spark SQL编程
1.编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
| 1,Ella,36 2,Bob,29 3,Jack,29 |
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
import org.apache.spark.sql.types._
import org.apache.spark.sql.Encoder
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object RDDtoDF {
def main(args: Array[String]) {
val spark=SparkSession.builder().appName("RddToFrame").master("local").getOrCreate()
import spark.implicits._
val employeeRDD=spark.sparkContext.textFile("file:///usr/local/spark/employee.txt")
val schemaString="id name age"
val fields=schemaString.split(" ").map(fieldName=>StructField
(fieldName,StringType,nullable = true))
val schema = StructType(fields)
val rowRDD = employeeRDD.map(_.split(",")).map(attributes =>
Row(attributes().trim, attributes(), attributes().trim)) val employeeDF = spark.createDataFrame(rowRDD, schema)
employeeDF.createOrReplaceTempView("employee")
val results=spark.sql("select id,name,age from employee")
results.map(t => "id:"+t()+","+"name:"+t()+","+"age:"+t()).show() }
}

2.编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的
两行数据。
表 6-2 employee 表原有数据
| id | name | gender | Age |
| 1 | Alice | F | 22 |
| 2 | John | M | 25 |
打开mysql


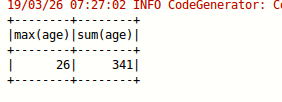
(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。
表 6-3 employee 表新增数据
| id | name | gender | age |
| 3 | Mary | F | 26 |
| 4 | Tom | M | 23 |
import java.util.Properties
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
object TestMySQL {
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("TestMySQL").master("local").getOrCreate()
import spark.implicits._
val employeeRDD=spark.sparkContext.parallelize(Array("3 Mary F 26","4 Tom M 23")).map(_.split(" "))
val schema=StructType(List(StructField("id",IntegerType,
true),StructField("name",StringType,true),StructField("gender",StringType,true),
StructField("age",IntegerType,true)))
val rowRDD=employeeRDD.map(p=>Row(p().toInt,p().trim,p().trim,p().toInt))
val employeeDF=spark.createDataFrame(rowRDD,schema)
val prop=new Properties()
prop.put("user","root")
prop.put("password","wangli")
prop.put("driver","com.mysql.jdbc.Driver")
employeeDF.write.mode("append").jdbc("jdbc:mysql://localhost:3306/sparktest","sparktest.employee",prop)
val jdbcDF = spark.read.format("jdbc").option("url",
"jdbc:mysql://localhost:3306/sparktest").option("driver","com.mysql.jdbc.Driver").option("dbtable","employee")
.option("user","root").option("password", "wangli").load()
jdbcDF.agg("age" -> "max", "age" -> "sum").show()
} }
spark SQL编程的更多相关文章
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
- Spark SQL 编程初级实践
一.实验目的 (1) 通过实验掌握 Spark SQL 的基本编程方法: (2) 熟悉 RDD 到 DataFrame 的转化方法: (3) 熟悉利用 Spark ...
- 第五周周二练习:实验 5 Spark SQL 编程初级实践
1.题目: 源码: import java.util.Properties import org.apache.spark.sql.types._ import org.apache.spark.sq ...
- spark实验(五)--Spark SQL 编程初级实践(1)
一.实验目的 (1)通过实验掌握 Spark SQL 的基本编程方法: (2)熟悉 RDD 到 DataFrame 的转化方法: (3)熟悉利用 Spark SQL 管理来自不同数据源的数据. 二.实 ...
- Spark SQL编程指南(Python)
前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询.它的核心是一个特殊类型的Spark RDD:SchemaRDD. SchemaRDD类似于传统关 ...
- 实验5 Spark SQL 编程初级实践
源文件内容如下(包含 id,name,age),将数据复制保存到 ubuntu 系统/usr/local/spark 下, 命名为 employee.txt,实现从 RDD 转换得到 DataFram ...
- Spark SQL编程指南(Python)【转】
转自:http://www.cnblogs.com/yurunmiao/p/4685310.html 前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询 ...
随机推荐
- Git教程--廖雪峰
Git简介 1.Git是目前世界上最先进的分布式版本控制系统(没有之一) 2.集中式和分布式版本控制系统有什么区别呢? 区别在于历史版本维护的位置:Git本地仓库包含代码库还有历史库,在本地 ...
- ParameterizedType的作用
public interface ParameterizedType extends Type subParam.Java package com.example.test; public clas ...
- python中的os模块几个常用的方法
os.getcwd() 得到当前工作目录,即当前python脚本工作的目录路径 os.remove(file):删除一个文件 os.mkdir(name):创建目录 os.path.exists(na ...
- orcl 对table的一些操作
删除 table:drop table 表名: 恢复删除 : flashback table 表名 to before drop: 清空table : truncate table 表名; 恢复清空: ...
- VS Code 运行html文件
用VS Code编写html文件,想在VS Code中直接打开运行,配置如下: 配置tasks.json 打开VS Code,点击"终端",选择"配置任务". ...
- Android学习笔记 Toast屏幕提示组件的使用方法
activity_main.xml <LinearLayout xmlns:android="http://schemas.android.com/apk/res/android&qu ...
- LoadRunner---杂问题&接口测试
问题1] 响应时间是系统完成事务执行准备后所采集的时间戳和系统完成待执行事务后所采集的时间戳之间的时间间隔,是衡量特定类型应用事务性能的重要指标,标志了用户执行一项操作大致需要多长时间.[问题2] 系 ...
- iOS 开发技术体系
iOS 开发技术体系图: - 层级 | 主要框架 - ---------------------|--------------------------------------------------- ...
- MySQL参数log_bin_trust_function_creators
问题:执行创建函数的sql文件报错如下: [Err] 1418 - This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA ...
- css清除浮动的8种方法以及优缺点
浮动会使当前标签产生上浮的效果,同时会影响到前后的标签.父级标签的位置及width height 属性.而且同样的代码,在各种浏览器中效果可能不同,这样让清除浮动更难了.清除浮动引起的问题有很多的方法 ...