【Spark-SQL学习之一】 SparkSQL
环境
虚拟机:VMware 10
Linux版本:CentOS-6.5-x86_64
客户端:Xshell4
FTP:Xftp4
jdk1.8
scala-2.10.4(依赖jdk1.8)
spark-1.6
一、Shark
Shark是基于Spark计算框架之上且兼容Hive语法的SQL执行引擎,由于底层的计算采用了Spark,性能比MapReduce的Hive普遍快2倍以上,当数据全部load在内存的话,将快10倍以上,因此Shark可以作为交互式查询应用服务来使用。除了基于Spark的特性外,Shark是完全兼容Hive的语法,表结构以及UDF函数等,已有的HiveSql可以直接进行迁移至Shark上Shark底层依赖于Hive的解析器,查询优化器,但正是由于SHark的整体设计架构对Hive的依赖性太强,难以支持其长远发展,比如不能和Spark的其他组件进行很好的集成,无法满足Spark的一栈式解决大数据处理的需求。
二、SparkSQL
1、SparkSQL介绍
Hive是Shark的前身,Shark是SparkSQL的前身。
(1)SparkSQL产生的根本原因是其完全脱离了Hive的限制。
(2)SparkSQL支持查询原生的RDD,RDD是Spark平台的核心概念,是Spark能够高效的处理大数据的各种场景的基础。
(3)能够在Scala中写SQL语句,支持简单的SQL语法检查,能够在Scala中写Hive语句访问Hive数据,并将结果取回作为RDD使用。
2、Spark on Hive和Hive on Spark
Spark on Hive: Hive只作为储存角色,Spark负责sql解析优化,执行。
Hive on Spark:Hive即作为存储又负责sql的解析优化,Spark负责执行。
3、DataFrame(SparkSQL的最佳搭档)
DataFrame也是一个分布式数据容器。
与RDD类似,然而DataFrame更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息,即schema。
同时与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。
从API易用性的角度上看, DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。
DataFrame的底层封装的是RDD,只不过RDD的泛型是Row类型。
4. SparkSQL的数据源
SparkSQL的数据源可以是JSON类型的字符串,也可以是JDBC,Parquent,Hive,HDFS等。

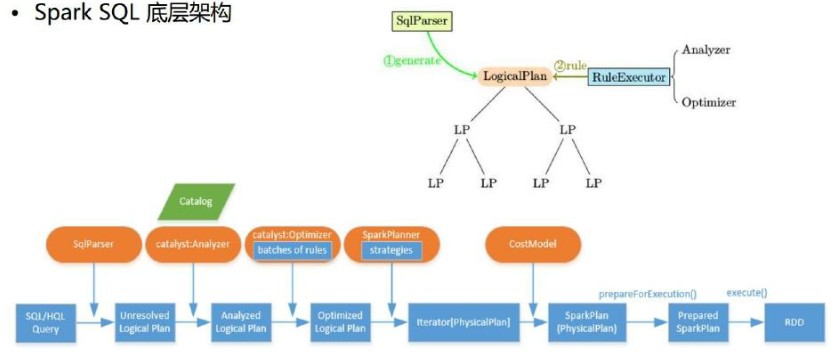
5. SparkSQL底层架构
首先拿到sql后解析一批未被解决的逻辑计划,
-->再经过分析得到分析后的逻辑计划,
-->再经过一批优化规则转换成一批最佳优化的逻辑计划,
-->再经过SparkPlanner的策略转化成一批物理计划,
-->随后经过消费模型转换成一个个的Spark任务执行。
6. 谓词下推(predicate Pushdown)

参考:
【Spark-SQL学习之一】 SparkSQL的更多相关文章
- spark SQL学习(综合案例-日志分析)
日志分析 scala> import org.apache.spark.sql.types._ scala> import org.apache.spark.sql.Row scala&g ...
- spark SQL学习(认识spark SQL)
spark SQL初步认识 spark SQL是spark的一个模块,主要用于进行结构化数据的处理.它提供的最核心的编程抽象就是DataFrame. DataFrame:它可以根据很多源进行构建,包括 ...
- spark SQL学习(案例-统计每日销售)
需求:统计每日销售额 package wujiadong_sparkSQL import org.apache.spark.sql.types._ import org.apache.spark.sq ...
- spark SQL学习(案例-统计每日uv)
需求:统计每日uv package wujiadong_sparkSQL import org.apache.spark.sql.{Row, SQLContext} import org.apache ...
- spark SQL学习(spark连接 mysql)
spark连接mysql(打jar包方式) package wujiadong_sparkSQL import java.util.Properties import org.apache.spark ...
- spark SQL学习(spark连接hive)
spark 读取hive中的数据 scala> import org.apache.spark.sql.hive.HiveContext import org.apache.spark.sql. ...
- spark SQL学习(数据源之json)
准备工作 数据文件students.json {"id":1, "name":"leo", "age":18} {&qu ...
- spark SQL学习(数据源之parquet)
Parquet是面向分析型业务得列式存储格式 编程方式加载数据 代码示例 package wujiadong_sparkSQL import org.apache.spark.sql.SQLConte ...
- spark SQL学习(load和save操作)
load操作:主要用于加载数据,创建出DataFrame save操作:主要用于将DataFrame中的数据保存到文件中 代码示例(默认为parquet数据源类型) package wujiadong ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
随机推荐
- 必读:Spark与kafka010整合
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/rlnLo2pNEfx9c/article/details/79648890 SparkStreami ...
- Android手机用wifi连接adb调试的方法
https://www.jianshu.com/p/dc6898380e38 0x0 前言 Android开发肯定要连接pc的adb进行调试,传统的方法是用usb与pc进行连接,操作简单即插即用,缺点 ...
- [pig] pig 基础使用
1.pig运行模式 本地模式: pig -x local 直接访问本地磁盘 集群模式: pig 或者 pig -x mapreduce 2.pig latin 交互 帮助信息 help 上传本地文件 ...
- Dart
Dart异步与阻塞 import 'dart:async'; import 'dart:io'; void main() async { for(int i = 0;i<10;i++) { as ...
- CXF整合Sping与Web容器
1.创建HelloWorld 接口类 package com.googlecode.garbagecan.cxfstudy.helloworld; import javax.jws.WebMethod ...
- CString数组和CStringArray
CStringArray是编译器定义的类型!可以进行一些(如:访问.增.删.改)等操作. 集中单个字符串的操作使用Cstring,集中一批字符串的管理使用CstringArray. 一个是动态,CSt ...
- Python学习之旅(十七)
Python基础知识(16):面向对象编程(Ⅰ) 类和实例 类是抽象的模板 实例是根据类创建出来的一个个具体的对象,每个对象都拥有相同的方法,但各自的数据可能不同. 类可以在创建实例的时候,把一些我们 ...
- 【MySQL】锁——查看当前数据库锁请求的三种方法 20
MySQL提供了查看当前数据库锁请求的三种方法:1. show full processlist命令 观察state和info列 2. show engine innodb status\G ...
- SQLSERVER CTE表 row_number()字段 BUG
当CTE中 引用的子视图的字段用了 row_number() over等那么有可能造成row_number() 的对应关系出错的问题 所以CTE row_number() over 排序字段 必须 ...
- stm8 iar开发
1.一份官方库基本是通用的. 2.尽量依托cubex for stm8 依托理由: 1.不同型号,不同后缀的芯片,将会被配置不同的外设.比如stm8s103k3系列可能有的是串口1,但是stm8s10 ...