MySQL系列(七)--SQL优化的步骤
前面讲了如何设计数据库表结构、存储引擎、索引优化等内存,这篇文章会讲述如何进行SQL优化,也是面试中关于数据库肯定会被问到的,
这些内容不仅仅是为了面试,更重要的是付诸实践,最终用到工作当中
之前的MySQL内存地址:MySQL系列内容
如何获取存在性能的SQL:
1、通过生产环境用户、测试人员反馈的应用响应速度较慢,可能就是SQL性能较差导致的
2、通过慢查询日志获取
3、实时获取存在性能问题的SQL
MySQL慢查日志:
参数:
1、slow_query_log 是否启动慢查询日志,默认不开启,on/off,动态参数,运行时通过set global slow_query_log=on设置,也可以
通过脚本定时开关
2、slow_query_log_file 日志存储和数据存储的文件名和路径,最好是自己设置,而不是默认,日志和数据文件要区分开
3、long_query_time 慢查询日志SQL执行时间的阈值,单位s,默认10s,超过这个执行时间的SQL都会被记录下来,无论是查询还是修改,
还是记录已经回滚的SQL,最大精确到微妙ms,可以设置为1s比较合适
4、log_queries_not_using_indexes 是否记录未使用索引的SQL
设置参数:
1、my.cnf,永久生效
2、通过SET GLOBAL设置参数,例如SET GLOBAL log_queries_not_using_indexes = ON。MySQL重启之后参数就会被重置
查看当前session慢SQL的条数:
SHOW STATUS LIKE '%slow_queries%'; 只记录DDL中的慢查询SQL
慢查询日志常用分析工具:
1、MySQLdumpslow 官方推荐
汇总除查询条件外其他完全相同的SQL,并将分析结果按照参数中所指定的顺序输出
mysqldumpslow -s r -t 10 mysql-slow.log; -s order(c,t,l,r,at,al,ar) 输出结果排序方式:
c count查询总次数
t time总时间
l lock查询锁的时间
r row总数据行 加上a,就是取平均数 -t top指定取前几条作为结果输出
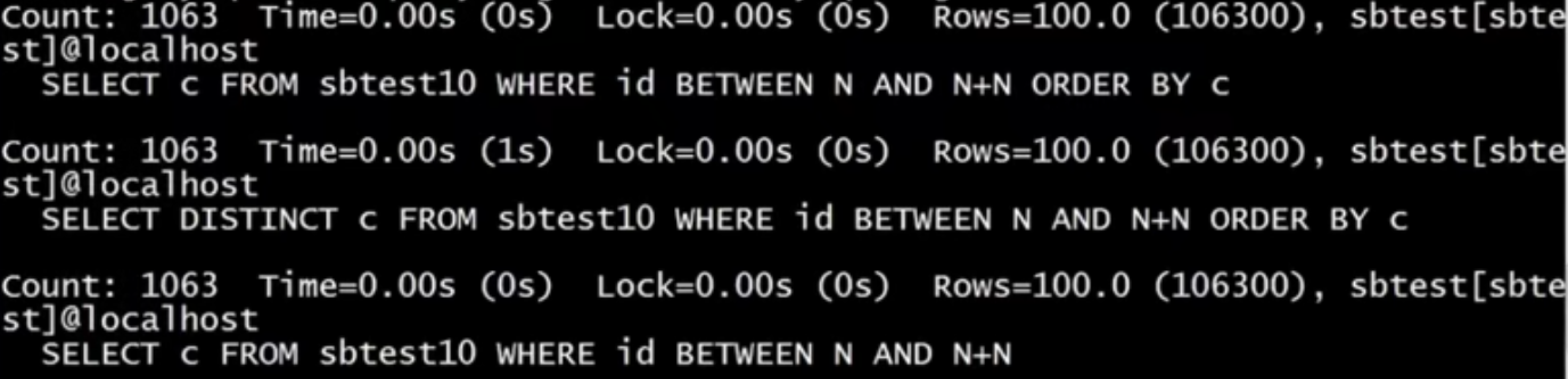
Count是指执行次数为1063,time执行时间,lock锁的时间,rows单次查询返回的行数,共106300
2、pt-query-digest:分析慢查询日志、二进制日志等
pt-query-digest --explain h=127.0.0.1,u=root,p=pasword mysql-slow.log
--explain是指是否包含SQL的执行计划
u和p是指在哪台服务器执行计划
参数也可以直接省略


建议在从服务器生成慢查询日志
相比MySQLdumpslow,pt-query-digest多了SQL执行计划,所以更推荐pt-query-digest
3、实时获取慢查询SQL:
SELECT ID,`user`,`HOST`,DB,COMMAND,TIME,STATE,INFO FROM information_schema.`PROCESSLIST` WHERE TIME >=60;
通过上面的SQL可以实时获取执行时间满足条件的SQL
4、直接查看慢查询log文件
那么SQL查询速度慢的原因?需要了解SQL处理的过程
SQL处理查询请求的过程:
1、客户端发送SQL给服务器
2、服务器检查是否在查询缓存中命中该SQL,通过一个对大小写敏感的hash查找实现,只能是全值匹配,如果命中,查询用户权限
3、服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划
4、然后存储引擎根据查询计划来查询数据
5、将结果返回给客户端
查询缓存参数:
query_cache_type 设置查询缓存是否可用,on/off/demand(设置demand通过查询语句中的SQL_CACHE和SQL_NO_CACHE控制是否使用查询缓存)
query_cache_size 设置查询缓存内存大小,为1024整数倍
query_cache_limit 设置查询缓存可用存储的最大值,超过这个值就不会被缓存
query_cache_wlock_invalidate 设置如果表被锁住是否返回缓存中的数据,默认no
query_cache_min_res_unit 设置查询缓存分配的内存块最小单位
PS:
如果数据库读写十分频繁,建议关闭查询缓存,因为对缓存查询的时候,需要对缓存加锁,query_cache_type设置为off,query_cache_size
设置为0
如果没有开启查询缓存或者缓存缓存未命中,需要把SQL解析为查询计划,然后查询计划与存储引擎进行交互,这个过程包括:解析SQL,预处
理,优化SQL执行计划
解析SQL,预处理:
1、检查语法是否使用了正确的关键字
2、关键字的顺序是否正确
3、检查表和数据列是否存在以及名称和别名是否存在歧义等
上面的检查通过之后,查询优化器就可以生成查询计划了,会对可以使用的索引进行比较,如果可以使用的索引过多,会对查询效率造成影响
造成优化器生成错误执行计划的原因:
1、统计信息不准确,例如InnoDB提供的统计信息是抽样的,可能是不正确的
2、执行计划的成本估算不等于实际执行计划的成本,因为MySQL不知道哪些页存在内存中,哪些页面数据是顺序读取
3、执行优化器认为的最优可能和开发人员认为的最优不同,我们想要只是SQL时间最短,而MySQL基于其成本模型选择最优的执行计划
4、优化器不考虑并发查询,涉及到锁的问题
5、优化器不考虑不受控制的成本,例如存储过程,自定义函数
举个栗子:
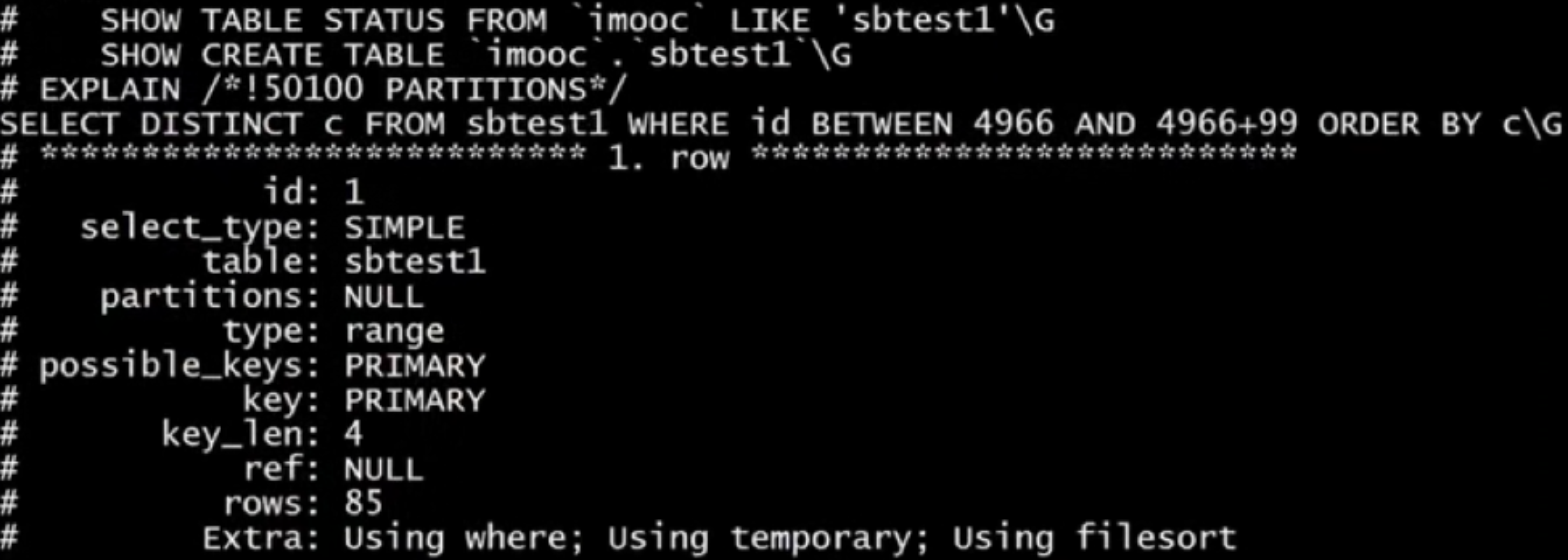
EXPLAIN SELECT count(id) FROM role ;我们想要走id的primary key,但是实际上是user_id的索引,此时可以强制使用主键索引
EXPLAIN SELECT count(id) FROM role FORCE INDEX(PRIMARY);
如果不是上面的原因,是因为SQL本身或者表结构的问题
查看SQL执行计划:
使用explain参数,关于explain的使用大家应该都知道,我们需要尽可能走索引,或者修改SQL语句
可优化的SQL类型:
1、重新定义表的关联顺序
2、将外连接转化为内连接,where条件和库表结构等都会影响
3、使用等价交换规则,例如where 1=1 and 1>0,直接被改写成where 1>0
4、对优化count() min() max(),例如如果InnoDB的B-tree索引,数据是有序的。如果使用了这个优化,在执行计划中显示:select tables
optimized away,意思:优化器从执行计划中移除这个表,以一个常数取代
5、将表达式转化为常数
6、子查询优化,转化为关联查询
7、满足某个条件,就会提前终止查询。例如肯定不满足的条件,例如Id int(11) unsigned ,使用where id = -1,就会直接返回null
8、对in()条件进行优化
如何确定处理的每个阶段所消耗的时间:
1、使用profile:
1).set profiling=1 来启动profile,session级别配置
2).执行查询
3).show profiles 查询SQL总的消耗时间
4).show profile for N 查看各个阶段消耗时间,N是指query_id
命令:show profiles

命令:show profile for query N

命令:show profile cpu for query N

2、使用performance_schema显示每个线程执行SQL的各个阶段消耗时间
特定的SQL查询优化:
1、对大表数据的修改最好分批次处理,例如:1000万行记录的表中删除100w条数据,一次删除5000条数据,每次删除之后暂停几秒,留给主从复制的时间
DELIMITER $$
USE mysql $$
DROP PROCEDURE IF EXISTS p_delete_rows $$
CREATE DEFINER=root@127.0.0.1 PROCEDURE p_delete_rows()
BEGIN
DECLARE v_rows INT;
SET v_rows=1;
WHILE v_rows > 0
DO
DELETE FROM sbtest WHERE id >= 90000 AND id <=390000 LIMIT 5000;
SELECT ROW_COUNT() INTO v_rows;
SELECT SLEEP(5);
END WHILE;
END $$
DELIMITER;
2、如何修改大表的表结构
1).现在从服务器上修改,然后主从切换,然后在原主服务器修改,但是有风险
2).

过程:
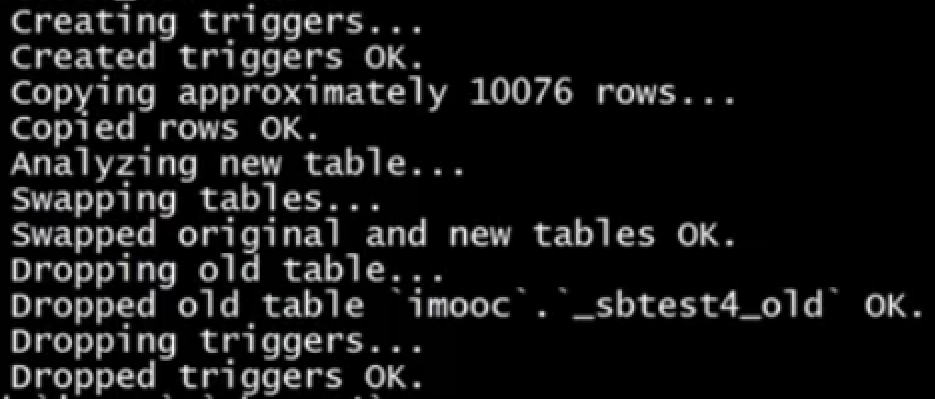
主服务器创建一个新表,就是想要修改后的表结构
然后将老表的数据复制到新表
通过触发器将两个表的数据进行同步
当数据一致的时候,在老表加排它锁,重命名新表,删除老表
可以通过pu-online-schema-change这个工具实现上面的工作
3、优化not in和<>
例如把not in,改写成left join避免多次子查询
MySQL系列(七)--SQL优化的步骤的更多相关文章
- (6)MySQL进阶篇SQL优化(MyISAM表锁)
1.MySQL锁概述 锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算资源 (如 CPU.RAM.I/O 等)的抢占以外,数据也是一种供许多用户共享的资源.如何保证数 据并 ...
- mysql 开发进阶篇系列 2 SQL优化(explain分析)
接着上一篇sql优化来说 1. 定位执行效率较低的sql 语句 通过两种方式可以定位出效率较低的sql 语句. (1) 通过上篇讲的慢日志定位,在mysqld里写一个包含所有执行时间超过 long_q ...
- mysql系列七、mysql索引优化、搜索引擎选择
一.建立适当的索引 说起提高数据库性能,索引是最物美价廉的东西了.不用加内存,不用改程序,不用调sql,只要执行个正确的'create index',查询速度就可能提高百倍千倍,这可真有诱惑力.可是天 ...
- (4)MySQL进阶篇SQL优化(常用SQL的优化)
1.概述 前面我们介绍了MySQL中怎么样通过索引来优化查询.日常开发中,除了使用查询外,我们还会使用一些其他的常用SQL,比如 INSERT.GROUP BY等.对于这些SQL语句,我们该怎么样进行 ...
- Mysql系列七:分库分表技术难题之分布式全局唯一id解决方案
一.前言 在前面的文章Mysql系列四:数据库分库分表基础理论中,已经说过分库分表需要应对的技术难题有如下几个: 1. 分布式全局唯一id 2. 分片规则和策略 3. 跨分片技术问题 4. 跨分片事物 ...
- [转]Mysql中的SQL优化与执行计划
From : http://religiose.iteye.com/blog/1685537 一,如何判断SQL的执行效率? 通过explain 关键字分析效率低的SQL执行计划. 比如: expla ...
- mysql 简单的sql优化示例[不定时更新]
对于慢sql的分析步骤: 1) desc|explain sql 查看执行计划, 对于type很慢的, 分析是否建立了对应字段的索引 2) 进行排除法, 把子查询抽离出来, 单独执行,定位慢查询是哪个 ...
- 字符串可以这样加索引,你知吗?《死磕MySQL系列 七》
系列文章 三.MySQL强人"锁"难<死磕MySQL系列 三> 四.S 锁与 X 锁的爱恨情仇<死磕MySQL系列 四> 五.如何选择普通索引和唯一索引&l ...
- mysql 开发进阶篇系列 4 SQL 优化(各种优化方法点)
1 通过handler_read 查看索引使用情况 如果索引经常被用到 那么handler_read_key的值将很高,这个值代表了一个行被索引值读的次数, 很低的值表明增加索引得到的性能改善不高,索 ...
随机推荐
- sql server2014显示sa无法登录的错误
博主用的是sql serser2014,不过这个问题的方法也适用于2012等其他版本. 当用sa登录的时候,提示如下错误: A connection was successfully establis ...
- OA系统和ERP系统的区别
一.OA和ERP的区别 1.含义不同: OA指Office Automation,中文简称自动办公系统,帮助企业内部管理沟通的工具,比如新闻公告.内部沟通.考勤.办公.员工请假.审批流程等. ERP指 ...
- spring:ApplicationContext的三个实现类
* ApplicationContest的三个常用实现类* ClassPathXmlApplicationContext:它可以加载类路径的配置文件,要求配置文件必须在类路径下,如果不在则加载不了* ...
- Java写爬虫代码时报org.apache.http.client.ClientProtocolException: URI does not specify a valid host异常的处理
异常原因是url写错,导致无法解析 比如:这个报错就是因为写了两个“http:”导致该无法解析
- iOS7 断了统计和追踪用户的后路
评论里大家都认可用identifierForVendor 然后用keychain和iCloud各保存一份. 看来这是接近最终结果的办法了. 官方文档又说了下面的话, 又有点费解. 我们只要把最后一组s ...
- Windows进程创建的流程分析
. 创建进程的大体流程: 创建进程的过程就是构建一个环境,这个环境包含了很多的机制 (比如自我保护, 与外界通信等等). 构建这个环境需要两种"人"来协调完成(用户态和内核 ...
- 84 落单的数 III
原题网址:http://www.lintcode.com/zh-cn/problem/single-number-iii/# 给出2*n + 2个的数字,除其中两个数字之外其他每个数字均出现两次,找到 ...
- solusvm 主控端迁移
难点在于solusvm被控端已经开了小鸡的情况. 备份数据库: #!/bin/sh ## Vars CONF=/usr/local/solusvm/includes/solusvm.conf FILE ...
- 利用R语言制作出漂亮的交互数据可视化
利用R语言制作出漂亮的交互数据可视化 利用R语言也可以制作出漂亮的交互数据可视化,下面和大家分享一些常用的交互可视化的R包. rCharts包 说起R语言的交互包,第一个想到的应该就是rCharts包 ...
- scrapy中的ImagePipeline下载图片到本地、并提取本地的保存地址
通过scrapy内置到ImagePipeline下载图片到本地 在settings中打开 ITEM_PIPELINES的注释,并在这里面加入 'scrapy.pipelines.images.Imag ...