Protobuf3 编解码
我们已经基本能够使用Protocol Buffers生成代码,编码,解析,输出及读入序列化数据。该篇主要讲述PB message的底层二进制格式。不了解该部分内容,并不影响我们在项目中使用Protocol Buffers,但是了解一下PB格式是如何做到smaller这一层,确实是很有必要的。Protobuf 序列化后所生成的二进制消息非常紧凑,这得益于 Protobuf 采用的非常巧妙的 Encoding 方法。
1.什么是 Varint
(1).Varint 是一种紧凑的表示数字的方法,它用一个或多个字节来表示一个数字,值越小的数字使用越少的字节数。这能减少用来表示数字的字节数。
比如对于 int32 类型的数字,一般需要 4 个 byte 来表示。但是采用 Varint,对于很小的 int32 类型的数字,则可以用 1 个 byte 来表示。当然凡事都有好的也有不好的一面,采用 Varint 表示法,大的数字则需要 5 个 byte 来表示。
(2).Varint 中的每个 byte 的最高位 bit 有特殊的含义,如果该位为 1,表示后续的 byte 也是该数字的一部分,如果该位为 0,则结束。其他的 7 个 bit 都用来表示数字。
因此小于 128 的数字都可以用一个 byte 表示。大于 128 的数字,比如 300,会用两个字节来表示:1010 1100 0000 0010
下图演示了 Protocol Buffer 如何解析两个 bytes。注意到最终计算前将两个 byte 的位置相互交换过一次,这是因为 Google Protocol Buffer 字节序采用 little-endian 的方式。
Varint 编码

消息经过序列化后会成为一个二进制数据流,该流中的数据为一系列的 Key-Value 对。如下图所示:
Message Buffer

采用这种 Key-Pair 结构无需使用分隔符来分割不同的 Field。对于可选的 Field,如果消息中不存在该 field,那么在最终的 Message Buffer 中就没有该 field,这些特性都有助于节约消息本身的大小。
二进制格式的message使用数字标签作为key,Key 用来标识具体的 field,在解包的时候,Protocol Buffer 根据 Key 就可以知道相应的 Value 应该对应于消息中的哪一个 field。
将 message编码后,key-values被编码成字节流存储。在message解码时,PB 解析器会跳过(忽略)不能够识别的字段,所以,message即使增加新的字段,也不会影响老程序代码,因为老程序代码根本就不能识别这些新添加的字段。
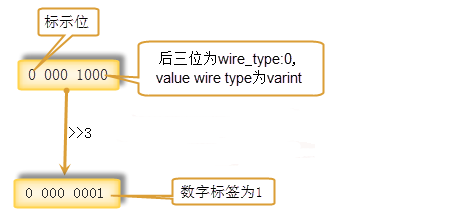
上边我们说,“二进制格式的message使用数字标签作为key”,此处的数字标签,并非单纯的数字标签,而是数字标签与传输类型的组合,根据传输类型能够确定出值的长度。
key的定义:
(field_number << 3) | wire_type
可以看到 Key 由两部分组成,第一部分是 field_number,第二部分为 wire_type。表示 Value 的传输类型,也就是说:key中的后三位,是值的wire_type类型。
Wire Type 类型如下表所示:
| Type | Meaning | Used For |
|---|---|---|
| 0 | Varint | int32, int64, uint32, uint64, sint32, sint64, bool, enum |
| 1 | 64-bit | fixed64, sfixed64, double |
| 2 | Length-delimi | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | Groups (deprecated) |
| 4 | End group | Groups (deprecated) |
| 5 | 32-bit | fixed32, sfixed32, float |
举个例子来分析protobuf数据编码和解码,如下所示:
message Test1 {
required int32 a = 1;
}
//.......protobuf读写操作..........
Test1 test;
test.set_a(150);
//.....将数据序列化到文件.....
写入message后,用UltraEdit打开,二进制格式查看,我们看到最终输出文件中包含三个数字:08 96 01(十六进制),这是如何得来的呢?
1.首先来解析tag
2.至此我们知道数字的field_number=1,值类型为varint。根据上面讲解来解码96 01,即为150:
96 01 = 1001 0110 0000 0001
→ 000 0001 ++ 001 0110 (drop the msb and reverse the groups of 7 bits)
→ 10010110
→ 2 + 4 + 16 + 128 = 150
注意:数值部分,低位在前,高位在后。
2.protobuf负数表示方式
在计算机内,一个负数一般会被表示为一个很大的整数,因为计算机定义负数的符号位为数字的最高位。如果采用 Varint 表示一个负数,那么一定需要 10 个 byte长度。为此 Google Protocol Buffer 定义了 sint32 这种类型,采用 zigzag 编码。将所有整数映射成无符号整数,然后再采用varint编码方式编码,这样绝对值小的整数,编码后也会有一个较小的varint编码值。
Zigzag 编码用无符号数来表示有符号数字,正数和负数交错,这就是 zigzag 这个词的含义了。

使用 zigzag 编码,绝对值小的数字,无论正负都可以采用较少的 byte 来表示,充分利用了 Varint 这种技术。
其他的数据类型,比如字符串等则采用类似数据库中的 varchar 的表示方法,即用一个 varint 表示长度,然后将其余部分紧跟在这个长度部分之后即可。
Zigzag映射函数为:
Zigzag(n) = (n << ) ^ (n >> ); //n为sint32时
Zigzag(n) = (n << ) ^ (n >> ); //n为sint64时
按照这种方法,-1将会被编码成1,1将会被编码成2,-2会被编码成3,如下表所示:
| Signed Original | Encoded As |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 3 |
| 2 | 4 |
| -3 | 5 |
| … | … |
| 2147483647 | 4294967294 |
| -2147483648 | 4294967295 |
3.Non-varint 数字
Non-varint数字比较简单,double 、fixed64 的Wire Type:1,在解析式告诉解析器,该类型的数据需要一个64位大小的数据块即可。同理,float和fixed32的Wire Type:5,给其32位数据块即可。两种情况下,都是高位在后,低位在前。
4.String类型
Wire Type:2的数据,是一种指定长度的编码方式:key+length+content,key的编码方式是统一的,length采用varints编码方式,content就是由length指定长度的Bytes。定义如下的message格式:
message Test2 {
required string b = ;
}
设置该值为"testing",二进制格式查看:12 07 74 65 73 74 69 6e 67
红色字节为“testing”的UTF8代码,此处,key是16进制表示的,所以展开是:12 -> 0001 0010,后三位010为wire type = 2,0001 0010右移三位为0000 0010,即tag=2。
length此处为7,后边跟着7个bytes,即我们的字符创"testing"。
字段顺序
简单来说只有两点:
编码/解码与字段顺序无关,这一点由key-value机制就能保证
对于未知的字段,编码的时候会把它写在序列化完的已知字段后面
Protobuf3 编解码的更多相关文章
- Netty学习(七)-Netty编解码技术以及ProtoBuf和Thrift的介绍
在前几节我们学习过处理粘包和拆包的问题,用到了Netty提供的几个解码器对不同情况的问题进行处理.功能很是强大.我们有没有去想这么强大的功能是如何实现的呢?背后又用到了什么技术?这一节我们就来处理这个 ...
- iOS8系统H264视频硬件编解码说明
公司项目原因,接触了一下视频流H264的编解码知识,之前项目使用的是FFMpeg多媒体库,利用CPU做视频的编码和解码,俗称为软编软解.该方法比较通用,但是占用CPU资源,编解码效率不高.一般系统都会 ...
- IOS和Android支持的音频编解码
1.IOS编码 参考文档地址:https://developer.apple.com/library/ios/documentation/AudioVideo/Conceptual/Multimedi ...
- java编解码技术,netty nio
对于java提供的对象输入输出流ObjectInputStream与ObjectOutputStream,可以直接把java对象作为可存储 的字节数组写入文件,也可以传输到网络上去.对与java开放人 ...
- 编解码-marshalling
JBoss的Marshalling序列化框架,它是JBoss内部使用的序列化框架,Netty提供了Marshalling编码和解码器,方便用户在Netty中使用Marshalling. JBoss M ...
- 编解码-protobuf
Google的Protobuf在业界非常流行,很多商业项目选择Protobuf作为编解码框架,Protobuf的优点. (1)在谷歌内部长期使用,产品成熟度高: (2)跨语言,支持多种语言,包括C++ ...
- 编解码-java序列化
大多数Java程序员接触到的第一种序列化或者编解码技术就是Java的默认序列化,只需要序列化的POJO对象实现java.io.Serializable接口,根据实际情况生成序列ID,这个类就能够通过j ...
- ilbc编解码
针对国内的博客或者技术论坛对 ILBC的论述都是把文章抄来抄去, 本人在此对 ILBC的具体代码实现详细列出代码. ILBC是由Global IP Sound公司提出的一种专为包交换网络通信设计的编解 ...
- 各种音视频编解码学习详解 h264 ,mpeg4 ,aac 等所有音视频格式
编解码学习笔记(一):基本概念 媒体业务是网络的主要业务之间.尤其移动互联网业务的兴起,在运营商和应用开发商中,媒体业务份量极重,其中媒体的编解码服务涉及需求分析.应用开发.释放 license收费等 ...
随机推荐
- 一: WCF的服务端与客户端在通信时有三种模式:请求响应模式、数据报模式和双工通讯模式。
说一下基本知识, 1.如果想要将当前接口作为wcf服务器,则一定要加上[ServiceContract] 契约 2.要想将方法作为wcf服务方法发布给外部调用,则一定要加上 [Operatio ...
- Alpha(2/10)
鐵鍋燉腯鱻 项目:小鱼记账 团队成员 项目燃尽图 冲刺情况描述 站立式会议照片 各成员情况 团队成员 学号 姓名 git地址 博客地址 031602240 许郁杨 (组长) https://githu ...
- 1038. Jewels And Stones
描述 给定字符串J代表是珠宝的石头类型,而S代表你拥有的石头.S中的每个字符都是你拥有的一个石头. 你想知道你的石头有多少是珠宝. J中的字母一定不同,J和S中的字符都是字母. 字母区分大小写,因此& ...
- 2108 ACM 向量积 凹凸
题目:http://acm.hdu.edu.cn/showproblem.php?pid=2108 图一中,向量a × 向量 b 根据右手定则,得出向量c的方向.即为凸多边形. 图二中,若向量a ...
- 搭建WordPress 个人博客
1,准备 LAMP 环境 LAMP 是 Linux.Apache.MySQL 和 PHP 的缩写,是 Wordpress 系统依赖的基础运行环境.我们先来准备 LAMP 环境: (由于部分服务安装过程 ...
- [BZOJ4259]残缺的字符串
Description: 给定两个带通配符的串,求可能出现几次匹配,以及这些匹配位置 Hint: \(n \le 3*10^5\) Solution: 定义匹配函数 \(P(x)=\sum_{i=x} ...
- HTTP断点续传
一.概述 所谓断点续传,其实只是指下载,也就是要从文件已经下载的地方开始继续下载.在以前版本的HTTP协议是不支持断点的,HTTP/1.1开始就支持了.一般断点下载时才用到Range和Conten ...
- poj3009 Curling 2.0(很好的题 DFS)
https://vjudge.net/problem/POJ-3009 做完这道题,感觉自己对dfs的理解应该又深刻了. 1.一般来说最小步数都用bfs求,但是这题因为状态记录很麻烦,所以可以用dfs ...
- xinetd服务
xinetd(eXtended InterNET services daemon) 一.xinetd的功能介绍: xinetd提供类似于inetd+tcp_wrapper的功能,但是更加强大和安全.它 ...
- AssemblyInfo.cs文件详解
版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/qq395537505/article/details/49661555 一.前言 .net工程的Pr ...