Python爬虫开发【第1篇】【多线程爬虫及案例】
糗事百科爬虫实例:
地址:http://www.qiushibaike.com/8hr/page/1
需求:
使用requests获取页面信息,用XPath / re 做数据提取
获取每个帖子里的
用户头像链接、用户姓名、段子内容、点赞次数和评论次数保存到 json 文件内
#qiushibaike.py #import urllib
#import re
#import chardet import requests
from lxml import etree page = 1
url = 'http://www.qiushibaike.com/8hr/page/' + str(page)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8'} try:
response = requests.get(url, headers=headers)
resHtml = response.text html = etree.HTML(resHtml)
result = html.xpath('//div[contains(@id,"qiushi_tag")]') for site in result:
item = {} imgUrl = site.xpath('./div/a/img/@src')[0].encode('utf-8')
username = site.xpath('./div/a/@title')[0].encode('utf-8')
#username = site.xpath('.//h2')[0].text
content = site.xpath('.//div[@class="content"]/span')[0].text.strip().encode('utf-8')
# 投票次数
vote = site.xpath('.//i')[0].text
#print site.xpath('.//*[@class="number"]')[0].text
# 评论信息
comments = site.xpath('.//i')[1].text print imgUrl, username, content, vote, comments except Exception, e:
print e
Queue(队列对象)
Queue是python中的标准库,可以直接import Queue引用;队列是线程间最常用的交换数据的形式
python下多线程的思考
对于资源,加锁是个重要的环节。因为python原生的list,dict等,都是not thread safe的。而Queue,是线程安全的,因此在满足使用条件下,建议使用队列
初始化: class Queue.Queue(maxsize) FIFO 先进先出
包中的常用方法:
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.full 与 maxsize 大小对应
Queue.get([block[, timeout]])获取队列,timeout等待时间
创建一个“队列”对象
- import Queue
- myqueue = Queue.Queue(maxsize = 10)
将一个值放入队列中
- myqueue.put(10)
将一个值从队列中取出
- myqueue.get()
多线程爬虫示意图:
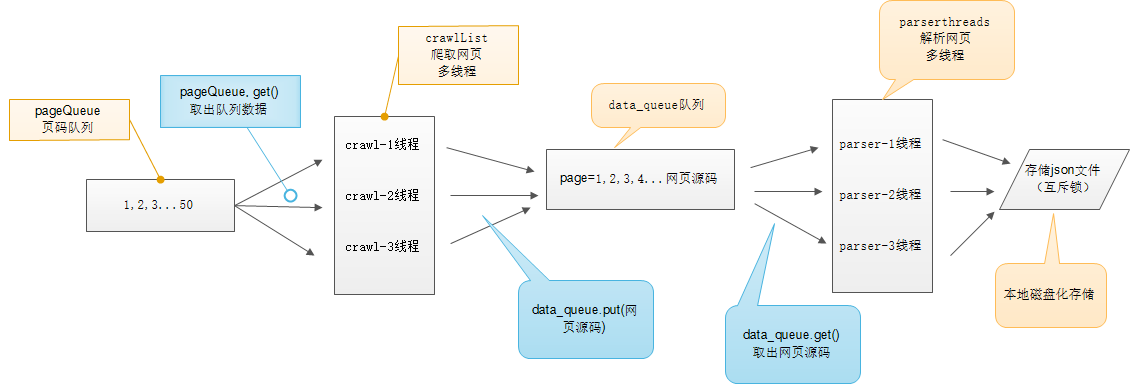
# -*- coding:utf-8 -*-
import requests
from lxml import etree
from Queue import Queue
import threading
import time
import json class thread_crawl(threading.Thread):
'''
抓取线程类
''' def __init__(self, threadID, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.q = q def run(self):
print "Starting " + self.threadID
self.qiushi_spider()
print "Exiting ", self.threadID def qiushi_spider(self):
# page = 1
while True:
if self.q.empty():
break
else:
page = self.q.get()
print 'qiushi_spider=', self.threadID, ',page=', str(page)
url = 'http://www.qiushibaike.com/8hr/page/' + str(page) + '/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
'Accept-Language': 'zh-CN,zh;q=0.8'}
# 多次尝试失败结束、防止死循环
timeout = 4
while timeout > 0:
timeout -= 1
try:
content = requests.get(url, headers=headers)
data_queue.put(content.text)
break
except Exception, e:
print 'qiushi_spider', e
if timeout < 0:
print 'timeout', url class Thread_Parser(threading.Thread):
'''
页面解析类;
''' def __init__(self, threadID, queue, lock, f):
threading.Thread.__init__(self)
self.threadID = threadID
self.queue = queue
self.lock = lock
self.f = f def run(self):
print 'starting ', self.threadID
global total, exitFlag_Parser
while not exitFlag_Parser:
try:
'''
调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。
如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。
如果队列为空且block为False,队列将引发Empty异常。
'''
item = self.queue.get(False)
if not item:
pass
self.parse_data(item)
self.queue.task_done()
print 'Thread_Parser=', self.threadID, ',total=', total
except:
pass
print 'Exiting ', self.threadID def parse_data(self, item):
'''
解析网页函数
:param item: 网页内容
:return:
'''
global total
try:
html = etree.HTML(item)
result = html.xpath('//div[contains(@id,"qiushi_tag")]')
for site in result:
try:
imgUrl = site.xpath('.//img/@src')[0]
title = site.xpath('.//h2')[0].text
content = site.xpath('.//div[@class="content"]/span')[0].text.strip()
vote = None
comments = None
try:
vote = site.xpath('.//i')[0].text
comments = site.xpath('.//i')[1].text
except:
pass
result = {
'imgUrl': imgUrl,
'title': title,
'content': content,
'vote': vote,
'comments': comments,
} with self.lock:
# print 'write %s' % json.dumps(result)
self.f.write(json.dumps(result, ensure_ascii=False).encode('utf-8') + "\n") except Exception, e:
print 'site in result', e
except Exception, e:
print 'parse_data', e
with self.lock:
total += 1 data_queue = Queue()
exitFlag_Parser = False
lock = threading.Lock()
total = 0 def main():
output = open('qiushibaike.json', 'a') #初始化网页页码page从1-10个页面
pageQueue = Queue(50)
for page in range(1, 11):
pageQueue.put(page) #初始化采集线程
crawlthreads = []
crawlList = ["crawl-1", "crawl-2", "crawl-3"] for threadID in crawlList:
thread = thread_crawl(threadID, pageQueue)
thread.start()
crawlthreads.append(thread) #初始化解析线程parserList
parserthreads = []
parserList = ["parser-1", "parser-2", "parser-3"]
#分别启动parserList
for threadID in parserList:
thread = Thread_Parser(threadID, data_queue, lock, output)
thread.start()
parserthreads.append(thread) # 等待队列清空
while not pageQueue.empty():
pass # 等待所有线程完成
for t in crawlthreads:
t.join() while not data_queue.empty():
pass
# 通知线程是时候退出
global exitFlag_Parser
exitFlag_Parser = True for t in parserthreads:
t.join()
print "Exiting Main Thread"
with lock:
output.close() if __name__ == '__main__':
main()
Python爬虫开发【第1篇】【多线程爬虫及案例】的更多相关文章
- python自动化开发-[第二十三天]-初识爬虫
今日概要: 1.爬汽车之家的新闻资讯 2.爬github和chouti 3.requests和beautifulsoup 4.轮询和长轮询 5.django request.POST和request. ...
- 【Python之路】特别篇--多线程与多进程
并发 与 并行 的区别: 解释一:并发是在同一实体上的多个事件,并行是在不同实体上的多个事件: 解释二:并发是指两个或多个事件在同一时间间隔发生,而并行是指两个或者多个事件在同一时刻发生. 并发:就是 ...
- python测试开发django-51.Ajax发送post请求登录案例
前言 我想实现一个登录功能:登录的接口是另外一个地方提供,页面上点登录按钮的时候,先访问登录接口,根据接口返回json信息判断是否登录成功,登录成功页面跳转,登录不成功,在登录首页显示失败原因 登录页 ...
- Python爬虫开发【第1篇】【Scrapy框架】
Scrapy 框架介绍 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架. Srapy框架,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以 ...
- Python爬虫开发【第1篇】【Scrapy入门】
Scrapy的安装介绍 Scrapy框架官方网址:http://doc.scrapy.org/en/latest Scrapy中文维护站点:http://scrapy-chs.readthedocs. ...
- Python爬虫开发【第1篇】【urllib2】
1.urlopen # urllib2_urlopen.py # 导入urllib2 库 import urllib2 # 向指定的url发送请求,并返回服务器响应的类文件对象,urlopen中有da ...
- 爬虫开发python工具包介绍 (1)
本文来自网易云社区 作者:王涛 本文大纲: 简易介绍今天要讲解的两个爬虫开发的python库 详细介绍 requests库及函数中的各个参数 详细介绍 tornado 中的httpcilent的应用 ...
- Python爬虫开发与项目实战
Python爬虫开发与项目实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1MFexF6S4No_FtC5U2GCKqQ 提取码:gtz1 复制这段内容后打开百度 ...
- Python爬虫开发与项目实战pdf电子书|网盘链接带提取码直接提取|
Python爬虫开发与项目实战从基本的爬虫原理开始讲解,通过介绍Pthyon编程语言与HTML基础知识引领读者入门,之后根据当前风起云涌的云计算.大数据热潮,重点讲述了云计算的相关内容及其在爬虫中的应 ...
随机推荐
- Windows使用Nginx+ffmpeg搭建RTMP服务器
简介Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器.nginx-rmtp-module是Nginx服务器的流媒体插件.nginx通过rtmp模块提供r ...
- LeetCode(34)Search for a Range
题目 Given a sorted array of integers, find the starting and ending position of a given target value. ...
- Java 新手学习日记一
Java 基础知识点掌握: 数据类型 变量就是申请内存来存储值.也就是说,当创建变量的时候,需要在内存中申请空间.内存管理系统根据变量的类型为变量分配存储空间,分配的空间只能用来储存该类型数据. 因此 ...
- 活动预告丨易盾CTO朱浩齐将出席2018 AIIA大会,分享《人工智能在内容安全的应用实践》
本文来自网易云社区 对于很多人来讲,仿佛昨天才燃起来的人工智能之火,转眼间烧遍了各个角落,如今我们的生活中,处处渗透着人工智能.10月16日,2018年 AIIA人工智能开发者大会在苏州举办,网易云易 ...
- python之Gui编程事件绑定 2014-4-8
place() 相对定位与绝对定位 相对定位 拖动会发生变化 绝对定位不会from Tkinter import *root = Tk()# Absolute positioningButton(ro ...
- linux进程按启动时间排序命令
show me the code... ps aux --sort=start_time|grep Full|grep -v grep
- javascript异步处理
http://www.ruanyifeng.com/blog/2015/04/generator.html
- php5.5编译安装
系统环境:centos6.5PHP包:5.5.15https://wiki.swoole.com/wiki/page/177.html下载 PHP 源码包wget http://cn2.php.net ...
- POJ1780 Code
KEY公司开发出一种新的保险箱.要打开保险箱,不需要钥匙,但需要输入一个正确的.由n位数字组成的编码.这种保险箱有几种类型,从给小孩子玩的玩具(2位数字编码)到军用型的保险箱(6位数字编码).当正确地 ...
- POJ2455 Secret Milking Machine【二分,最大流】
题目大意:N个点P条边,令存在T条从1到N的路径,求路径上的边权的最大值最小为多少 思路:做了好多二分+最大流的题了,思路很好出 二分出最大边权后建图,跑dinic 问题是....这题是卡常数的好题! ...