Apache Kafka(五)- Safe Kafka Producer
Kafka Safe Producer
在应用Kafka的场景中,需要考虑到在异常发生时(如网络异常),被发送的消息有可能会出现丢失、乱序、以及重复消息。
对于这些情况,我们可以创建一个“safe producer”,用于规避这些问题。下面我们会先介绍对于这几种情况的说明以及配置,最后给出一个配置示例。
1. acks 详述
之前我们介绍过 Kafka Producer 的 acks 有三种模式,下面我们进一步介绍一下这三种模式:
1.1. acks = 0(no acks)
使用acks=0 时,也就意味着:
- 在发送一条message 后,不需要response
- 如果broker 下线或是发生了故障,则我们不会知道,并且会丢失数据,因为broker不会返回任何response 给producers
acks=0 的工作方式如下图,不需要收到任何 ack:

一般使用 acks=0 的场景为:可以接受可能丢失数据。例如:
- 指标信息收集
- 日志收集(可接受偶尔丢失几条log数据)
1.2. acks=1(leader acks)
使用acks=1 时:
- producer需要获取leader 的response,才能确认消息已被收到。但是replication是否收到则不会保证(会在后台执行replication)
- 如果producer 没有收到ack,则可能会retry
acks=1 的工作方式如下图,Producer需要收到每条消息的ack:

- 如果leader broker下线或是发生故障,但是replicas还没有复制发送的数据,则我们也会有数据丢失
- 默认是这个模式
1.3. acks=all(replicas acks)
使用acks=all 时:
- 需要Leader与Replicas的ack
- 增加了latency与更高的“数据不丢失”安全性
- 如果有足够的replicas,则不会有数据丢失
acks=all的一个工作方式如下,每个replica都需要回复ack,才能保证一个write的写入:
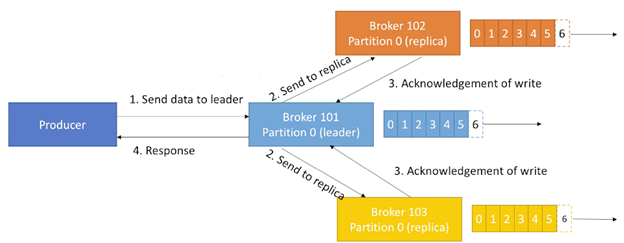
如果是需要完全不丢失数据,则这个设置是有必要考虑的。
在设置 acks=all(也就是replica acks)时,必须与另一个参数一起用,也就是:min.insync.replicas:
- min.insync.replicas参数可以在broker level设置或是topic level设置(override)
- min.insync.replicas=2表示的是:至少2个brokers是ISR(in-sync replicas)(包括leader),且必须响应表示它们有数据,否则就会返回报错。设置此参数为2也是最常见的配置。
假设设置参数replication.factor=3, min.insync=2, acks=all,则最多只能容许1一个broker异常,否则producer在发送数据时会收到报错。
假设有3个brokers,min.insync.replicas=2,若其中有两个broker异常,则Producer会收到“NOT_ENOUGH_REPLICAS”的异常。
2. Producer Retry
为了防止一些瞬时的错误(例如NotEnoughReplicasException)影响整个应用,一般我们需要处理一些异常,以避免数据丢失。在Producer中也有重试的配置,默认为0,可以手动调整它的值,最高可以到Integer.MAX_VALUE。
在重试时,默认情况下,会有可能造成消息发送时乱序。因为一般发送失败的消息会被re-queue,然后再次发送,所以会造成部分消息乱序。
此情况在key-based 序列消息中,尤为严重。因为所有具有相同key的messages会被送往同一个partition,而若是有消息被requeue,然后重传,则会打乱这个partition中的部分key顺序。
对于这种情况,我们可以设置参数max.in.flight.requests.per.connection控制:同一时刻,有多少个produce请求可以被并行发起:
- 默认为5
- 如果为了完全确保重试后的消息也能保持严格有序,则可以设置此参数为1(但是可能会影响throughput)
不过在 Kafka >= 1.0.0中,对于此场景会有更好的解决方案,本文之后的部分会提及。
3. Idempotent Producer
在重传场景中,会遇到一个常见的问题是:由于网络的原因,Producer会在Kafka中引入重复的messages。
如下图所示:

一个正常的request请求为:
- Producer 发送消息到Kafka
- Kafka commit 这条消息
- Kafka发送ack回Producer
但是一个产生重复消息的请求过程为:
- Producer发送消息到Kafka
- Kafka commit 这条消息
- Kafka发送ack回Producer时,由于网络原因,ack未到达Producer端
- Producer过一段时间后开始重传消息
- Kafka commit这条重复的消息并返回ack给Producer
从Producer的角度看,它仅正常发送了一次消息,因为它只收到了一次 ack。从Kafka的角度看,它收到了两次消息,所以commit了两次。
在Kafka >= 0.11之后,可以定义一个“idempotent producer”,可以解决由网络问题造成的重复消息。如下图所示:

对于一个idempotent producer 来说,处理重复消息的请求过程为:
- Producer 发送一条消息
- Kafka收到消息并commit
- Kafka发送回Producer的ack由于网络问题未到达Producer
- Producer重试发送消息,在Producer>=0.11 的版本中,消息里会带上一个produce request id
- Kafka收到消息后,通过对比produce request id,可以辨别出这条消息是一条重复的消息,所以不会再次commit,并会再次发送一个ack
Idempotent producers可以很好的保证一个稳定,以及无重复数据的pipeline。
伴随Idempotent producers一起被设置的参数有:
- retries = Integer.MAX_VALUE (2^31-1 = 2147483647),也就是说基本会在出错时无限重传
- max.in.flight.requests=1 (Kafka >= 0.11 & < 1.1) ,也就是说在这些版本中,若是设置max.in.flight.requests > 1时仍会有可能产生乱序数据
- 或者 max.in.flight.requests=5 (Kafka >= 1.1 –> High Performance),也就是说在高于1.1版本的Kafka中,设置max.in.flight.requests=5也可以在保证不乱序的同时,保证并行的高性能
对于Idempotent Producer的配置,仅需配置类似以下参数即可:
properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
4. Safe Producer 配置总结
上面介绍了创建一个safe producer 所需的配置,下面我们总结一下在不同版本的Kafka中所需要做的配置:
Kafka < 0.11
- ack=all (procuder level):确保在发送ack前,数据已经正常备份
- min.insync.replicas=2 (broker/topic level):确保至少有两个in ISR 的brokers 有数据后再回送ack
- retires=MAX_INT (producer level):确保在发生瞬时问题时,可以无限次重试
- max.in.flight.requests.per.connection=1 (producer level):确保每次仅有一个请求发送,防止在重试时产生乱序数据
Kafka >= 0.11
- enable.idempotence=true (producer level) + min.insync.replicas=2 (broker/topic level)
- 隐含的配置为 acks=all, retries=MAX_INT, max.in.flight.requests.per.connection=5 (default)
- 可以在保证消息顺序的同时,提高performance
这里必须要提到的是:运行一个“safe producer”可能会影响系统的throughput与latency,所以在应用到生产系统前,必须先做测试以判断影响。
5. safe producer 示例
我们按照之前的步骤启动一个由Java编写的Kafka Producer,并查看输出的配置,可以看到默认的部分参数为:
acks = 1
enable.idempotence = false
max.in.flight.requests.per.connection = 5
retries = 2147483647
现在我们显式地加上以下参数:
// create a safe Producer
properties.setProperty(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
properties.setProperty(ProducerConfig.ACKS_CONFIG, "all");
properties.setProperty(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, "5");
properties.setProperty(ProducerConfig.RETRIES_CONFIG, Integer.toString(Integer.MAX_VALUE));
然后查看producer配置的部分输出为:
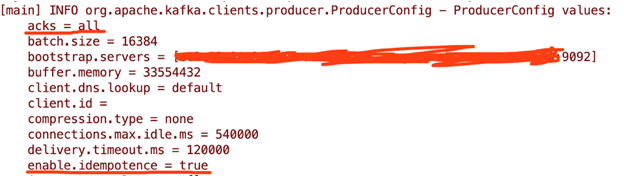

以上为创建一个safe producer所需的配置介绍以及示例,在实际生产环境中,务必要先测试safe producer 对应用吞吐以及延时的影响后,再斟酌是否有必要对参数做部分调整。
Apache Kafka(五)- Safe Kafka Producer的更多相关文章
- Kafka(五) —— Kafka源码本地调试
搭建环境 安装scala 安装gradle 在kafka源码的根目录执行命令 gradle wrapper gradle idea 打开IDEA,File -> Open -> kafka ...
- Kafka(五)Kafka的API操作和拦截器
一 kafka的API操作 1.1 环境准备 1)在eclipse中创建一个java工程 2)在工程的根目录创建一个lib文件夹 3)解压kafka安装包,将安装包libs目录下的jar包拷贝到工程的 ...
- kafka C客户端librdkafka producer源码分析
from:http://www.cnblogs.com/xhcqwl/p/3905412.html kafka C客户端librdkafka producer源码分析 简介 kafka网站上提供了C语 ...
- Kafka系列之-自定义Producer
前面已经讲到了,在Kafka中,Message是由Producer产生的,Producer产生的Message会发送到Topic的指定Partition中.Producer可以有多种形式,也可以由用户 ...
- Apache Kafka监控之Kafka Web Console
Kafka Web Console:是一款开源的系统,源码的地址在https://github.com/claudemamo/kafka-web-console中.Kafka Web Console也 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十四)定义一个avro schema使用comsumer发送avro字符流,producer接受avro字符流并解析
参考<在Kafka中使用Avro编码消息:Consumer篇>.<在Kafka中使用Avro编码消息:Producter篇> 在了解如何avro发送到kafka,再从kafka ...
- Kafka设计解析(五)Kafka性能测试方法及Benchmark报告
转载自 技术世界,原文链接 Kafka设计解析(五)- Kafka性能测试方法及Benchmark报告 摘要 本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafk ...
- 如何创建Kafka客户端:Avro Producer和Consumer Client
1.目标 - Kafka客户端 在本文的Kafka客户端中,我们将学习如何使用Kafka API 创建Apache Kafka客户端.有几种方法可以创建Kafka客户端,例如最多一次,至少一次,以及一 ...
- Kafka设计解析(五)- Kafka性能测试方法及Benchmark报告
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/12/31/KafkaColumn5_kafka_benchmark 摘要 本文主要介绍了如何利用 ...
随机推荐
- HDU 6417
题意 英文 做法 \(S_{a,b}\)为\(a\)与\(b\)中素数次幂奇偶性不同的集合,容易得出\[d_{a,b}=\left\{\begin{aligned}1 &&|S_{a, ...
- python中的__dict__和dir()的区别
Python下一切皆对象,每个对象都有多个属性(attribute),Python对属性有一套统一的管理方案. __dict__与dir()的区别: dir()是一个函数,返回的是list: __di ...
- [POI2008] PLA-Postering - 单调栈
给你 \(n\) 个相连的矩形建筑,让你用最少海报把他们覆盖掉,海报不能重叠,也不可以高出被覆盖的矩形. Solution 考虑维护一个单调递增的栈,每次插入时弹掉所有比自己高的,如果自己和末端一样高 ...
- C++->二进制文件流的输入输出
C++->文件流的输入输出 1.书本里以“简单事务处理”为例子,解析二进制输入输出文件流的read和write函数的使用,以及输入输出文件流 过程中指针的捕获.定位,文件流位置的判断,二进制文件 ...
- CSS:display:flex详解
水平居中很容易实现,但是一般垂直居中好像不是很好实现,一般我们都会用position.left等等进行定位:但是flex很好的解决了这个问题 Flex就是"弹性布局",现在应用很多 ...
- AcWing 1057. 股票买卖 IV
//f[i,j,1]表示走到第i天已经进行完j次交易并且手中没有股票的所有的购买方式的集合 //f[i,j,0]表示走到第i天并且正在进行第j次交易且手中有货的所有的购买方式的集合 //属性利益最大值 ...
- SQLyog怎么导入mysql数据库
参考链接:https://jingyan.baidu.com/article/647f0115c5ad9f7f2148a8c6.html
- MongoDB geonear和文本命令驱动程序2.0
文本查询,q作为查询字符串: coll.FindAsync<Foo>(Builders<Foo>.Filter.Text(q)); 文本查询需要一个文本索引.要从C#创建代码, ...
- php执行shell脚本
本次想要配置webhook钩子, 做钩子大多是走 ssh 协议, coding 里配置部署公钥 之前用 docker 写钩子, 也是 ssh 权限的问题 包工具: 1.composer r ...
- Selenium3+python自动化010-UnitTest框架简介和单元测试框架使用
一.UnitTest介绍 unittest单元测试框架不仅可以适用于单元测试,还可以适用WEB自动化测试用例的开发与执行,该测试框架可组织执行测试用例,并且提供了丰富的断言方法,判断测试用例是否通过, ...