python 离散序列 样本数伸缩(原创)
解决问题:
有一个固定长度的1维矩阵,将这个矩阵的取样点进行扩充和减少
功能函数:
def discrete_scale(data, num):
import numpy as np
import copy
"""
:param data: 原始一维矩阵数据
:param num: 设定的样本长度
:return d1: 目标矩阵输出
"""
len = data.shape[0] # 原始数据长度 if len < num: # 样本扩展
t = (len - 1) / (num - 1) # 映射差值
d0 = np.array(range(num)) # 序列映射
d0 = d0 * t d0_1 = copy.deepcopy(d0).astype(int) # 整数部分
d0_0 = d0 - d0_1 # 小数部分
dist = data[1:] - data[:-1] # 维度减小一个数据
d1_1 = data[d0_1]
d1_0 = dist[d0_1[:-1]]
d1_0 = d1_0 * d0_0[:-1]
d1 = copy.deepcopy(d1_1[:-1] + d1_0)
d1 = np.hstack((d1, data[-1])) elif len > num: # 样本压缩
t = (len - 1) / num # 映射差值 分成7个给值区域
d0 = np.array(range(num + 1)) # 序列映射
d0 = d0 * t d0_1 = copy.deepcopy(d0).astype(int) # 整数部分
list = []
for i in range(d0_1.shape[0] - 1):
list.append(np.mean(data[d0_1[i]:d0_1[i + 1] + 1]))
d1 = np.array(list) else: # 目标长度与原始长度相同
d1 = data
return d1
实例程序:
import numpy as np
a = np.array(range(0,1000))
print(a)
b = np.sin(a/100)
print(b) num = 100
x1 = np.array(range(num))
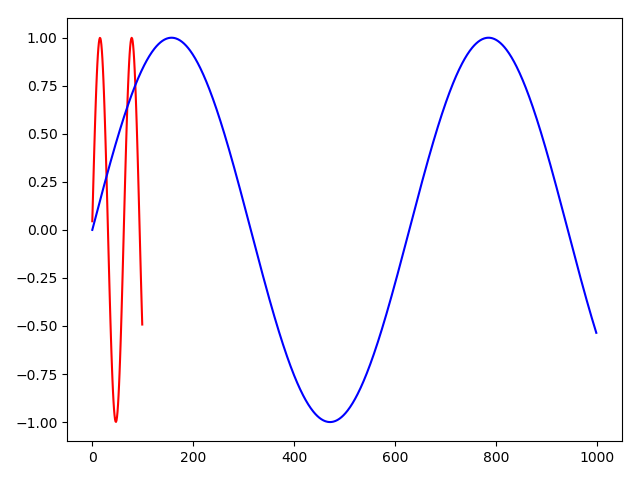
y1 = discrete_scale(b, num) import matplotlib.pylab as plt
plt.plot(x1, y1, 'r-')
plt.plot(a, b, 'b-')
plt.show()
print(b)
python 离散序列 样本数伸缩(原创)的更多相关文章
- 第二天:python的函 数、循环和条件、类
https://uqer.io/community/share/54c8af17f9f06c276f651a54 第一天学习了Python的基本操作,以及几种主要的容器类型,今天学习python的函数 ...
- 关于VisualStudio性能分析数据中的独占样本数和非独占样本数的意义
VisualStudio中自带有Profile工具进行性能性能分析,其中用得比较多的数据是函数调用时间,它主要有独占样本数和非独占样本数两个指标,关于这两个指标代表的意义,MSDN的解释比较文艺: 非 ...
- Python学习day15-函数进阶(3)
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- Python学习day14-函数进阶(2)
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- Python学习day13-函数进阶(1)
Python学习day13-函数进阶(1) 闭包函数 闭包函数,从名字理解,闭即是关闭,也就是说把一个函数整个包起来.正规点说就是指函数内部的函数对外部作用域而非全局作用域的引用. 为函数传参的方式有 ...
- Python学习day12-函数基础(2)
<!doctype html>day12博客 figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { pos ...
- Python学习day11-函数基础(1)
figure:last-child { margin-bottom: 0.5rem; } #write ol, #write ul { position: relative; } img { max- ...
- python 特定份数的数据概率统计(原创)
使用numpy模块中的histogram函数模块 Histogram(a,bins=10,range=None,normed=False,weights=None)其中, a是保存待统计数据的数组, ...
- Python 文件行数读取的三种方法
Python三种文件行数读取的方法: #文件比较小 count = len(open(r"d:\lines_test.txt",'rU').readlines()) print c ...
随机推荐
- Java虚拟机 内存区域划分
(图片来自https://www.cnblogs.com/whgk/p/6138522.html) 先从线程私有区开始介绍 虚拟机栈 Java虚拟机栈是由一个个栈帧组成的,当一个方法被调用时,代表这个 ...
- jasperreport queryString in
and $X{IN, 字段, 参数} and $X{IN, field1, param1} 其中param1设为List类型
- Android 面试问答
Android 面试问答 目录 数据结构和算法 java核心知识 Android核心知识 架构 设计相关问题 相关工具和技术 Android 测试驱动开发 其他 数据结构和算法 ******关于此类问 ...
- 每10秒执行定时任务-crontab
* * * * * /data/crontab.sh * * * * * sleep 10; /data/crontab.sh * * * * * sleep 20; /data/crontab.sh ...
- (转)经验分享:CSS浮动(float,clear)通俗讲解
文章转自:https://www.cnblogs.com/iyangyuan/archive/2013/03/27/2983813.html 很早以前就接触过CSS,但对于浮动始终非常迷惑,可能是自身 ...
- 巧克力分配问题——C语言
某品牌巧克力使用500克原料可制作55小块巧克力,请编程实现:输入原料重量(以千克为单位),计算出制作巧克力的块数(四舍五入).然后对这些巧克力进行分包,小盒放11块,大盒放24块,问各分装多少大盒多 ...
- jexus托管.net core
https://blog.csdn.net/gongzhe2011/article/details/72757863
- python 的面相对象编程--对应c++
在python的面相对象编程中,我们常常在class中可以看到a(), _b() , __c(), __d()__这样的函数. 由于我是看廖雪峰老师的教程,廖老师为了简单起见,没有引入太多概念,我 ...
- 《C#从现象到本质》读书笔记(五)第5章字符串第6章垃圾回收第7章异常与异常处理
<C#从现象到本质>读书笔记(五)第5章字符串 字符串是引用类型,但如果在某方法中,将字符串传入另一方法,在另一方法内部修改,执行完之后,字符串的只并不会改变,而引用类型无论是按值传递还是 ...
- 通过JDBC进行简单的增删改查(以MySQL为例) 目录
通过JDBC进行简单的增删改查(以MySQL为例) 目录 前言:什么是JDBC 一.准备工作(一):MySQL安装配置和基础学习 二.准备工作(二):下载数据库对应的jar包并导入 三.JDBC基本操 ...