01_Java解析XML
【打印list、Map集合的工具方法】
/**
* 打印List集合对应的元素
*/
public void printList(List<Object> list){
for(Object o:list){
System.out.println(o.toString());
}
} /**
* 打印Map集合对应的key-value
*/
public void printMap(Map<String,String> map){
Iterator it=map.entrySet().iterator();
while(it.hasNext()){
Entry entry=(Entry) it.next();
String key=(String) entry.getKey();
String value=(String) entry.getValue();
System.out.println("[ key="+key+", value="+value+" ]");
}
}
【cnBlogs.xml,保存在C:/cnBlogs.xml】
<?xml version="1.0" encoding="UTF-8"?>
<spiderman name="开源中国GIT">
<property key="duration" value="30s" /><!-- 运行时间 0 表示永久,可以给 {n}s {n}m {n}h {n}d -->
<property key="scheduler.period" value="24h" /><!-- 调度间隔时间 -->
<property key="logger.level" value="WARN" /><!-- 日志级别 INFO DEBUG WARN ERROR OFF --> <property key="worker.download.enabled" value="1" /><!-- 是否开启下载工人 -->
<property key="worker.extract.enabled" value="1" /><!-- 是否开启解析工人 -->
<property key="worker.result.enabled" value="1" /><!-- 是否开启结果处理工人 --> <property key="worker.download.class" value="net.kernal.spiderman.worker.download.impl.WebDriverDownloader" />
<property key="worker.download.chrome.driver" value="dist/chromedriver.exe" /><!-- WebDriver下载器的Chrome驱动 -->
<property key="worker.download.selector.delay" value="1s" /><!-- WebDriver下载器的延时时间 --> <property key="worker.download.size" value="1" /><!-- 下载线程数 -->
<property key="worker.extract.size" value="2" /><!-- 页面抽取线程数 -->
<property key="worker.result.size" value="2" /><!-- 结果处理线程数 -->
<property key="worker.result.handler" value="net.kernal.spiderman.worker.result.handler.impl.FileJsonResultHandler" />
<property key="worker.result.store" value="store/result" /><!-- 采集结果放置目录 -->
<property key="queue.store.path" value="store" /><!-- 检查器需要用到BDb存储 --> <!-- 种子 -->
<seed url="http://www.cnblogs.com/HigginCui/p/5811631.html" />
<seed url="http://www.cnblogs.com/HigginCui/p/5811234.html" />
<seed url="http://www.cnblogs.com/HigginCui/p/5827356.html" />
<seed url="http://www.cnblogs.com/HigginCui/p/5811494.html" /> <!-- 页面抽取规则 -->
<extract>
<extractor name="HtmlCleaner" class="net.kernal.spiderman.worker.extract.extractor.impl.HtmlCleanerExtractor" isDefault="1" />
<extractor name="Text" class="net.kernal.spiderman.worker.extract.extractor.impl.TextExtractor" />
<page name="我的项目列表" extractor="HtmlCleaner">
<url-match-rule type="equals">http://www.cnblogs.com/HigginCui/p/5811631.html</url-match-rule>
<model>
<field name="项目URL" isForNewTask="1" isArray="1" xpath="//a[@class='project']" attr="href">
<filter type="script">'http://www.cnblogs.com/HigginCui/p/5811631.html'+$this</filter>
</field>
</model>
</page>
<page name="项目详情" extractor="Text">
<url-match-rule type="startsWith">http://www.cnblogs.com/HigginCui/p/5811494.html</url-match-rule>
</page>
</extract>
</spiderman>

【test1.java】 使用extractModel(Object obj,String modelXpath)方法抽取对应xpath元素的方法
public class Demo01 {
/**
* xpath提供了对Xpath计算环境和表达式的访问
*/
private XPath xpath;
/**
* Document表示整个HTML或XML文档,它是文档的根,提供对文档数据的基本访问。
*/
private Document doc;
private Transformer transformer;
@Test
public void test1() throws ParserConfigurationException, SAXException, IOException {
InputStream is=new FileInputStream("C:\\cnBlogs.xml");
DocumentBuilder db=DocumentBuilderFactory.newInstance().newDocumentBuilder(); //从DOM工厂获得DOM解析器
doc=db.parse(is); //解析的XML文档C:\\cnBlogs.xml的输入流,得到一个Document
xpath=XPathFactory.newInstance().newXPath();
//抽取property中的key属性
System.out.println("=========抽取property中的key属性==========");
List<Object> propertyKeyList=extractModel(doc,"//property/@key");
printList(propertyKeyList);
//抽取seed中的url属性
System.out.println("=========抽取seed中的url属性==========");
List<Object> seedUrlList=extractModel(doc,"//seed/@url");
printList(seedUrlList);
//抽取extractor中的class属性
System.out.println("=========抽取extractor中的class属性==========");
List<Object> extractorClassList=extractModel(doc,"//extractor/@class");
printList(extractorClassList);
//抽取url-match-rule的text()文本
System.out.println("=========抽取url-match-rule的text()文本==========");
List<Object> url_match_rulTextList=extractModel(doc,"//url-match-rule/text()");
printList(url_match_rulTextList);
}
/**
* 抽取对应Xpath为"modelXpath"的元素的方法
*/
public List<Object> extractModel(Object obj,String modelXpath){
NodeList nodeList = null;
try {
/**
* Xpath.compile(String expression):编译一个xpath表达式expression提供以后计算,返回一个XPathExpression
* XPathExpression.evalute(Object item,QName returnType):计算指定上下文的Xpath表达式,返回指定的类型的结果
*/
nodeList = (NodeList)this.xpath.compile(modelXpath).evaluate(obj, XPathConstants.NODESET);
} catch (XPathExpressionException e) {
e.printStackTrace();
}
//下面是将NodeList集合转换成我们普通的ArrayList集合
List<Object> mNodes = new ArrayList<Object>();
for (int i = ; i < nodeList.getLength(); i++){ //getLength():获取NodeList中的结点数
Node node = nodeList.item(i); //返回NodeList集合中的第i个项
mNodes.add(node);
}
return mNodes;
}
}
【运行结果】

【小结】
 [ Document javax.xml.parsers.DocumentBuilder.parse(InputStream is) throws SAXException, IOException ]
[ Document javax.xml.parsers.DocumentBuilder.parse(InputStream is) throws SAXException, IOException ] [ Object javax.xml.xpath.XPathExpression.evaluate(Object item, QName returnType) throws XPathExpressionException ]
[ Object javax.xml.xpath.XPathExpression.evaluate(Object item, QName returnType) throws XPathExpressionException ] [
[ @Test
public void testNode() throws Exception{
InputStream is=new FileInputStream("C:\\cnBlogs.xml");
DocumentBuilder db=DocumentBuilderFactory.newInstance().newDocumentBuilder(); //从DOM工厂获得DOM解析器
doc=db.parse(is); //解析的XML文档C:\\cnBlogs.xml的输入流,得到一个Document
xpath=XPathFactory.newInstance().newXPath(); List<Object> propertyNodeList=extractModel(doc,"//property"); //抽取对应的model
for(Object o: propertyNodeList){
Node node=(Node) o;
System.out.println("【 =======nodeType:"+node.getNodeType()+", nodeName:"+node.getNodeName()+" =======】");
NamedNodeMap attrs=node.getAttributes(); //获取所有的属性name-value(所以是Map类型的)
for(int i=;i<attrs.getLength();i++){ //遍历所有的map
Node n=attrs.item(i);
System.out.println("[ nodeType:"+n.getNodeType()+", nodeName:"+n.getNodeName()+", nodeValue:"+n.getNodeValue()+" ]"); //得到属性的name 和 属性的value
}
}
}
【运行结果(部分)】
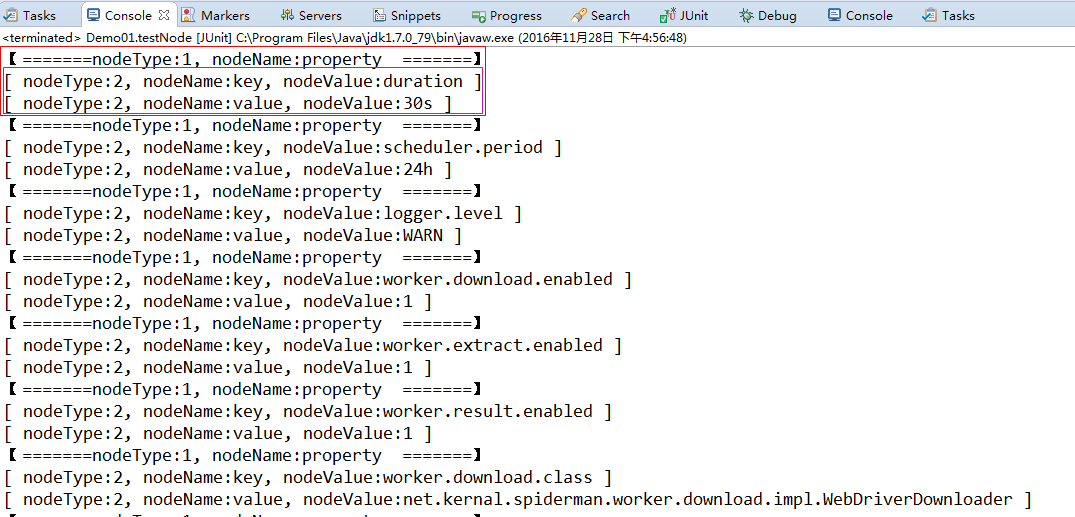
【解释】

01_Java解析XML的更多相关文章
- Android 解析XML文件和生成XML文件
解析XML文件 public static void initXML(Context context) { //can't create in /data/media/0 because permis ...
- Android之解析XML
1.XML:可扩展标记语言. 可扩展标记语言是一种很像超文本标记语言的标记语言. 它的设计宗旨是传输数据,而不是显示数据. 它的标记没有被预定义.需要自行定义标签. 它被设计为具有自我描述性. 是W3 ...
- Android之Pull解析XML
一.Pull解析方法介绍 除了可以使用SAX和DOM解析XML文件,也可以使用Android内置的Pull解析器解析XML文件.Pull解析器的运行方式与SAX解析器相似.它也是事件触发的.Pull解 ...
- Android之DOM解析XML
一.DOM解析方法介绍 DOM是基于树形结构的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树,检索所需数据.分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息 ...
- Android之SAX解析XML
一.SAX解析方法介绍 SAX(Simple API for XML)是一个解析速度快并且占用内存少的XML解析器,非常适合用于Android等移动设备. SAX解析器是一种基于事件的解析器,事件驱动 ...
- Android 使用pull,sax解析xml
pull解析xml文件 1.获得XmlpullParser类的引用 这里有两种方法 //解析器工厂 XmlPullParserFactory factory=XmlPullParserFactory. ...
- 用 ElementTree 在 Python 中解析 XML
用 ElementTree 在 Python 中解析 XML 原文: http://eli.thegreenplace.net/2012/03/15/processing-xml-in-python- ...
- java解析xml的三种方法
java解析XML的三种方法 1.SAX事件解析 package com.wzh.sax; import org.xml.sax.Attributes; import org.xml.sax.SAXE ...
- WP8解析XML格式文件
DOTA2 WebAPI请求返回的格式有两种,一种是XML,一种是JSON,默认是返回JSON格式,如果要返回XML格式的话,需要在加上format=xml. 这里举一个简单的解析XML格式的例子(更 ...
随机推荐
- 在iOS应用程序中打开设备设置界面及其中某指定的选项界面
摘自:http://stackoverflow.com/questions/8246070/ios-launching-settings-restrictions-url-scheme [[UIApp ...
- 从零开始学android开发-获取TextView的值
昨日写一个Android Demo,逻辑大概是从TextView获取其中的值,然后处理后再放回TextView中.整个处理过程是由一个Button的OnClick触发的. 可是在调试的过程中,一点击B ...
- 块设备驱动之NAND FLASH驱动程序
转载请注明出处:http://blog.csdn.net/ruoyunliufeng/article/details/25240909 一.框架总结 watermark/2/text/aHR0cDov ...
- Android背景渐变色效果
Android设置背景色可以通过在res/drawable里定义一个xml,如下: [代码]xml代码: 1 <?xml version="1.0" encoding=&qu ...
- 手把手教你Android来去电通话自动录音的方法
我们在使用Android手机打电话时,有时可能会需要对来去电通话自动录音,本文就详细讲解实现Android来去电通话自动录音的方法,大家按照文中的方法编写程序就可以完成此功能. 来去电自动录音的关键在 ...
- open_table与opened_table --2
好多人在调优Mysql的时候,总是对open_tables和opend_tables两个参数分别不清. 网上好多解释都是这样的:open_tables:当前打开表的数量opened_tables:当前 ...
- qt helper
qt帮助文档(中文版) http://www.kuqin.com/qtdocument/index.html qt基础 http://www.devbean.net/2012/08/qt-study- ...
- 【转】频点CTO张成:基于Cocos2d的MMORPG开发经验
http://www.9ria.com/plus/view.php?aid=27698 作者: zhiyuanzhe3 发表时间: 2013-06-29 17:46 6月29日,由9Tech社区.51 ...
- phpcms v9 模板标签说明整理
1.{template "content","header"} 2.网站网址调用:{siteurl($siteid)}: 3.标签get:分页,{pc:get ...
- JAVA获取CLASSPATH路径--转
ClassLoader提供了两个方法用于从装载的类路径中取得资源: public URL getResource(String name); public InputStream ge ...