Spark集群数据处理速度慢(数据本地化问题)
SparkStreaming拉取Kafka中数据,处理后入库。整个流程速度很慢,除去代码中可优化的部分,也在spark集群中找原因。
发现:
集群在处理数据时存在移动数据与移动计算的区别,也有些其他叫法,如:数据本地化、计算本地化、任务本地化等。
自己简单理解:
假设集群有6个节点,来了一批数据共12条,数据被均匀的分布在了每个节点,也就是每个节点2条。现在要开始处理这些数据。
一种情况是:某数据由哪个节点处理被随机的分配,类似A节点存了数据1和数据2却可能被要求处理C节点的数据5和数据6,C节点的数据5和数据6就被备份到A节点,而A节点的数据又要备份到其他某一节点用于被处理。集群节点间存在大量数据移动,影响了速度。
另一种情况:某节点自身储存的数据就由自身来处理,比如A节点存储了数据1和数据2,那么数据1和数据2就由A节点来计算,C节点存储了数据5和数据6,那么数据5和数据6就由C节点来计算。这也就避免了数据的移动。
当然实际要比我描述的复杂得多,我的理解肯定也有不对的地方。
浏览器打开spark 8080端口master界面,图中红色箭头处如果显示各机器IP地址那就很有可能会造成移动数据的问题。
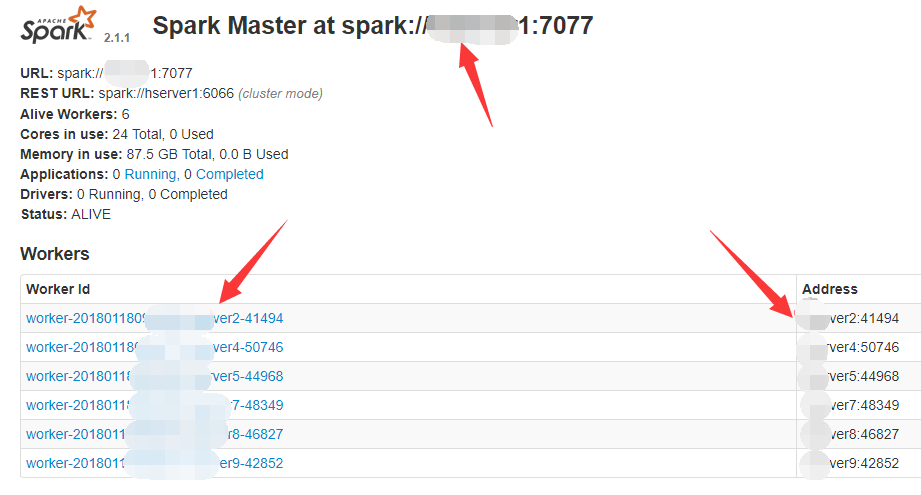
解决:
先停止spark集群,在master机器用 start-master.sh 启动,然后分别在每一台worker机器用 start-slave.sh -h 本机hostname spark://master机器hostname:7077 启动。
过程中可能遇到很多问题,多注意每台机器上的几个文件中的内容是否有问题:/etc/hosts, spark中conf文件夹中spark-env.sh和slaves
Spark集群数据处理速度慢(数据本地化问题)的更多相关文章
- 大数据技术之_19_Spark学习_01_Spark 基础解析 + Spark 概述 + Spark 集群安装 + 执行 Spark 程序
第1章 Spark 概述1.1 什么是 Spark1.2 Spark 特点1.3 Spark 的用户和用途第2章 Spark 集群安装2.1 集群角色2.2 机器准备2.3 下载 Spark 安装包2 ...
- CentOS6安装各种大数据软件 第十章:Spark集群安装和部署
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据学习day18----第三阶段spark01--------0.前言(分布式运算框架的核心思想,MR与Spark的比较,spark可以怎么运行,spark提交到spark集群的方式)1. spark(standalone模式)的安装 2. Spark各个角色的功能 3.SparkShell的使用,spark编程入门(wordcount案例)
0.前言 0.1 分布式运算框架的核心思想(此处以MR运行在yarn上为例) 提交job时,resourcemanager(图中写成了master)会根据数据的量以及工作的复杂度,解析工作量,从而 ...
- 大数据平台搭建-spark集群安装
版本要求 java 版本:1.8.*(1.8.0_60) 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downl ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- hbase集群写不进去数据的问题追踪过程
hbase从集群中有8台regionserver服务器,已稳定运行了5个多月,8月15号,发现集群中4个datanode进程死了,经查原因是内存 outofMemory了(因为这几台机器上部署了spa ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- Spark集群的任务提交执行流程
本文转自:https://www.linuxidc.com/Linux/2018-02/150886.htm 一.Spark on Standalone 1.spark集群启动后,Worker向Mas ...
- Spark集群部署
Spark是通用的基于内存计算的大数据框架,可以和hadoop生态系统很好的兼容,以下来部署Spark集群 集群环境:3节点 Master:bigdata1 Slaves:bigdata2,bigda ...
随机推荐
- 在linux下搭建wiki环境【转】
转自:http://blog.csdn.net/chy800/article/details/6906090 由于公司需要一个知识共享的系统,选择wiki来实现.经过准备决定使用Linux+xampp ...
- Git常用命令总结【转】
转自:http://www.cnblogs.com/mengdd/p/4153773.html 查看.添加.提交.删除.找回,重置修改文件 git help <command> # 显示c ...
- easyui 在子tabs中打开新tabs(关于easyUI在子页面增加显示tabs的一个问题)
现在说的是在子页面点个按钮也能触发增加子页面的情况. 情景是,在父页面上有个div如: <div class="easyui-tabs" id="main" ...
- 自建yum镜像
#!/usr/bin/python #-*- coding: utf-8 -*- import requests import sys,logging,traceback from bs4 impor ...
- mysql约束与索引的区别
一:约束 作用:是为了保证数据的完整性而实现的一套机制,它具体的根据各个不同的数据库的实现而有不同的工具(约束): 这里主要讲解mysql的约束: 1.非空约束:not null; 指示某列不能存储 ...
- 使用WindowManager添加View——悬浮窗口的基本原理
Android系统中的“窗口”类型虽然很多,但只有两大类是经常使用的:一是由系统进程管理的,称之为“系统窗口”:第二个就是由应用程序产生的,用于显示UI界面的“应用窗口”.如果大家熟悉WindowMa ...
- 删除某个ros包之后catkin_make冒错
CMake Error at /home/ubuntu/Workspaces/rosProject/workspace1/devel/share/costmap_2d/cmake/costmap_2d ...
- PHP7中php.ini、php-fpm和www.conf的配置(转)
根据前文 <2015博客升级记(五):CentOS 7.1编译安装PHP7> 的 configure 编译参数设定,安装后的PHP7配置文件所在路径是 /usr/local/php7/et ...
- (二)centos7安装zabbix agentd端
关闭防火墙和selinux systemctl stop firewalld systemctl disable firewalld sed -ri '/^SELINUX=/cSELINUX=disa ...
- 从dao层查出的数据到页面时数值都是零的异常
异常问题: IllegalArgumentException: argument type mismatch at cn.tedu.utils.BeanListHandler.handle(BeanL ...