TensorFlow——学习率衰减的使用方法
在TensorFlow的优化器中, 都要设置学习率。学习率是在精度和速度之间找到一个平衡:
学习率太大,训练的速度会有提升,但是结果的精度不够,而且还可能导致不能收敛出现震荡的情况。
学习率太小,精度会有所提升,但是训练的速度慢,耗费较多的时间。
因而我们可以使用退化学习率,又称为衰减学习率。它的作用是在训练的过程中,对学习率的值进行衰减,训练到达一定程度后,使用小的学习率来提高精度。
在TensorFlow中的方法如下:tf.train.exponential_decay(),该方法的参数如下:
learning_rate, 初始的学习率的值
global_step, 迭代步数变量
decay_steps, 带迭代多少次进行衰减
decay_rate, 迭代decay_steps次衰减的值
staircase=False, 默认为False,为True则不衰减
例如
tf.train.exponential_decay(initial_learning_rate, global_step=global_step, decay_steps=1000, decay_rate=0.9)表示没经过1000次的迭代,学习率变为原来的0.9。
增大批次处理样本的数量也可以起到退化学习率的作用。
下面我们写了一个例子,每迭代10次,则较小为原来的0.5,代码如下:
import tensorflow as tf
import numpy as np global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.1 learning_rate = tf.train.exponential_decay(initial_learning_rate,
global_step=global_step,
decay_steps=10,
decay_rate=0.5) opt = tf.train.GradientDescentOptimizer(learning_rate)
add_global = global_step.assign_add(1) with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(learning_rate)) for i in range(50):
g, rate = sess.run([add_global, learning_rate])
print(g, rate)
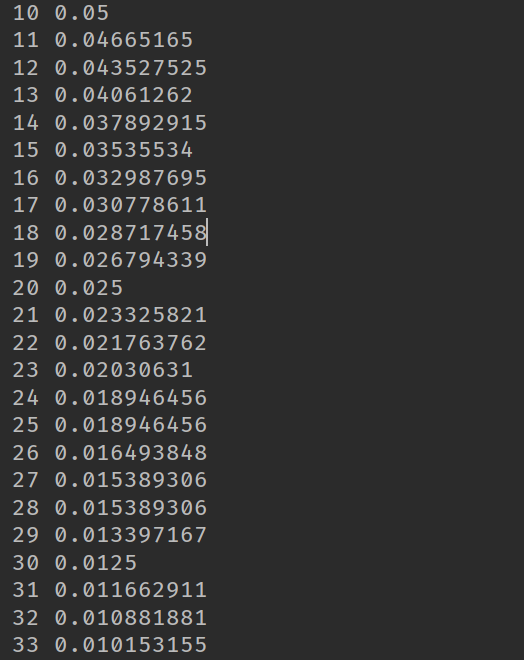
下面是程序的结果,我们发现没10次就变为原来的一般:
随后,又在MNIST上面进行了测试,发现使用学习率衰减使得准确率有较好的提升。代码如下:
import tensorflow as tf
import numpy as np
from tensorflow.examples.tutorials.mnist import input_data
import matplotlib.pyplot as plt mnist = input_data.read_data_sets('MNIST_data', one_hot=True) tf.reset_default_graph() x = tf.placeholder(tf.float32, [None, 784])
y = tf.placeholder(tf.float32, [None, 10]) w = tf.Variable(tf.random_normal([784, 10]))
b = tf.Variable(tf.zeros([10])) pred = tf.matmul(x, w) + b
pred = tf.nn.softmax(pred) cost = tf.reduce_mean(-tf.reduce_sum(y * tf.log(pred), reduction_indices=1)) global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.1 learning_rate = tf.train.exponential_decay(initial_learning_rate,
global_step=global_step,
decay_steps=1000,
decay_rate=0.9) opt = tf.train.GradientDescentOptimizer(learning_rate)
add_global = global_step.assign_add(1) optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost) training_epochs = 50
batch_size = 100 display_step = 1 with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples/batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
_, c, add, rate = sess.run([optimizer, cost, add_global, learning_rate], feed_dict={x:batch_xs, y:batch_ys})
avg_cost += c / total_batch if (epoch + 1) % display_step == 0:
print('epoch= ', epoch+1, ' cost= ', avg_cost, 'add_global=', add, 'rate=', rate)
print('finished') correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print('accuracy: ', accuracy.eval({x:mnist.test.images, y:mnist.test.labels}))
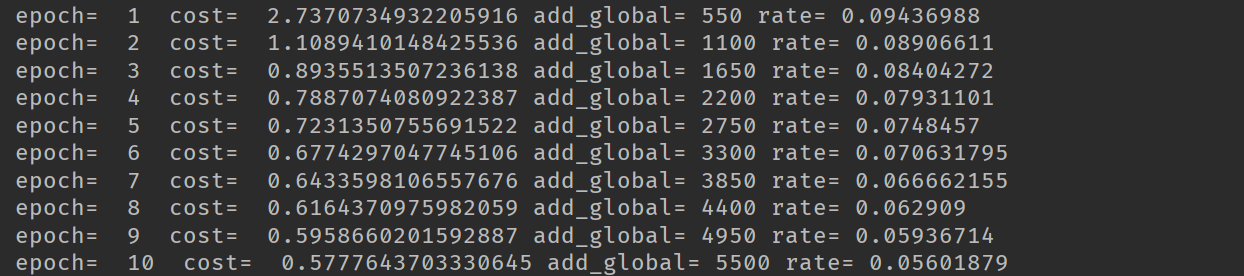
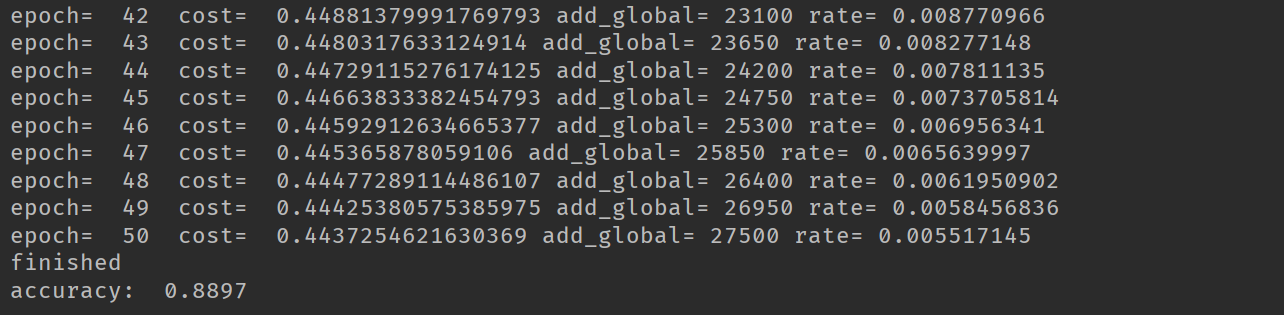
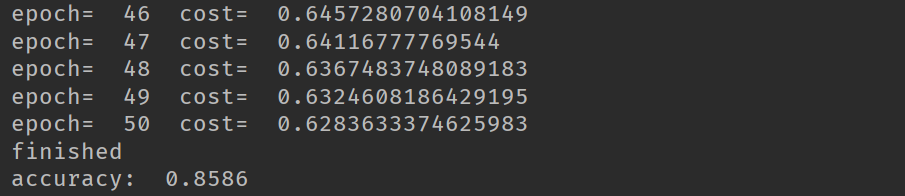
在使用衰减学习率我们最后的精度达到0.8897,在使用固定的学习率时,精度只有0.8586。
TensorFlow——学习率衰减的使用方法的更多相关文章
- TensorFlow之DNN(二):全连接神经网络的加速技巧(Xavier初始化、Adam、Batch Norm、学习率衰减与梯度截断)
在上一篇博客<TensorFlow之DNN(一):构建“裸机版”全连接神经网络>中,我整理了一个用TensorFlow实现的简单全连接神经网络模型,没有运用加速技巧(小批量梯度下降不算哦) ...
- Tensorflow实现学习率衰减
Tensorflow实现学习率衰减 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 Deeplearning AI Andrew Ng Tensorflow1.2 API 学习率衰减 ...
- Adam和学习率衰减(learning learning decay)
目录 梯度下降法更新参数 Adam 更新参数 Adam + 学习率衰减 Adam 衰减的学习率 References 本文先介绍一般的梯度下降法是如何更新参数的,然后介绍 Adam 如何更新参数,以及 ...
- 改善深层神经网络_优化算法_mini-batch梯度下降、指数加权平均、动量梯度下降、RMSprop、Adam优化、学习率衰减
1.mini-batch梯度下降 在前面学习向量化时,知道了可以将训练样本横向堆叠,形成一个输入矩阵和对应的输出矩阵: 当数据量不是太大时,这样做当然会充分利用向量化的优点,一次训练中就可以将所有训练 ...
- Dropout和学习率衰减
Dropout 在机器学习的模型中,如果模型的参数太多,而训练样本又太少,训练出来的模型很容易产生过拟合的现象.在训练神经网络的时候经常会遇到过拟合的问题,过拟合具体表现在:模型在训练数据上 ...
- [深度学习] pytorch学习笔记(3)(visdom可视化、正则化、动量、学习率衰减、BN)
一.visdom可视化工具 安装:pip install visdom 启动:命令行直接运行visdom 打开WEB:在浏览器使用http://localhost:8097打开visdom界面 二.使 ...
- 权重衰减(weight decay)与学习率衰减(learning rate decay)
本文链接:https://blog.csdn.net/program_developer/article/details/80867468“微信公众号” 1. 权重衰减(weight decay)L2 ...
- TensorFlow模型保存和加载方法
TensorFlow模型保存和加载方法 模型保存 import tensorflow as tf w1 = tf.Variable(tf.constant(2.0, shape=[1]), name= ...
- 吴恩达深度学习笔记(五) —— 优化算法:Mini-Batch GD、Momentum、RMSprop、Adam、学习率衰减
主要内容: 一.Mini-Batch Gradient descent 二.Momentum 四.RMSprop 五.Adam 六.优化算法性能比较 七.学习率衰减 一.Mini-Batch Grad ...
随机推荐
- C++继承方式
C++的继承方式有三种,分别为: 公有继承:public 私有继承:private 保护继承:protected 定义格式为: class<派生类名>:<继承方式><基类 ...
- java方法里的属性
访问控制符:访问控制符限定方法的可见范围,或者说是方法被调用的范围.方法的访问控制符有四种,按可见范围从大到小依次是:public.protected,无访问控制符,private.其中无访问控制符不 ...
- 设置html各元素不可点击(持续更新)
1.span <span id="nextStep" onclick="right">下一页</span> $("#nextS ...
- linux一些重要数据结构
如同你想象的, 注册设备编号仅仅是驱动代码必须进行的诸多任务中的第一个. 我们将很 快看到其他重要的驱动组件, 但首先需要涉及一个别的. 大部分的基础性的驱动操作包括 3 个重要的内核数据结构, 称为 ...
- H3C DHCP系统组成
- P1035 台阶问题二
题目描述 有 \(N\) 级的台阶,你一开始在底部,每次可以向上迈最多 \(K\) 级台阶(最少 \(1\) 级),问到达第 \(N\) 级台阶有多少种不同方式. 输入格式 两个正整数 \(N, K( ...
- intellij 创建一个文件自动就add到git了,这个怎么取消
解决方案一: 展开全部 打开IDEA->File->Settings->VersionControl->Confirmation 上面有个When files are crea ...
- while循环&CPU占用率高问题深入分析与解决方案
直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方.使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果, ...
- H3C配置BPDU的生成和传递
- SDOI2019热闹又尴尬的聚会
P5361 [SDOI2019]热闹又尴尬的聚会 出题人用脚造数据系列 只要将\(p\)最大的只求出来,\(q\)直接随便rand就能过 真的是 我们说说怎么求最大的\(p\),这个玩意具有很明显的单 ...