从最近MySQL的优化工作想到的
最近决定将以前同事写的存储过程查看一遍,寻找一些代码上写的不太好的地方,争取进行修改以后让这些过程达到一个很好的运行速度。下面是遇到的最多的几个问题。
我遇到了这样的一个SQL:
select name, count(*) from (select name from table_1) a group by a.name;
MySQL的执行计划对于这种派生表的解释非常的不友好,但是能直观的感觉到的是,这个SQL执行速度特别的慢。查看这个表table_1发现,name字段是有索引的。审视这段代码,可以推断出当时程序员的想法,应该是想让数据库扫描更小的结果集,因为select *是很不好的习惯。不过他应该忽略了一个MySQL的很重要的特点就是索引。MySQL的索引是个很有意思的东西,是我从Oracle转过来感觉最好玩的东西,好玩的地方就在于,可以优化group by。当我把这个SQL改成如下SQL以后:
select name, count(*) from table_1 group by name;
这样一来,这段SQL的执行速度就非常的快了,extra列明确的显示了using index,索引覆盖查询,速度杠杠的。
其实这种错误应该是程序员常犯的,因为程序员对Java等代码超级熟悉,但是对于SQL,基本上都是大学的时候学习的SQL,用SQLServer练出来的,基本上没有对数据库进行非常深入的研究,其实每种数据库中,同一条SQL的执行计划都是不尽相同的,这也就是企业有一个专业的DBA的一个作用。
下面,就是一个让人很头疼的错误:
select name, userid from table_1 where name = null;
不管是MySQL还是Oracle,对这种SQL的写法的规范都是where name is (not) null。null这个值,在不管什么数据库里都是一个让人(包括程序员和DBA)都很头疼的东西。我对MySQL的理解还不够深入,但是根据某一本《Oracle DBA手记》中记载,Oracle中每种数据类型的null都代表了不一样的意义。
做了下面一个实验:
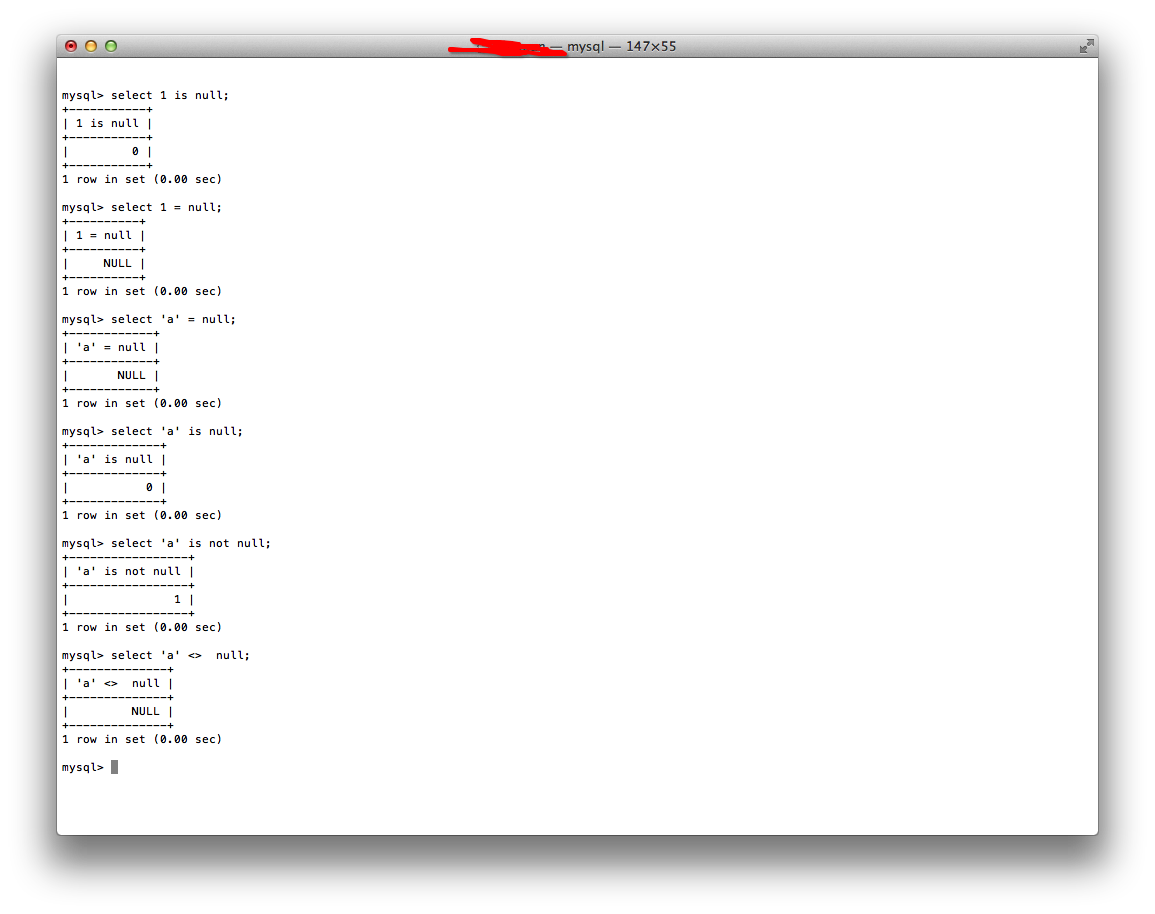
可以看出来,不管是“= null”还是“<> null”,得到的值其实都是不确定,也就是null。因此,必须要写成is (not) null。在《剑破冰山》这本书里也有对Oracle的null值的详细介绍。
总结一下最近的工作,我研究了小半年时间的MySQL,发现这个开源的数据库并不像我过去认为的那样,就是一个互联网数据库。这个数据库在面向OLAP复杂计算的方面确实和Oracle,DB2等商用数据库之间有不小的差距,不过在MariaDB这个分支中,这部分有了不小的进步,相信后面的MySQL版本中也会越来越好。其实这个数据库最让我感兴趣的不是开源,因为我确实看不懂那么长的源代码,我的C语言水平就是大学毕业水平。这个数据库最让我感兴趣(起码现在来讲)是它的索引,它的索引和Oracle有很大的不同,尤其是InnoDB的表整个就是用索引组织起来的,在简单的查询的时候,一个索引覆盖查询就可以无敌于天下了,在group by和order by的时候,如果是索引字段,效率会相当的高。
其实我还想说的就是,一个团队里,如果涉及到大量存储过程的编写,一定要有一个专业的DBA人员参与其中。SQL是一个标准,横跨了所有的关系型数据库,但是每一种关系型数据库对SQL的实现又不尽相同,因此同样的一段SQL,放到不同的数据库上执行,效率上就会千差万别。而SQL又非常容易用人最习惯最简单的思维写出来,比如搜索一个订单表里美国员工生成的订单信息,SQL有可能是这样的:
select * from orders t1
where t1.employee_id in (select employee_id from employee t2
where t2.nation = 'USA');
如果是Oracle这样的商业数据库,这个SQL的执行效率可能会比较好,但是应该不如用exists的SQL。但是当这段SQL在MySQL中执行的时候,效率就很差了,因为很多人都知道,MySQL的子查询效率实在是不敢恭维。这段代码会被改为相关子查询,而且随着数据量的增长,执行时间会越来越长。这段代码如果改成下面的SQL,效果会更好:
select t1.*
from orders t1
inner join employee t2
on t1.employee_id = t2.employee_id
where t2.nation = 'USA';
如果表上有索引,执行速度快极了。
写SQL,还是要首先研究这个数据库的原理,然后慎而又慎的写。
从最近MySQL的优化工作想到的的更多相关文章
- MYSQL之性能优化 ----MySQL性能优化必备25条
今天,数据库的操作越来越成为整个应用的性能瓶颈了,这点对于Web应用尤其明显.关于数据库的性能,这并不只是DBA才需要担心的事,而这更是我 们程序员需要去关注的事情.当我们去设计数据库表结构,对操作数 ...
- 百万行mysql数据库优化和10G大文件上传方案
百万行mysql数据库优化和10G大文件上传方案 最近这几天正在忙这个优化的方案,一直没时间耍,忙碌了一段时间终于还是拿下了这个项目?项目中不要每次都把程序上的问题,让mysql数据库来承担,它只是个 ...
- Mysql 索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
- mySql索引优化分析
MySQL索引优化分析 为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字 ...
- MySQL性能优化必备25条
1. 为查询缓存优化你的查询 大多数的MySQL服务器都开启了查询缓存.这是提高性最有效的方法之一,而且这是被MySQL的数据库引擎处理的.当有很多相同的查询被执行了多次的时候,这些查询结果会被放到一 ...
- 【学习】016 MySQL数据库优化
MySQL如何优化 表的设计合理化(符合3NF) 添加适当索引(index) [四种: 普通索引.主键索引.唯一索引unique.全文索引] SQL语句优化 分表技术(水平分割.垂直分割) 读写[写: ...
- 一本彻底搞懂MySQL索引优化EXPLAIN百科全书
1.MySQL逻辑架构 日常在CURD的过程中,都避免不了跟数据库打交道,大多数业务都离不开数据库表的设计和SQL的编写,那如何让你编写的SQL语句性能更优呢? 先来整体看下MySQL逻辑架构图: M ...
- Mysql性能优化:为什么你的count(*)这么慢?
导读 在开发中一定会用到统计一张表的行数,比如一个交易系统,老板会让你每天生成一个报表,这些统计信息少不了 sql 中的count函数. 但是随着记录越来越多,查询的速度会越来越慢,为什么会这样呢?M ...
- mysql深度优化与理解(迄今为止读到最优秀的mysql博客)
转载:https://www.cnblogs.com/shenzikun1314/p/6396105.html 本篇深入了解查询优化和服务器的内部机制,了解MySql如何执行特定查询,从中也可以知道如 ...
随机推荐
- 【安全组网】思科IOS设备基础应用
思科IOS有2种主要命令行模式:用户模式与特权模式 1.用户模式(user mode),当用“>”表示实在用户模式下 2.特权模式(exec mode),当用"#"表示是在特 ...
- Linux内核OOM机制的详细分析
Linux 内核有个机制叫OOM killer(Out-Of-Memory killer),该机制会监控那些占用内存过大,尤其是瞬间很快消耗大量内存的进程,为了防止内存耗尽而内核会把该进程杀掉.典型的 ...
- 蓝牙(2)用BluetoothAdapter搜索蓝牙设备示例
注意在搜索之前要先打开蓝牙设备 package com.e.search.bluetooth.device; import java.util.Set; import android.app.Acti ...
- C#中string.Format()和ToString()格式化方法
C#数字格式化输出是我们在编程中经常需要处理的事情,那么这里向你介绍了一些C#数字格式化输出的例子,这样就会方便你来选择和比较,什么方式是比较适合自己项目的. int a = 12345678; C# ...
- xcopy 复制了0个文件
xcopy /Y "..\..\..\SolutionItems\zbmyuncore.db" "..\ZITaker" 复制zbmyuncore.db文件的时 ...
- git bash中带空格的文件夹以及文件的处理
空格用'\ '表示,输入的时候,是不需要单引号的 total 338drwxr-xr-x 9 Administ Administ 4096 Aug 24 23:53 HDTHelperdrwxr-xr ...
- sdut 1570 c旅行
用搜索(bfs,dfs)做了半天,都超时,原来是dp; 参考博客:http://www.cnblogs.com/liuzezhuang/archive/2012/07/29/2613820.html ...
- apache开源项目--ApacheDS
ApacheDS (Apache Directory Server)的核心是目录服务,可以保存数据,并对不同类型的数据进行搜索操作.协议的实现在目录服务器顶层工作,提供与数据存储.搜索和检索有关的 I ...
- SharePoint 2010 自定义 字段 类型--------省市区联动
转:http://www.cnblogs.com/sp007/p/3384310.html 最近有几个朋友问到了有关自定义字段类型的问题,为了让更多的人了解自定义字段类型的方法,特写一篇博客与大家分享 ...
- 转换时间为 “XX分钟之前”
public static string getTimeAgo(string strDate) { string strTime = string.Empty; if (clsCommon.IsDat ...