Spark升级--在CDH-5.15.1中添加spark2
一、环境准备
jdk-1.8+scala-2.11.X+python-2.7
二、创建目录
mkdir -p /opt/cloudera/csd
修改权限
chown cloudera-scm:cloudera-scm /opt/cloudera/csd
获取csd(放到/opt/cloudera/csd目录)
wget http://archive.cloudera.com/spark2/csd/SPARK2_ON_YARN-2.1.0.cloudera2.jar
修改组权限和用户权限
chgrp cloudera-scm SPARK2_ON_YARN-2.1.0.cloudera2.jar
chown cloudera-scm SPARK2_ON_YARN-2.1.0.cloudera2.jar
三、添加parcels

注意:
(1)2.1.0.cloudera2 和2.1.0.cloudera1的区别
(详见表格:https://www.cloudera.com/documentation/spark2/latest/topics/spark2_requirements.html)
(2)jar版本要和此处的2.1.0.cloudera2或者2.1.0.cloudera1版本一致
url----->http://archive.cloudera.com/spark2/parcels/2.1.0.cloudera2/
等待下载结束
四、激活spark2
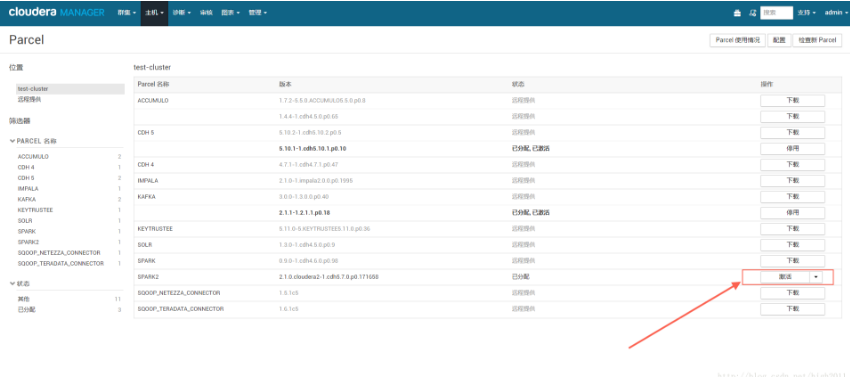
五、重启群集和cloudera-scm-server
(1)先重启cdh集群
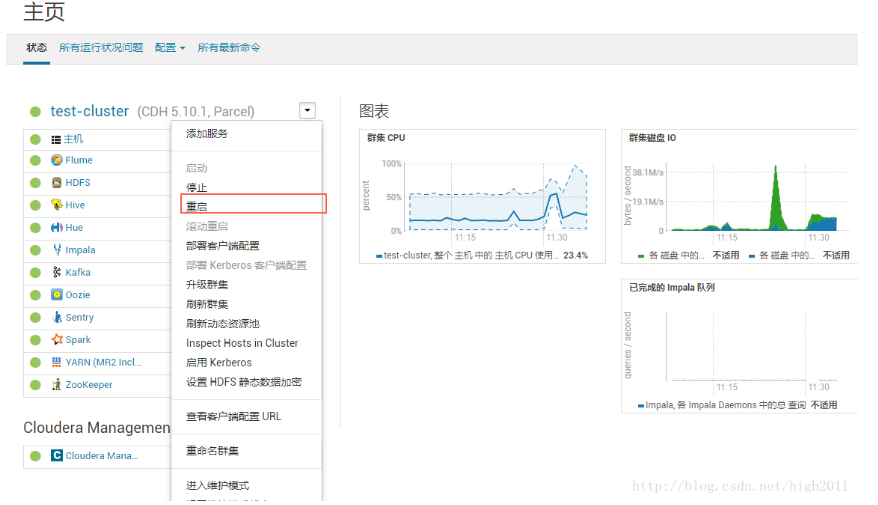
(2)再重启cloudera-scm-server
#/opt/cloudera-manager/cm-5.15.1/etc/init.d/cloudera-scm-server restart
#tail -f/opt/cloudera-manager/cm-5.15.1/log/cloudera-scm-server/cloudera-scm-server.log
#tail -f/opt/cloudera-manager/cm-5.15.1/log/cloudera-scm-agent/cloudera-scm-agent.log
六、添加spark2的服务
(1)点击添加服务

(2)选择spark2

(3)选择依赖最多的
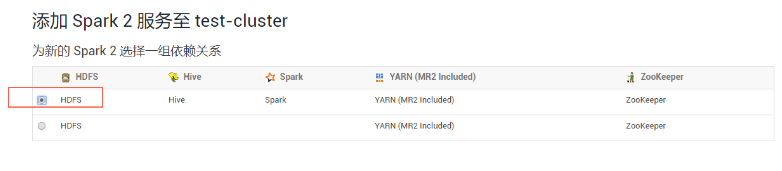
(4)选择history spark2
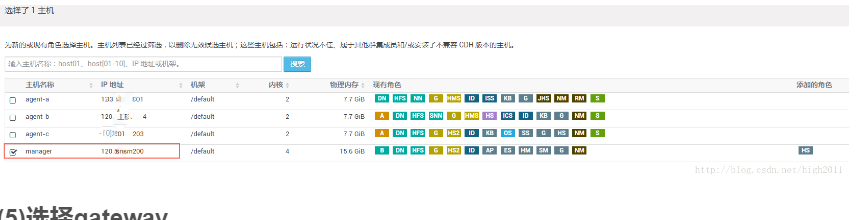
(5)选择gateway

(6)等待执行成功

(7)成功后的界面
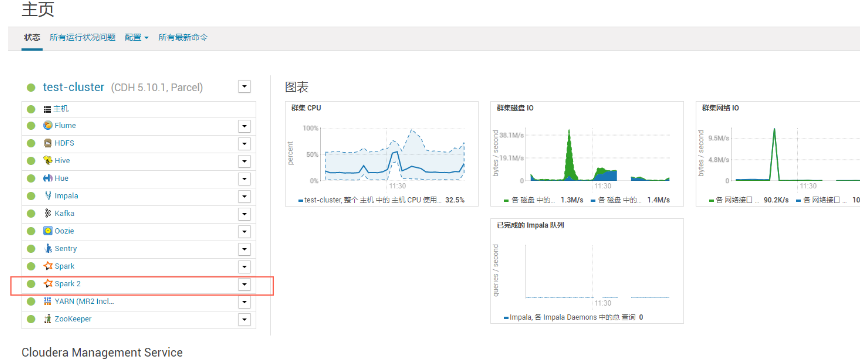
七、测试spark2
(1)在命令行输入
spark-shell --conf spark.executor.memory=2g --confspark.executor.cores=2
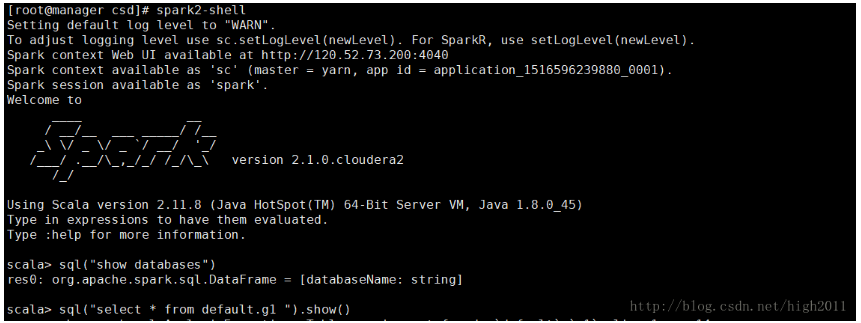
(2)参考举例
https://spark.apache.org/docs/2.1.0/quick-start.html
Spark升级--在CDH-5.15.1中添加spark2的更多相关文章
- cdh5.15集群添加spark2.3服务(parcels安装)
背景: 机器系统:redhat7.3:已经配置了http服务 集群在安装的时候没有启动spark服务,因为cdh5.15自带的spark不是2.0,所以直接进行spark2.3的安装 参考文档:htt ...
- Cloudera Manager Server CDH 5.15部署
安装前准备 主机和系统 Host OS Memory IP bigdata001-dev Cent OS 7.4 x64 32G 192.168.1.1 bigdata002-dev Cent OS ...
- CentOS7安装CDH 第十章:CDH中安装Spark2
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- 在 Ubuntu 15.04 中使用 ubuntu-make、Eclipse 4.4、Java 8 以及 WTP
Ubuntu 今天发布新版本了 其实昨天(2015-04-23)我就看到了 Ubuntu 发布新版本的新闻,下班后回家的第一件事就是访问 Ubuntu 的官网,很可惜,没有提供下载.今天(2015-0 ...
- 15.Mysql中的安全问题
15.SQL中的安全问题15.1 SQL注入简介SQL是用来和数据库交互的文本语言.SQL注入(SQL Injection)是利用数据库的外部接口将用户数据插入到实际的SQL中,以达到入侵数据库乃至操 ...
- CDH 5.15.2 离线安装
一.前置准备 1. 基础信息 1.1 机器 机器名 服务 hadoop1 主节点 hadoop2 data.task hadoop3 data.task 1.2 服务版本 服务 版本 cdh 5.15 ...
- 使用ansible部署CDH 5.15.1大数据集群
使用ansible离线部署CDH 5.15.1大数据集群 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在此之前,我之前分享过使用shell自定义脚本部署大数据集群,不管是部署CD ...
- Fedora 15 KDE中如何打开software management及如何应用
Fedora 15 KDE中如何打开software management级如何应用 software management中有转载和卸载软件(Get and remove software)的功能 ...
- Struts升级到2.3.15.1抵抗漏洞
后知后觉,今天才开始修复Struts2的漏洞 详细情形可以参考: http://struts.apache.org/release/2.3.x/docs/security-bulletins.html ...
随机推荐
- linux samba smb 在客户端无法连接使用
netstat -nutlp查看是否启动进程 1.网络是否正常,是否可以ping通.2.Windows和Linux的防火墙全部关闭.3.samba的端口是否开启,tcp/139.tcp/445.udp ...
- day02python入门
今日概要 解释器环境安装 输出 python试执行 数据类型 变量 输入 注释 条件判断 循环 占位符 数据类型转换 1. 环境的安装 python解释器 py2: Python2.7 (老版本) . ...
- kali 2018.2版本运行破解版burpsuite时候的问题。
最近重装了kali虚拟机,装完之后把burp拷到里面发现运行不了了,折腾了下才解决,问题主要是由于java环境造成的. 系统默认是以java10运行burp的,但是java10好像是不支持 -X ...
- jar包不能乱放【浪费了下午很多时间】
不能放在类路径下(也即是src文件夹下),然后再buildpath 必须放在web-inf文件夹下 这样才能tomcat找打jar文件
- 笔记本使用control线连接交换机
要求: 1.一台笔记本 2.一条usb转rj45串口线 (一端是usb口一端是网口) 连接步骤: usb口插入笔记本,网口插入交换机控制口(交换机上面一般会有标注) 直连步骤: 首先查看是哪个com口 ...
- Day 09 函数基础
函数初级 简介 # 函数是一系列代码的集合,用来完成某项特定的功能 优点 '''1. 避免代码的冗余2. 让程序代码结构更加清晰3. 让代码具有复用性,便于维护''' 函数四部分 '''1. 函数名: ...
- DSP2812 启动详解
百度文库转载 1. 从0X3F FFC0处复位→执行0X3F FC00地址处的初始化引导函数(Initboot) →根据GPIO选择引导模式→确定用户程序入口地址→从入口处开始执行用户程序. 输入外部 ...
- debian下arp欺骗
sudo sysctl -w net.ipv4.ip_forward= sudo sysctl -p arpspoof -i eth0 -t 目标ip -r 伪装ip或者ettercap -i eth ...
- C# 自定义类动态追加属性
利用Dynamic,需要.net4.0以上的支持 var dg = rel.ResultDocuments.FirstOrDefault()["dg"].AsBsonArray.G ...
- ss客户端以及tcp,udp,dns代理ss-tproxy在线安装版--centos7.3 x64以上(7.3-7.6x64测试通过)
#!/bin/sh # # Script for automatic setup of an SS-TPROXY server on CentOS 7.3 Minimal. # export PATH ...