 一.总结 一句话总结: 后缀:-al ②[名词后缀] 1.构成抽象名词,表示行为.状况.事情 refusal 拒绝 proposal 提议 ...
- [分享] IT天空的二十二条军规
Una 发表于 2014-9-19 20:25:06 https://www.itsk.com/thread-335975-1-1.html IT天空的二十二条军规 第一条.你不是什么都会,也不是什么 ...
- Bootstrap <基础二十二>超大屏幕(Jumbotron)
Bootstrap 支持的另一个特性,超大屏幕(Jumbotron).顾名思义该组件可以增加标题的大小,并为登陆页面内容添加更多的外边距(margin).使用超大屏幕(Jumbotron)的步骤如下: ...
- Web 前端开发精华文章推荐(HTML5、CSS3、jQuery)【系列二十二】
<Web 前端开发精华文章推荐>2014年第一期(总第二十二期)和大家见面了.梦想天空博客关注 前端开发 技术,分享各类能够提升网站用户体验的优秀 jQuery 插件,展示前沿的 HTML ...
- 二十二、OGNL的一些其他操作
二十二.OGNL的一些其他操作 投影 ?判断满足条件 动作类代码: ^ $ public class Demo2Action extends ActionSupport { public ...
- WCF技术剖析之二十二: 深入剖析WCF底层异常处理框架实现原理[中篇]
原文:WCF技术剖析之二十二: 深入剖析WCF底层异常处理框架实现原理[中篇] 在[上篇]中,我们分别站在消息交换和编程的角度介绍了SOAP Fault和FaultException异常.在服务执行过 ...
- VMware vSphere 服务器虚拟化之二十二桌面虚拟化之创建View Composer链接克隆的虚拟桌面池
VMware vSphere 服务器虚拟化之二十二桌面虚拟化之创建View Composer链接克隆的虚拟桌面池 在上一节我们创建了完整克隆的自动专有桌面池,在创建过程比较缓慢,这次我们将学习创建Vi ...
- Bootstrap入门(二十二)组件16:列表组
Bootstrap入门(二十二)组件16:列表组 列表组是灵活又强大的组件,不仅能用于显示一组简单的元素,还能用于复杂的定制的内容. 1.默认样式列表组 2.加入徽章 3.链接 4.禁用的列表组 5. ...
- JAVA之旅(二十二)——Map概述,子类对象特点,共性方法,keySet,entrySet,Map小练习
JAVA之旅(二十二)--Map概述,子类对象特点,共性方法,keySet,entrySet,Map小练习 继续坚持下去吧,各位骚年们! 事实上,我们的数据结构,只剩下这个Map的知识点了,平时开发中 ...
- 备忘录模式 Memento 快照模式 标记Token模式 行为型 设计模式(二十二)
备忘录模式 Memento 沿着脚印,走过你来时的路,回到原点. 苦海翻起爱恨 在世间难逃避命运 相亲竟不可接近 或我应该相信是缘份 一首<一生所爱>触动了多少 ...
随机推荐
- 关于js如果控制标签的字符长度
js名字长度限定(如限制为50个字符,超过的显示...) var new_playerName = ""; jQuery(".translate").each( ...
- 抽象类(abstract class)和接口(interface)有什么区别?
抽象类中可以有构造器.抽象方法.具体方法.静态方法.各种成员变量,有抽象方法的类一定要被声明为抽象类,而抽象类不一定要有抽象方法,一个类只能继承一个抽象类. 接口中不能有构造器.只能有public修饰 ...
- DOCKER学习_006:Docker存储驱动
一 镜像的分层特性 在说docker的文件系统之前,我们需要先想清楚一个问题.我们知道docker的启动是依赖于image,docker在启动之前,需要先拉取image,然后启动.多个容器可以使用同一 ...
- $tarjan$简要学习笔记
$QwQ$因为$gql$的$tarjan$一直很差所以一直想着要写个学习笔记,,,咕了$inf$天之后终于还是写了嘻嘻. 首先说下几个重要数组的基本定义. $dfn$太简单了不说$QwQ$ 但是因为有 ...
- VS/Xamarin Android入门一
一.安装和配置(以Visual Studio Pro 2015为例) Visual Studio2015直接提供了这个插件的选择项,稍微提示一下,如果要安装的话,最好准备好十个小时的打算,而且是网速不 ...
- Linux学习之路--常用命令
#ls 显示文件信息 #ll 显示文件(不包括隐藏文件)具体信息 等于 #ls -l #ll -a 显示所有文件(包括隐藏文件)具体信息 #ll -htr aa 显示最近修改的文件 h是易读的 ...
- docker-bind挂载
使用绑定挂载 自Docker早期以来,绑定挂载一直存在.与卷相比,绑定装载具有有限的功能.使用绑定装入时,主机上的文件或目录将装入容器中.文件或目录由其在主机上的完整路径或相对路径引用.相反,当您使用 ...
- Mybatis-plus 实体类继承关系 插入默认值
在实际开发中,会定义一些公共字段,而这些公共字段,一般都是在进行操作的时候由程序自动将默认值插入.而公共的字段一般会被封装到一个基础的实体类中,同时实体类中会实现相应的getter setter 方法 ...
- C++string中find,find_first_of和find_last_of的用法
1. size_t find (const string& str, size_t pos = 0) str.find(str1) 说明:从pos(默认是是0,即从头开始查找)开始查找,找到第 ...
- Java字符串(String类)
定义方法: 1.String demo = "test"; 2.String demo = new String(); 3.String demo = new String(&qu ...