PAI-STUDIO通过Tensorflow处理MaxCompute表数据
PAI-STUDIO在支持OSS数据源的基础上,增加了对MaxCompute表的数据支持。用户可以直接使用PAI-STUDIO的Tensorflow组件读写MaxCompute数据,本教程将提供完整数据和代码供大家测试。
详细流程
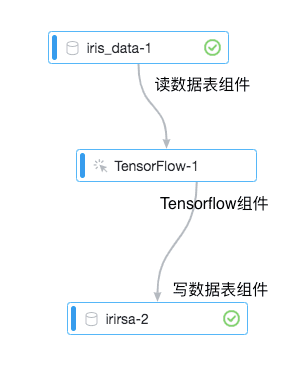
为了方便用户快速上手,本文档将以训练iris数据集为例,介绍如何跑通实验。
1.读数据表组件
为了方便大家,我们提供了一份公共读的数据供大家测试,只要拖出读数据表组件,输入:
pai_online_project.iris_data
即可获取数据,
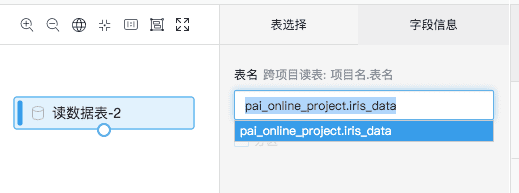
数据格式如图:

2.Tensorflow组件说明
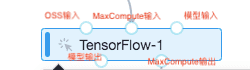
3个输入桩从左到右分别是OSS输入、MaxCompute输入、模型输入。2个输出桩分别是模型输出、MaxCompute输出。如果输入是一个MaxCompute表,输出也是一个MaxCompute表,需要按下图方法连接。
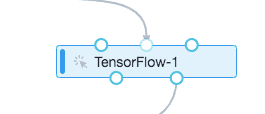
读写MaxCompute表需要配置数据源、代码文件、输出模型路径、建表等操作。
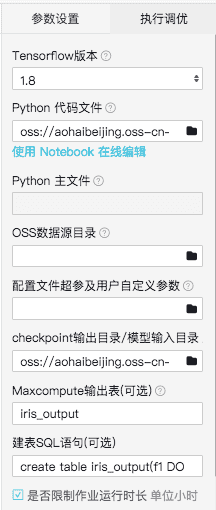
- Python代码文件:需要把执行代码放到OSS路径下(注意OSS需要与当前项目在同一区域),本文提供的代码可以在下方连接下载(代码需要按照下方代码说明文案调整):http://docs-aliyun.cn-hangzhou.oss.aliyun-inc.com/assets/attach/129749/cn_zh/1565333220966/iristest.py?spm=a2c4g.11186623.2.10.50c46b36PlNwcq&file=iristest.py
- Checkpoint输出目录/模型输入目录:选择自己的OSS路径用来存放模型
- MaxCompute输出表:写MaxCompute表要求输出表是已经存在的表,并且输出的表名需要跟代码中的输出表名一致。在本案例中需要填写“iris_output”
- 建表SQL语句:如果代码中的输出表并不存在,可以通过这个输入框输入建表语句自动建表。本案例中建表语句“create table iris_output(f1 DOUBLE,f2 DOUBLE,f3 DOUBLE,f4 DOUBLE,f5 STRING);”
组件PAI命令
PAI -name tensorflow180_ext -project algo_public -Doutputs="odps://${当前项目名}/tables/${输出表名}" -DossHost="${OSS的host}" -Dtables="odps://${当前项目名}/tables/${输入表名}" -DgpuRequired="${GPU卡数}" -Darn="${OSS访问RoleARN}" -Dscript="${执行的代码文件}";
上述命令中的${}需要替换成用户真实数据
3.代码说明
import tensorflow as tf
tf.app.flags.DEFINE_string("tables", "", "tables info")
FLAGS = tf.app.flags.FLAGS
print("tables:" + FLAGS.tables)
tables = [FLAGS.tables]
filename_queue = tf.train.string_input_producer(tables, num_epochs=1)
reader = tf.TableRecordReader()
key, value = reader.read(filename_queue)
record_defaults = [[1.0], [1.0], [1.0], [1.0], ["Iris-virginica"]]
col1, col2, col3, col4, col5 = tf.decode_csv(value, record_defaults = record_defaults)
# line 9 and 10 can be written like below for short. It will be helpful when too many columns exist.
# record_defaults = [[1.0]] * 4 + [["Iris-virginica"]]
# value_list = tf.decode_csv(value, record_defaults = record_defaults)
writer = tf.TableRecordWriter("odps://pai_bj_test2/tables/iris_output")
write_to_table = writer.write([0, 1, 2, 3, 4], [col1, col2, col3, col4, col5])
# line 16 can be written like below for short. It will be helpful when too many columns exist.
# write_to_table = writer.write(range(5), value_list)
close_table = writer.close()
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
sess.run(tf.local_variables_initializer())
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
try:
step = 0
while not coord.should_stop():
step += 1
sess.run(write_to_table)
except tf.errors.OutOfRangeError:
print('%d records copied' % step)
finally:
sess.run(close_table)
coord.request_stop()
coord.join(threads)
- 读数据表
tables = [FLAGS.tables]
filename_queue = tf.train.string_input_producer(tables, num_epochs=1)
reader = tf.TableRecordReader()
key, value = reader.read(filename_queue)
record_defaults = [[1.0], [1.0], [1.0], [1.0], ["Iris-virginica"]]
其中FLAGS.tables是前端配置的输入表名的传参变量,对应组件的MaxCompute输入桩:

- 写数据表
writer = tf.TableRecordWriter("odps://pai_bj_test2/tables/iris_output")
write_to_table = writer.write([0, 1, 2, 3, 4], [col1, col2, col3, col4, col5])
TableRecordWriter中的格式为odps://当前项目名/tables/输出表名
本文作者:傲海
本文为云栖社区原创内容,未经允许不得转载。
PAI-STUDIO通过Tensorflow处理MaxCompute表数据的更多相关文章
- Unity中启动VS时出现"Visual Studio 2010 Shell 无效的许可证数据"的解决办法
(感觉还是cnblog好一点,刚注册成功赶紧把baidu hi的一篇文章搬过来试试) 一直用着Visual Studio 2013给Unity写代码,安装了SQL Server 2014后,在Unit ...
- Sql Server 导入还有一个数据库中的表数据
在涉及到SQL Server编程或是管理时一定会用到数据的导入与导出, 导入导出的方法有多种,此处以SQL Server导入表数据为例.阐述一下: 1.打开SQL Server Management ...
- MaxCompute表设计最佳实践
MaxCompute表设计最佳实践 产生大量小文件的操作 MaxCompute表的小文件会影响存储和计算性能,因此我们先介绍下什么样的操作会产生大量小文件,从 而在做表设计的时候考虑避开此类操作. 使 ...
- MaxCompute 表(Table)设计规范
表的限制项 表(Table)设计规范 表设计主要目标 表设计的影响 表设计步骤 表数据存储规范 按数据分层规范数据生命周期 按数据的变更和历史规范数据的保存 数据导入通道与表设计 分区设计与逻辑存储的 ...
- Oracle数据库验证IMP导入元数据是否会覆盖历史表数据
场景:imp导入数据时,最终触发器报错退出,并未导入存储过程.触发器.函数. 现在exp单独导出元数据,然后imp导入元数据,验证是否会影响已导入的表数据. 测试环境:CentOS 6.7 + Ora ...
- SQL Server 更改跟踪(Chang Tracking)监控表数据
一.本文所涉及的内容(Contents) 本文所涉及的内容(Contents) 背景(Contexts) 主要区别与对比(Compare) 实现监控表数据步骤(Process) 参考文献(Refere ...
- discuz X3.1 关于分表 和 分表数据迁移
// *********** 关于读取分表的数据*********** { // forum_thread 分表代码片段 -- 帖子列表 { // 定位某个板块的帖子落在哪个表(forum_threa ...
- SQL复制表结构或表数据
需求: 软件开发过程中,一般会部署两个数据库:一个测试数据库提供给开发和测试过程使用:一个运维数据库提供上线使用.当需求变化需增加表时,会遇到数据库表结构或表数据同步的问题,这时就要复制表结构或表数据 ...
- 如何在Oracle中复制表结构和表数据
1. 复制表结构及其数据: create table table_name_new as select * from table_name_old 2. 只复制表结构: create table ta ...
随机推荐
- Consul 安装的与启动
1.下载地址:https://www.consul.io/downloads.html linux 下载地址: wget https://releases.hashicorp.com/consul/0 ...
- hibernate查询timestamp条件
参考https://blog.csdn.net/zuozuoshenghen/article/details/50540661 Mysql中Timestamp字段的格式为yyyy-MM-dd HH-m ...
- Python学习day01 - 计算机基础
第一天 什么是编程 语言就是用来交流的. 语言+火构成了人类的文明 Python语言用来和计算机交流 通过他和计算机交流,然后完成很多程序员想要完成的事情,就叫编程. 为什么要编程 节省劳动力,更高效 ...
- MathType插件安装
1 安装包下载 版本号:7.4 下载 提取码:fxma 2 安装方法 用安装包内的Key激活即可.软件激活后不能升级. 注意:必须断网或者加入防火墙阻止联网使用! 3 可能遇到的问题 当安装完Math ...
- vue 实现单选框
参考:https://blog.csdn.net/qq_42221334/article/details/81630634 效果: vue: <template> <div> ...
- Django WSGI响应过程之WSGIHandler
class WSGIHandler(base.BaseHandler): request_class = WSGIRequest def __init__(self, *args, **kwargs) ...
- CSS样式汇总(转载)
1.字体属性:(font) 大小 {font-size: x-large;}(特大) xx-small;(极小) 一般中文用不到,只要用数值就可以,单位:PX.PD 样式 {font-style: o ...
- 架构hive2mysql流程
1.分析参数 args = new String[5]; args[0]="d:/3-20.sql"; args[1]="-date"; args[2]=&qu ...
- hdu1233还是畅通工程
还是畅通工程 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Sub ...
- 配置android studio环境2
安装android studio 2.1运行 exe 程序 安装截图 备注 :O(∩_∩)O~等了 ,但是还是失败, 完全安装啊,不影响,可以手动运行安装目录下的 如:D:\Program Files ...