基于Ubuntu16搭建Hadoop大数据完全分布式环境
【目的】:学习大数据
在此记录搭建大数据的过程。
【系统环境】
宿主机操作系统:Win7 64位
虚拟机软件:Vmware workstation 12
虚拟机:Ubuntu 16 64位桌面版
【步骤概要】
一、准备
1、准备安装软件
2、规划好虚拟机数量、机器名称、IP
3、设置虚拟机静态IP
4、建立专用于hadoop的账号
二、设置免密登录
实现这几台测试机之间可以免密码登录
三、安装和配置Java环境
四、安装和配置Hadoop
五、测试和收尾
【搭建过程】
一、准备
1、安装文件准备
Hadoop软件:
JDK:
Ubuntu 16的安装软件
2、虚拟机准备
测试计划使用三台虚拟机
在Win7里启动Vmware workstation,安装一台操作系统为Ubuntu 16的空的虚拟机,从这台虚拟机另外再克隆出来两台
3、机器名称:hadoop.master、hadoop.slave1、hadoop.slave2
通过修改/etc/hostname来设置虚拟机的主机名称
#vi /etc/hostname

4、查看和确定网关,我这测试环境的网关是:192.168.152.2
查看方式:
1)、点击Vmware workstation左上角的“编辑”
2)、选择“虚拟网络编辑器”
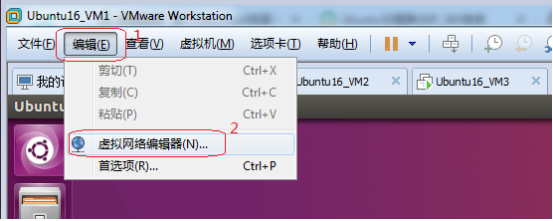
3)、选择NAT模式

4)、上图中“使用本地DHCP服务将IP地址分配给虚拟机”,很多网上文档都是把此项前面的“√"去掉,如果所有的虚拟机都设置为静态IP,可以去掉,因为我还有别的虚拟机,不在意是否静态IP,所以,此项“√”保留。
5)、“NAT设置”按钮,可看到网关设置,我虚拟机的网关为:192.168.152.2
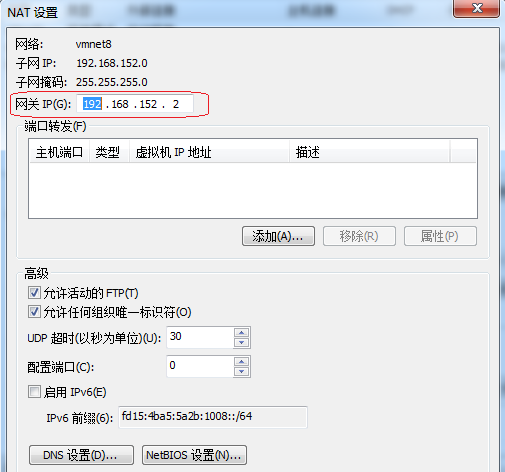
这是系统默认的,在此无需变更。
5、规划三台虚拟机的IP:192.168.152.21、192,168.152.22、192.168.152.23
IP地址选择,前面三节都是:192.168.152,后面是除了网关里占用了2,其它1~255之间的数即可。如果已经设定了其它静态IP,不和那些冲突即可。
6、修改/etc/hosts,修改hosts文件目的是为了这三台虚拟机可以通过机器名称互相访问

上图是第一台hadoop.master的,另两台,修改127.0.0.1 hadoop.XXXXX 修改为相应的机器名称
7、为虚拟机设置静态IP
只所以设置为静态IP,是因为虚拟机启动后,有时会自动变更IP,而在搭建的大数据环境里,会配置IP地址,动态变化后,会出现IP地址不匹配。
#sudo vi /etc/network/interfaces

我的文件打开后,里面有如下内容:
auto lo
iface lo inet loopback
这些内容不变,增加下面内容
auto ens33
iface ens33 inet static
address 192.168.152.21
netmask 255.255.255.0
gateway 192.168.152.2
dns-nameservers 202.96.209.5
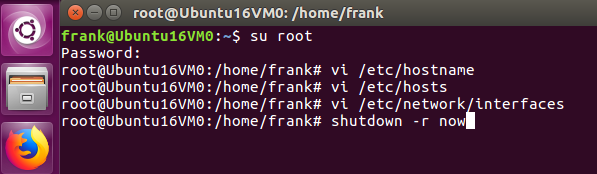
保存后退出,重启电脑,使用ifconfig检查新设置的IP地址是否已经生效。
使用Ping命令检查是否能ping通
1)、内网是否能ping通其它机器,比如,在hadoop.master里ping 192.168.152.22
2)、 Ping外网,比如:ping www.baidu.com
测试如下:

说明:
1、如果编辑/etc/network/interfaces,里面没有配置dns,则可以ping通内网的其它机器,无法ping通外网的机器
2、注意软件版本,如果虚拟机不是Ubuntu16,而是Ubuntu14或Ubuntu18,那么配置静态IP,可能需要编辑不同的文件,就不是/etc/network/interfaces了
如果虚拟机是CentOS ,更不是/etc/network/interfaces,但道理是通的,搭建Hadoop完全分布式大数据环境,利用虚拟机来实现,需要配置静态IP,避免机 器重启后配置失效。
3、如果设定有问题,则查找原因,解决后再往后继续。
8、增加user,这个用户专用于操作hadoop
1)、切换到root账号
2)、这里用户名设为:hadoop
#useradd hadoop
3)、为增加的账号设置口令
#passwd hadoop
4)、去home文件夹下检查
#cd /home
#ll
在home文件夹下发现没有新增hadoop文件夹
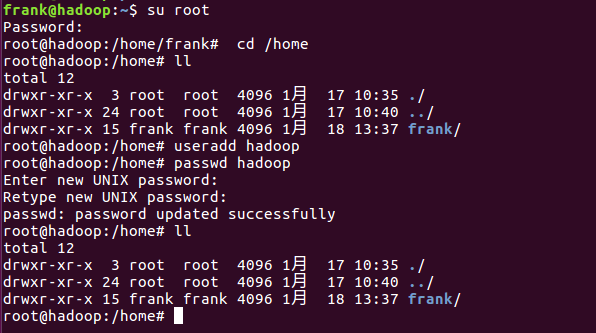
5)、删除已建立的user hadoop,换种方式重新建立
a.删除原hadoop账号
#userdel hadoop
b.查看,在home文件夹下没有hadoop的账号信息
#ll
c.按下述命令增加hadoop账号,使用参数
#useradd -r -m -s /bin/bash hadoop
d.再查看home文件夹,正常情况下,在home文件夹下会出现hadoop文件夹
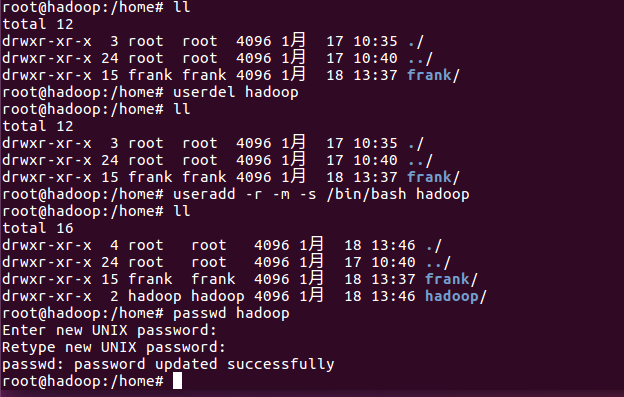
6)、参照步骤5)在另外两台机器上建立hadoop账号,并设置hadoop的口令,这三台机器的口令要一致。
#useradd -r -m -s /bin/bash hadoop
#passwd hadoop
9、把新增的这个用户设为管理员,编辑/etc/sudoers
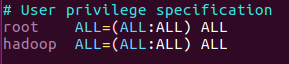
注意:Tab键的使用
二、设置免密登录
1、#cd ~/.ssh
提示无此目录
2、安装,sudo apt-get install openssh-server

按提示输入y,回车
3、安装好以后,输入cd ~/.ssh,仍然提示没有这个文件夹
4、执行ssh localhost
执行ssh localhost命令后,就会建立一个~/.ssh的隐藏的文件夹
5、输入exit 退出

6、进入~/.ssh
#cd ~/.ssh
7、如果先前有公钥,则先删除
#rm ./id_rsa*
8、生成公钥
#ssh-keygen -t rsa
一路按回车即可
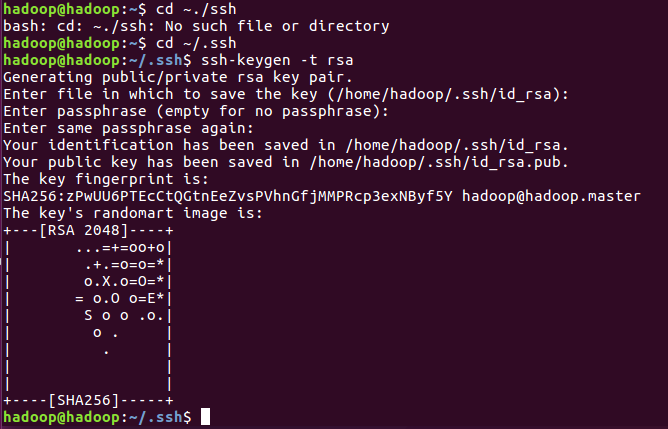
9、让主节点能够免密登录到主节点
1)、把公钥添加到key中
# cat ./id_rsa.pub >> ./authorized_keys
2)、第一次使用ssh登录主节点本机
#ssh hadoop.master
3)、输入exit退出
#exit
4)、第二次使用ssh登录主节点本机
#ssh hadoop.master
5)、输入exit退出
#exit
10、把主节点的公钥传到从节点,也就是另外两台机器行,实现从主节点免密登录到从节点
1)、分别到两台从节点机器上hadoop.slave1和hadoopslave2上,切换到hadoop账号,检查有无~/.ssh文件夹
#su hadoop
#cd ~/.ssh
如果没有,则建立
#mkdir ~/.ssh
检查
#cd ~/.ssh
2)、切换到hadoop账号下
#su hadoop
3)、进入~/.ssh
#cd ~/.ssh
4)、查看
#ll
5)、拷贝传输
#scp id_rsa.pub >> hadoop@hadoop.slave1:/home/hadoop/
#scp id_rsa.pub >> hadoop@hadoop.slave2:/home/hadoop/

6)、从上图看,公钥传输被拒绝掉了,解决办法:
分别在hadoop.slave1和hadoop.slave2上执行下面语句:
#sudo apt-get install openssh-server
7)、回到主节点,重新拷贝传输公钥
#su hadoop
#cd /home/hadoop
#cd .ssh
#scp id_rsa.pub >> hadoop@hadoop.slave1:/home/hadoop/
#scp id_rsa.pub >> hadoop@hadoop.slave2:/home/hadoop/
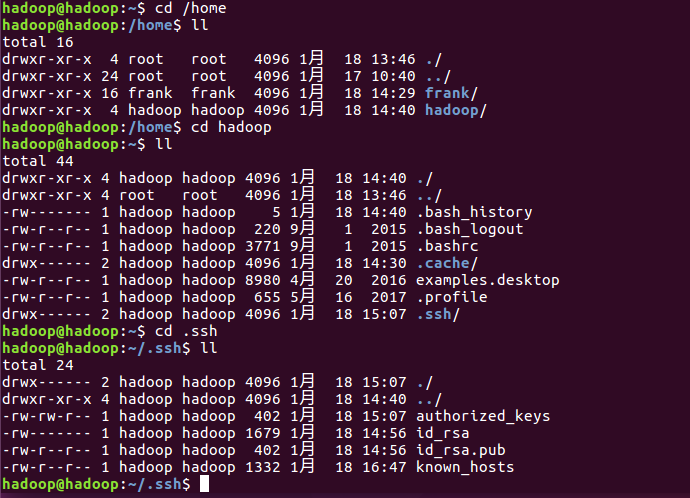
8)、再分别到两台从节点,把id_rsa.pub加到authorized_Keys里
#su hadoop
#cd /home/hadoop
#cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
9)、从主节点,以hadoop登录,检查是否能免密登录hadoop.slave1和hadoop.slave2
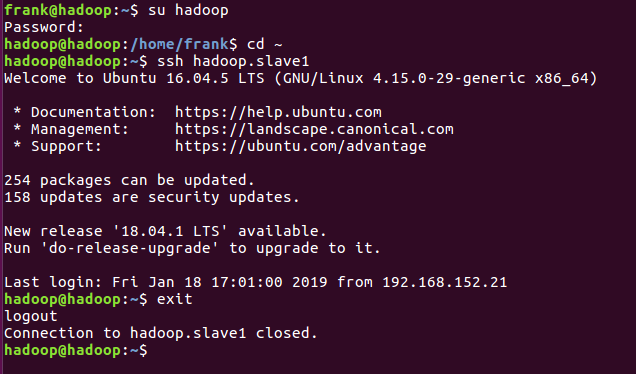
三、安装和配置Java环境
四、安装和配置Hadoop
基于Ubuntu16搭建Hadoop大数据完全分布式环境的更多相关文章
- 【HADOOP】| 环境搭建:从零开始搭建hadoop大数据平台(单机/伪分布式)-下
因篇幅过长,故分为两节,上节主要说明hadoop运行环境和必须的基础软件,包括VMware虚拟机软件的说明安装.Xmanager5管理软件以及CentOS操作系统的安装和基本网络配置.具体请参看: [ ...
- 如何基于Go搭建一个大数据平台
如何基于Go搭建一个大数据平台 - Go中国 - CSDN博客 https://blog.csdn.net/ra681t58cjxsgckj31/article/details/78333775 01 ...
- 单机,伪分布式,完全分布式-----搭建Hadoop大数据平台
Hadoop大数据——随着计算机技术的发展,互联网的普及,信息的积累已经到了一个非常庞大的地步,信息的增长也在不断的加快.信息更是爆炸性增长,收集,检索,统计这些信息越发困难,必须使用新的技术来解决这 ...
- hadoop大数据技术架构详解
大数据的时代已经来了,信息的爆炸式增长使得越来越多的行业面临这大量数据需要存储和分析的挑战.Hadoop作为一个开源的分布式并行处理平台,以其高拓展.高效率.高可靠等优点越来越受到欢迎.这同时也带动了 ...
- 《Hadoop大数据架构与实践》学习笔记
学习慕课网的视频:Hadoop大数据平台架构与实践--基础篇http://www.imooc.com/learn/391 一.第一章 #,Hadoop的两大核心: #,HDFS,分布式文件系统 ...
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- 大数据hbase分布式安装及其部署。
大数据hbase分布式安装及其部署. 首先要启动Hadoop以及zookeeper,可以参考前面发布的文章. 将hbase的包上传至master节点 这里我使用的是1.3.6的版本,具体的根据自己的版 ...
- 基于Docker搭建Hadoop+Hive
为配合生产hadoop使用,在本地搭建测试环境,使用docker环境实现(主要是省事~),拉取阿里云已有hadoop镜像基础上,安装hive组件,参考下面两个专栏文章: 克里斯:基于 Docker 构 ...
- 0基础搭建Hadoop大数据处理-编程
Hadoop的编程可以是在Linux环境或Winows环境中,在此以Windows环境为示例,以Eclipse工具为主(也可以用IDEA).网上也有很多开发的文章,在此也参考他们的内容只作简单的介绍和 ...
随机推荐
- AngularJS方法 —— angular.bootstrap
描述: 此方法用于手动加载angularjs模板 (官方翻译:注意基于端到端的测试不能使用此功能来引导手动加载,他们必须使用ngapp. angularjs会检测这个模板是否被浏览器加载或者加载多次并 ...
- LA4728 Squares
题意 PDF 分析 就是求凸包点集的直径. 当然选择旋转卡壳. 然后是实现上的技巧: 当Area(p[u], p[u+1], p[v+1]) <= Area(p[u], p[u+1], p[v] ...
- Dawn 阿里开源前端开发构建工具
Dawn 取「黎明.破晓」之意,原为「阿里云·业务运营团队」内部的前端构建和工程化工具,现已完全开源.它通过pipeline 和 middleware 将开发过程抽象为相对固定的阶段和有限的操作,简化 ...
- 3 循环语句——《Swift3.0从入门到出家》
3 循环语句 当一段代码被多次重复利用的使用我们就使用循环 swift提供了三种形式的循环语句 1.while 循环 2.repeat — while 循环 3.for — in 循环 while 循 ...
- The type javax.xml.rpc.ServiceException cannot be resolved.It is indirectly
The type javax.xml.rpc.ServiceException cannot be resolved.It is indirectly 博客分类: 解决方案_Java 问题描述:T ...
- Delphi AES加密(转)
(**************************************************************) (* Advanced Encryption Standard (AE ...
- base64图片上传,并根据不同项目进行智能修改图片
前台传图片的base64格式,后台处理方式//处理图片信息 返回对应的路径public function uploadBaseIma($imgArr){ $result = array(); //将路 ...
- SpringMvc入门一----介绍
Spring Mvc简介: Spring Web MVC是一种基于Java的实现了Web MVC设计模式的请求驱动类型的轻量级Web框架,即使用了MVC架构模式的思想,将web层进行职责解耦,基于请求 ...
- java代码求分数等级的输出~~~
总结:无论是switch-case-break语句 都不要忘了跳出当前循环,即break; 还有这个输入的分数我如何控制在100以内???? package com.c2; //实现分数等级的输出. ...
- Train-Alypay-Cloud:蚂蚁金融云知识点
ylbtech-Train-Alypay-Cloud:蚂蚁金融云知识点 1.返回顶部 1. 1.数据库与缓存结合使用https://www.cloud.alipay.com/docs/2/47337 ...