hbase1.2.6完全分布式安装
环境,参考之前的两篇博文:
jdk1.7
hadoop2.6.0 完全分布式
一个master,slave1,slave2,slave3
zookeeper3.4.6 完全分布式
安装与配置:(以下步骤都在master上操作,配置好了之后发送到其他的slave上并稍作环境变量配置即可)
到官网去下载hbase1.2.6的安装包,然后解压到/usr/local/目录下,然后用mv命令重命名为hbase
环境变量配置:
/etc/profile

进入hbase的conf目录下,这里边存放的是配置文件,下面做配置:
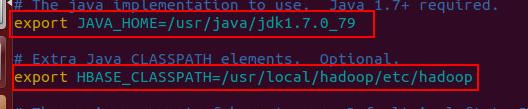
修改hbase-env.sh文件,找到如下几行,并且改成如图这样:


修改hbase-site.xml文件
<property>
<name>hbase.rootdir</name>
<value>hdfs://master:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/usr/local/zookeeper</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/usr/local/hbase/tmp</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>master,slave1,slave2,slave3</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
修改regionservers,将文件内容设置为:
master
slave1
slave2
slave3
然后通过scp -r /usr/local/hbase hadoop@slave1:/usr/local/发送到slave1上,slave2、slave3的发送都一样,然后分别在slave上做环境变量配置。
这样就完成了,如果想检测的话,得先启动hadoop的dfs,然后再启动hbase,执行hbase shell命令就能进入hbase数据库了。
hbase1.0以后的webUI访问端口为16010(之前的为60010)
hbase1.2.6完全分布式安装的更多相关文章
- hbase1.2.4 伪分布式安装
注意:在安装hbase或者hadoop的时候,要注意hadoop和hbase的对应关系.如果版本不对应可能造成系统的不稳定和一些其他的问题.在hbase的lib目录下可以看到hadoop对应jar文件 ...
- Hadoop2.7.3+Hbase-1.2.6完全分布式安装部署
因为学习,在网上找了很多hbase搭建的文章,感觉这篇很好,点此 搭建好后,jps查看了后台进程,发现在slave上面没有HRegionServer进程 便查看了 slave上关于HRegionSer ...
- HBase伪分布式安装(HDFS)+ZooKeeper安装+HBase数据操作+HBase架构体系
HBase1.2.2伪分布式安装(HDFS)+ZooKeeper-3.4.8安装配置+HBase表和数据操作+HBase的架构体系+单例安装,记录了在Ubuntu下对HBase1.2.2的实践操作,H ...
- hadoop2.6完全分布式安装HBase1.1
本文出自:http://wuyudong.com/archives/119 对于全分布式的HBase安装,需要通过hbase-site.xml文档来配置本机的HBase特性,由于各个HBase之间通过 ...
- Hadoop2.7.5+Hbase1.4.0完全分布式
Hadoop2.7.5+Hbase1.4.0完全分布式一.在介绍完全分布式之前先给初学者推荐两本书:<Hbase权威指南>偏理论<Hbase实战>实战多一些 二.在安装完全分布 ...
- mysql 和 hive 和分布式zookeeper和HBASE分布式安装教程
一,mysql 安装mysql5.7完整教程1. yum -y install mysql-server直接执行语句后等待就好已安装: mysql-community-server.x86_64 0: ...
- Opentsdb分布式安装
Opentsdb分布式安装 --李琦 1.下载文件上传到虚拟机 -rw-r--r--. 1 root root 76793860 Apr 27 10:56 opentsdb-2.2.0.tar ...
- Hadoop生态圈-hbase介绍-伪分布式安装
Hadoop生态圈-hbase介绍-伪分布式安装 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HBase简介 HBase是一个分布式的,持久的,强一致性的存储系统,具有近似最 ...
- 大数据hbase分布式安装及其部署。
大数据hbase分布式安装及其部署. 首先要启动Hadoop以及zookeeper,可以参考前面发布的文章. 将hbase的包上传至master节点 这里我使用的是1.3.6的版本,具体的根据自己的版 ...
随机推荐
- display:flex 布局之 骰子
代码部分 html <body> <div class="box"> <div class="a a1"> <span ...
- zabbix service安装配置
1.安装时间同步 yum -y install ntpdate systemctl start ntpdate.service systemctl enable ntpdate.service 2.安 ...
- linux 2.6升级Python2.7 ./configure 报错问题
升级2.7.3使用命令./configure --prefix=/usr/local/python2.7.3时,出现以下错误:checking build system type... x86_64- ...
- Spring+SpringMVC+Mybatis(二)
上一次讲的是利用mybatis提供的sqlSessionTemplate作为DAO进行数据库的操作,其实我们可以把它封装到我们自己的DAO里面,这样就是所谓的自己写DAO,这次我们写一下通过mybat ...
- jquery图片滚动jquery.scrlooAnimation.js
;(function ($, window, document, undefined) { var pluginName = "scrollAnimations", /** * T ...
- vue-cli中vuex IE兼容
vue2.0 兼容ie9及其以上 vue-cli中使用vuex的项目 在IE中会出现页面空白 控制台报错的情况:我们只需要安装一个插件,然后在main.js中全局引入即可 安装 npm install ...
- python 中的UDP和TCP(1)
一.TCP: TCP是Transmission Control Protocol的简称,中文名传输控制协议.是一种面向连接的.可靠的.基于字节流的传输层通信协议.TCP通信需要经过创建连接.数据传输. ...
- C# Regex正则验证规则
using System; using System.Text.RegularExpressions; namespace MetarCommonSupport { /// <summary&g ...
- Linux中程序的编译和链接过程
1.从源码到可执行程序的步骤:预编译.编译.链接.strip 预编译:预编译器执行.譬如C中的宏定义就是由预编译器处理,注释等也是由预编译器处理的. 编译: 编译器来执行.把源码.c .S编程机器码. ...
- Java——英文字母---18.10.11
package lianxi;import java.io.*;import java.util.Scanner;public class file{ public static void main ...