基于KNN的newsgroup 18828文本分类器的Python实现
还是同前一篇作为学习入门。
1. KNN算法描述:
step1: 文本向量化表示,计算特征词的TF-IDF值
step2: 新文本到达后,根据特征词确定文本的向量
step3 : 在训练文本集中选出与新文本向量最相近的k个文本向量,相似度度量采用“余弦相似度”,根据实验测试的结果调整k值,此次选择20
step4: 在新文本的k个邻居中,依次计算每类的权重,
step5: 比较类的权重,将新文本放到权重最大的那个类中
2. 文档TF-IDF计算和向量化表示
# -*- coding: utf-8 -*-
import time
from os import listdir
from math import log
from numpy import *
from numpy import linalg
from operator import itemgetter ###################################################
## 计算所有单词的IDF值
###################################################
def computeIDF():
fileDir = 'processedSampleOnlySpecial_2'
wordDocMap = {} # <word, set(docM,...,docN)>
IDFPerWordMap = {} # <word, IDF值>
countDoc = 0.0
cateList = listdir(fileDir)
for i in range(len(cateList)):
sampleDir = fileDir + '/' + cateList[i]
sampleList = listdir(sampleDir)
for j in range(len(sampleList)):
sample = sampleDir + '/' + sampleList[j]
for line in open(sample).readlines():
word = line.strip('\n')
if word in wordDocMap.keys():
wordDocMap[word].add(sampleList[j]) # set结构保存单词word出现过的文档
else:
wordDocMap.setdefault(word,set())
wordDocMap[word].add(sampleList[j])
print 'just finished %d round ' % i for word in wordDocMap.keys():
countDoc = len(wordDocMap[word]) # 统计set中的文档个数
IDF = log(20000/countDoc)/log(10)
IDFPerWordMap[word] = IDF return IDFPerWordMap ###################################################
## 将IDF值写入文件保存
###################################################
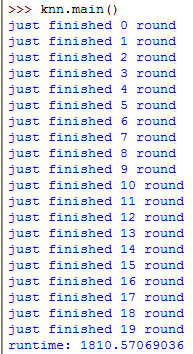
def main():
start=time.clock()
IDFPerWordMap = computeIDF()
end=time.clock()
print 'runtime: ' + str(end-start)
fw = open('IDFPerWord','w')
for word, IDF in IDFPerWordMap.items():
fw.write('%s %.6f\n' % (word,IDF))
fw.close() ########################################################
## 生成训练集和测试集的文档向量,向量形式<cate, doc, (word1, tdidf1), (word2, tdidf2),...> 存入文件
## @param indexOfSample 迭代的序号
## @param trainSamplePercent 训练集合和测试集合划分百分比
########################################################
def computeTFMultiIDF(indexOfSample, trainSamplePercent):
IDFPerWord = {} # <word, IDF值> 从文件中读入后的数据保存在此字典结构中
for line in open('IDFPerWord').readlines():
(word, IDF) = line.strip('\n').split(' ')
IDFPerWord[word] = IDF fileDir = 'processedSampleOnlySpecial_2'
trainFileDir = "docVector/" + 'wordTFIDFMapTrainSample' + str(indexOfSample)
testFileDir = "docVector/" + 'wordTFIDFMapTestSample' + str(indexOfSample) tsTrainWriter = open(trainFileDir, 'w')
tsTestWriter = open(testFileDir, 'w') cateList = listdir(fileDir)
for i in range(len(cateList)):
sampleDir = fileDir + '/' + cateList[i]
sampleList = listdir(sampleDir) testBeginIndex = indexOfSample * ( len(sampleList) * (1-trainSamplePercent) )
testEndIndex = (indexOfSample+1) * ( len(sampleList) * (1-trainSamplePercent) ) for j in range(len(sampleList)):
TFPerDocMap = {} # <word, 文档doc下该word的出现次数>
sumPerDoc = 0 # 记录文档doc下的单词总数
sample = sampleDir + '/' + sampleList[j]
for line in open(sample).readlines():
sumPerDoc += 1
word = line.strip('\n')
TFPerDocMap[word] = TFPerDocMap.get(word, 0) + 1 if(j >= testBeginIndex) and (j <= testEndIndex):
tsWriter = tsTestWriter
else:
tsWriter = tsTrainWriter tsWriter.write('%s %s ' % (cateList[i], sampleList[j])) # 写入类别cate,文档doc for word, count in TFPerDocMap.items():
TF = float(count)/float(sumPerDoc)
tsWriter.write('%s %f ' % (word, TF * float(IDFPerWord[word]))) # 继续写入类别cate下文档doc下的所有单词及它的TF-IDF值 tsWriter.write('\n') print 'just finished %d round ' % i #if i==0: break tsTrainWriter.close()
tsTestWriter.close()
tsWriter.close()
3. KNN算法的实现
def doProcess():
trainFiles = 'docVector/wordTFIDFMapTrainSample0'
testFiles = 'docVector/wordTFIDFMapTestSample0'
kNNResultFile = 'docVector/KNNClassifyResult' trainDocWordMap = {} # 字典<key, value> key=cate_doc, value={{word1,tfidf1}, {word2, tfidf2},...} for line in open(trainFiles).readlines():
lineSplitBlock = line.strip('\n').split(' ')
trainWordMap = {}
m = len(lineSplitBlock)-1
for i in range(2, m, 2): # 在每个文档向量中提取(word, tfidf)存入字典
trainWordMap[lineSplitBlock[i]] = lineSplitBlock[i+1] temp_key = lineSplitBlock[0] + '_' + lineSplitBlock[1] # 在每个文档向量中提取类目cate,文档doc,
trainDocWordMap[temp_key] = trainWordMap testDocWordMap = {} for line in open(testFiles).readlines():
lineSplitBlock = line.strip('\n').split(' ')
testWordMap = {}
m = len(lineSplitBlock)-1
for i in range(2, m, 2):
testWordMap[lineSplitBlock[i]] = lineSplitBlock[i+1] temp_key = lineSplitBlock[0] + '_' + lineSplitBlock[1]
testDocWordMap[temp_key] = testWordMap #<类_文件名,<word, TFIDF>> #遍历每一个测试样例计算与所有训练样本的距离,做分类
count = 0
rightCount = 0
KNNResultWriter = open(kNNResultFile,'w')
for item in testDocWordMap.items():
classifyResult = KNNComputeCate(item[0], item[1], trainDocWordMap) # 调用KNNComputeCate做分类 count += 1
print 'this is %d round' % count classifyRight = item[0].split('_')[0]
KNNResultWriter.write('%s %s\n' % (classifyRight,classifyResult))
if classifyRight == classifyResult:
rightCount += 1
print '%s %s rightCount:%d' % (classifyRight,classifyResult,rightCount) accuracy = float(rightCount)/float(count)
print 'rightCount : %d , count : %d , accuracy : %.6f' % (rightCount,count,accuracy)
return accuracy #########################################################
## @param cate_Doc 测试集<类别_文档>
## @param testDic 测试集{{word, TFIDF}}
## @param trainMap 训练集<类_文件名,<word, TFIDF>>
## @return sortedCateSimMap[0][0] 返回与测试文档向量距离和最小的类
#########################################################
def KNNComputeCate(cate_Doc, testDic, trainMap):
simMap = {} #<类目_文件名,距离> 后面需要将该HashMap按照value排序
for item in trainMap.items():
similarity = computeSim(testDic,item[1]) # 调用computeSim()
simMap[item[0]] = similarity sortedSimMap = sorted(simMap.iteritems(), key=itemgetter(1), reverse=True) #<类目_文件名,距离> 按照value排序 k = 20
cateSimMap = {} #<类,距离和>
for i in range(k):
cate = sortedSimMap[i][0].split('_')[0]
cateSimMap[cate] = cateSimMap.get(cate,0) + sortedSimMap[i][1] sortedCateSimMap = sorted(cateSimMap.iteritems(),key=itemgetter(1),reverse=True) return sortedCateSimMap[0][0] #################################################
## @param testDic 一维测试文档向量<<word, tfidf>>
## @param trainDic 一维训练文档向量<<word, tfidf
## @return 返回余弦相似度
def computeSim(testDic, trainDic):
testList = [] # 测试向量与训练向量共有的词在测试向量中的tfidf值
trainList = [] # # 测试向量与训练向量共有的词在训练向量中的tfidf值 for word, weight in testDic.items():
if trainDic.has_key(word):
testList.append(float(weight)) # float()将字符型数据转换成数值型数据,参与下面运算
trainList.append(float(trainDic[word])) testVect = mat(testList) # 列表转矩阵,便于下面向量相乘运算和使用Numpy模块的范式函数计算
trainVect = mat(trainList)
num = float(testVect * trainVect.T)
denom = linalg.norm(testVect) * linalg.norm(trainVect)
#print 'denom:%f' % denom
return float(num)/(1.0+float(denom))
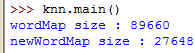
输出结果:

运行时遇到几种语法错误:
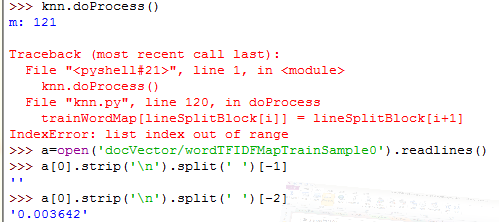
Error1:
split(' ')按空格分割后最后一位是空串,不检查分割后数组的最后一位很难发现,以致产生越界
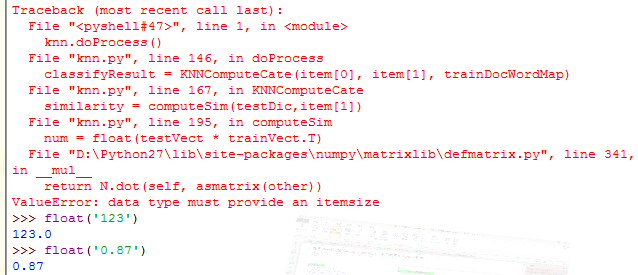
Error2:
因为导入数据用字符串运算strip切分后,返回的都是字符型数据,而string不能计算,需int(string) float(string)转换后参与计算,错误如下:
Error3:
sorted()对字典中每对<key, value>数据进行排序,返回的是包含tuple(key, value)的列表,之前不了解这一点,出现了index的错误:
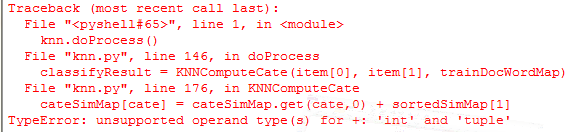
sorted()的返回形式:

基于KNN的newsgroup 18828文本分类器的Python实现的更多相关文章
- 基于Bayes和KNN的newsgroup 18828文本分类器的Python实现
向@yangliuy大牛学习NLP,这篇博客是数据挖掘-基于贝叶斯算法及KNN算法的newsgroup18828文本分类器的JAVA实现(上)的Python实现.入门为主,没有太多自己的东西. 1. ...
- 《机器学习实战》基于朴素贝叶斯分类算法构建文本分类器的Python实现
============================================================================================ <机器学 ...
- 股票价格涨跌预测—基于KNN分类器
code{white-space: pre;} pre:not([class]) { background-color: white; }if (window.hljs && docu ...
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于jquery的bootstrap在线文本编辑器插件Summernote
Summernote是一个基于jquery的bootstrap超级简单WYSIWYG在线编辑器.Summernote非常的轻量级,大小只有30KB,支持Safari,Chrome,Firefox.Op ...
- 基于SIFT+Kmeans+LDA的图片分类器的实现
原地址:http://www.cnblogs.com/freedomshe/archive/2012/04/24/2468747.html 题记:2012年4月1日回到家,南大计算机研究僧复试以后,等 ...
- Chinese-Text-Classification,用卷积神经网络基于 Tensorflow 实现的中文文本分类。
用卷积神经网络基于 Tensorflow 实现的中文文本分类 项目地址: https://github.com/fendouai/Chinese-Text-Classification 欢迎提问:ht ...
- 一个使用fasttext训练的新闻文本分类器/模型
fastext是什么? Facebook AI Research Lab 发布的一个用于快速进行文本分类和单词表示的库.优点是很快,可以进行分钟级训练,这意味着你可以在几分钟时间内就训练好一个分类模型 ...
随机推荐
- 用socket实现ping功能(记录)
/* 参考 http://bbs.csdn.net/topics/230001156 原文为win32版本 稍有改动,以适应mac与linux系统 */ #include <stdio.h> ...
- android SDK下载及中文API地址
中文API:http://wiki.eoeandroid.com/Android_API_Guides Android Dev Tools官网地址:www.androiddevtools.cn 收集整 ...
- Ubuntu无法识别显示器情况下,高分辨率的设置
安装ubuntu后,出现无法识别显示器,从而造成无法设置高分辨率. 界面显示似老年机般,5.3的视力+强迫症,臣妾的内心是十分拒绝的,捣鼓了半天终于搞定,这里记录下方法. (一)使用xrandr命令, ...
- Mindmanager安装
- a链接中套a链接
<a href="baidu.com"> <div> <div class="title">百度</div> & ...
- [转]EntityFramework状态变化AutoDetectChangesEnabled与SaveChanged参数说明
一.约定OnModelCreating 有一些限制需要注意,例如:1.表名不支持使用标签进行标注2.最小长度在 OnModelCreating 中不支持3.正则表达式在 OnModelCreating ...
- Format函数
Format是一个很常用,却又似乎很烦的方法,本人试图对这个方法的帮助进行一些翻译,让它有一个完整的概貌,以供大家查询之用: 首先看它的声明: function Format(const Format ...
- python类型转换、数值操作
类型转换 代码 1 函数 描述 2 int(x [,base ]) 将x转换为一个整数 3 long(x [,base ]) ...
- Listener实现单态登陆
MyEclipse中新建Web Project项目,完整目录如下: 需要的jar包为commons-logging-xxx.jar 1.singleton.jsp <%@ page langua ...
- python cmd下运行中文乱码 策略
如我运行一个脚本,执行后输出中文看不懂 然后呢在文件头加上 from __future__ import unicode_literals 注意:需要去掉所有字符串前的 u, 这样所有字符串均默认为u ...