个性化重排--Personalized Re-ranking for Recommendation
推荐中的个性化重排--Personalized Re-ranking for Recommendation
这篇文章是阿里在ResSys'19发表的,主要贡献是在重排序阶段,引入了用户的相关信息,很符合实际场景。
- PRM的提出
重排主要是对排序后结果的优化,也可以用于二次推荐。考虑到性能原因,典型的排序技术是基于pointwise的,给定一个query,系统对每个物品进行打分,按照打分结果进行排序。pointwise不考虑排序列表中物品之间的相关性,为了解决这个问题,有两种主流做法:
pairwise和listwise:pairwise和listwise考虑列表中物品间的相关性
建模物品之间的相互作用:基于RNN的方法是目前的SOTA,输入初始列表,输出编码后的列表[2].RNN存在两个问题,一是距离限制,二是无法有效的对列表中物品进行交互。
直观上来说,用户的行为信息也应该被加入到重排,因为不同用户的倾向性不同。假如用户更关注价格,重排时价格就需要更多关注。文章提出基于Transformer的个性化重排,
- 假如用户和列表中物品的交互,更加合理
- Transformer的self-attention机制有效捕捉特征间的交互,改善了基于RNN方法的缺点
- 模型细节
先看图

个性化重排的个性化就体现在加入了用户个性化向量\(pv\),可以建模用户个性和物品之间的相互关系。
输入层
输入层由三部分组成:原始特征、个性化特征、位置特征
给定初始列表\(\mathcal{S}=\left[i_{1}, i_{2}, \ldots, i_{n}\right]\),原始特征矩阵\(X \in \mathbb{R}^{n \times d_{\text {feature }}}\),\(X\)的每行\(x_i\)对应\(i \in S\)的特征向量。\(P V \in \mathbb{R}^{n \times d_{\mathrm{pv}}}\)是个性化矩阵,由预训练得到。\(PE \in \mathbb{R}^{\boldsymbol{n} \times\left(d_{\text {feature }}+d_{p v}\right)}\)表示位置编码,初始列表中物品的位置.
\[
E^{\prime \prime}=\left[\begin{array}{c}
{x_{i_{1}} ; p v_{i_{1}}} \\
{x_{i_{2}} ; p v_{i_{2}}} \\
{\cdots} \\
{x_{i_{n}} ; p v_{i_{n}}}
\end{array}\right]+\left[\begin{array}{c}
{p e_{i_{1}}} \\
{p e_{i_{2}}} \\
{\cdots} \\
{p e_{i_{n}}}
\end{array}\right]
\]
其中\(E^{\prime \prime} \in \mathbb{R}^{n \times\left(d_{\text {feature }}+d_{p v}\right)}\),为了将\(E^{''}\)转化\(d\)维的\(E\),使用前馈神经网络转化下:
\[
E=E W^{E}+b^{E}
\]
此处有一个疑问,为什么需要做这一步降维?直接将拼接后的向量送入编码层不可以吗?
编码层
编码层目标在于整合对列表中物品的相互影响,以及用户行为和列表中物品的相互影响。这里使用了Transformer的编码部分,可以看图(a).
输出层
输出层使用\(softmax\)输出一个分数列表,根据分数就可以实现重排。具体来说,
\[
\text { Score }(i)=P\left(y_{i} | X, P V ; \hat{\theta}\right)=\operatorname{softmax}\left(F^{\left(N_{x}\right)} W^{F}+b^{F}\right), i \in \mathcal{S}_{r}
\]
其中\(F^{\left(N_{x}\right)}\)是Transformer部分的输出。对应的损失函数为
\[
\mathcal{L}=-\sum_{r \in \mathcal{R}} \sum_{i \in S_{r}} y_{i} \log \left(P\left(y_{i} | X, P V ; \hat{\theta}\right)\right.
\]
其中\(\mathcal{R}\)是所有用户的请求的集合。即保证重排后的列表尽可能的符合每个用户
预训练个性化向量
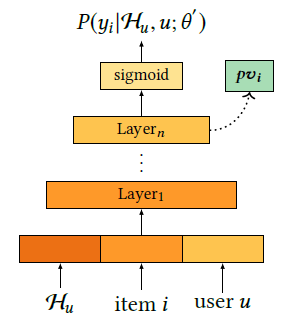
预训练网络将点击率作为目标,利用网络的隐层向量作为个性化向量。就是预训练模型的经典操作。对应的损失函数
\[
\begin{aligned}\mathcal{L}=\sum_{i \in \mathcal{D}}\left(y_{i} \log \left(P\left(y_{i} | \mathcal{H}_{u}, u ; \theta^{\prime}\right)\right)\right.+\left(1-y_{i}\right) \log \left(1-P\left(y_{i} | \mathcal{H}_{u}, u ; \theta^{\prime}\right)\right)\end{aligned}
\]
其中\(\mathcal H _u\)表示用户的历史行为信息,item表示物品信息,user表示人口统计学信息。可以看出个性化向量的预训练网络就是一个CTR预估网络,因此经典的Wide&Depp,DeepFM等网络都可以用来做预训练。
- 讨论
- 文章的创新主要是重排阶段引入了用户的相关特征。个人认为可以用于二次推荐,应该有帮助
- 输入层最后那个操作没有太搞明白,有理解不到位的地方欢迎讨论。
references:
Personalized Re-ranking for Recommendation.https://arxiv.org/pdf/1904.06813.pdf
个性化重排--Personalized Re-ranking for Recommendation的更多相关文章
- [转]Magento on Steroids – Best practice for highest performance
本文转自:https://www.mgt-commerce.com/blog/magento-on-steroids-best-practice-for-highest-performance/ Th ...
- 【RS】RankMBPR:Rank-Aware Mutual Bayesian Personalized Ranking for Item Recommendation - RankMBPR:基于排序感知的相互贝叶斯个性化排序的项目推荐
[论文标题]RankMBPR:Rank-Aware Mutual Bayesian Personalized Ranking for Item Recommendation ( WAIM 2016: ...
- 【RS】Using graded implicit feedback for bayesian personalized ranking - 使用分级隐式反馈来进行贝叶斯个性化排序
[论文标题]Using graded implicit feedback for bayesian personalized ranking (RecSys '14 recsys.ACM ) [论文 ...
- 【RS】BPR:Bayesian Personalized Ranking from Implicit Feedback - BPR:利用隐反馈的贝叶斯个性化排序
[论文标题]BPR:Bayesian Personalized Ranking from Implicit Feedback (2012,Published by ACM Press) [论文作者]S ...
- Bayesian Personalized Ranking 算法解析及Python实现
1. Learning to Rank 1.1 什么是排序算法 为什么google搜索 ”idiot“ 后,会出现特朗普的照片? “我们已经爬取和存储了数十亿的网页拷贝在我们相应的索引位置.因此,你输 ...
- A context-aware personalized travel recommendation system based on geotagged social media data mining
文章简介:利用社交网站Flickr上照片的geotag信息将这些照片聚类发现城市里的旅游景点,通过各照片的拍照时间得到用户访问某景点时的时间上下文和天气上下文(利用时间和public API of W ...
- VBPR: Visual Bayesian Personalized Ranking from Implicit Feedback-AAAI2016 -20160422
1.Information publication:AAAI2016 2.What 基于BPR模型的改进:在商品喜好偏序对的学习中,将商品图片的视觉信息加入进去,冷启动问题. 3.Dataset Am ...
- GBPR: Group Preference Based Bayesian Personalized Ranking for One-Class Collaborative Filtering-IJACA 2013_20160421
1.Information publication:IJACA 2013 2.What 基于BPR模型的改进:改变BPR模型中,a,用户对商品喜好偏序对之间相互独立;b,用户之间相互独立的假设 原因: ...
- BPR: Bayesian Personalized Ranking from Implicit Feedback-CoRR 2012——20160421
1.Information publication:CoRR 2012 2.What 商品推荐中常用的方法矩阵因子分解(MF),协同过滤(KNN)只考虑了用户购买的商品,文章提出利用购买与未购买的偏序 ...
随机推荐
- LightOJ 1269 Consecutive Sum (Trie树)
Jan's LightOJ :: Problem 1269 - Consecutive Sum 题意是,求给定序列的中,子序列最大最小的抑或和. 做法就是用一棵Trie树,记录数的每一位是0还是1.查 ...
- 2016 年度开源中国新增开源软件排行榜 TOP 100
2016 年度开源中国新增开源软件排行榜 TOP 100 2016 年度开源中国新增开源软件排行榜 TOP 100 新鲜出炉!本榜单根据 2016 年开源中国新收录的 3030 款软件的关注度和活跃度 ...
- 2002年NOIP普及组复赛题解
题目涉及算法: 级数求和:入门题: 选数:搜索: 产生数:搜索.高精度: 过河卒:动态规划. 级数求和 题目链接:https://www.luogu.org/problemnew/show/P1035 ...
- 洛谷P2719 搞笑世界杯 题解 概率DP入门
作者:zifeiy 标签:概率DP 题目链接:https://www.luogu.org/problem/P2719 我们设 f[n][m] 用于表示还剩下n张A类票m张B类票时最后两张票相同的概率, ...
- [转]解决pip安装太慢的问题
阅读目录 临时使用: 经常在使用Python的时候需要安装各种模块,而pip是很强大的模块安装工具,但是由于国外官方pypi经常被墙,导致不可用,所以我们最好是将自己使用的pip源更换一下,这样就能解 ...
- html(二)登陆页面
今天开始正常上课学习HTML+CSS+JSP 嗯 前两个没讲直接上手! 老师也是很认同我们的呢~ 这是第一个案例 做一个登陆页面,并利用post提交表单 传值到另一个界面接收值. 1.设置值: &l ...
- PC端页面如何调用QQ进行在线聊天?
pc端如何实现QQ在线咨询? html代码如下: <a href="tencent://message/?uin=1234567&Site=Sambow&Menu=ye ...
- python基础数据类型汇总
list和dict 在循环一个列表和字典时,最好不要删除其中的元素,这样会使索引发生改变,从而报错! lis = [11, 22, 33, 44, 55] for i in range(len(lis ...
- 原 Linux:ping不通baidu.com
如果某台Linux服务器ping不通域名, 如下提示: [root@localhost ~]# ping www.baidu.com ping: unknown host www.baidu.com ...
- 节点列表和HTML集合
getElementsByName()和getElementByTagName()返回的都是NodeList集合. 而document.images和document0.forms的属性为HTMLCo ...