XGBoost的推导和说明
一、简介
XGBoost是“Extreme Gradient Boosting”的缩写,其中“Gradient Boosting”一词在论文Greedy Function Approximation: A Gradient Boosting Machine中,由Friedman提出。XGBoost 也是基于这个原始模型改进的。
XGBoost提出后,不仅成为各大数据科学比赛的必杀武器,在实际工作中,XGBoost也在被各大公司广泛地使用。
二、树集成
XGBoost属于Boosting集成学习算法的一种,它以CART为基学习器,CART是一棵二叉树,每个叶子都有一个分数,如下图所示
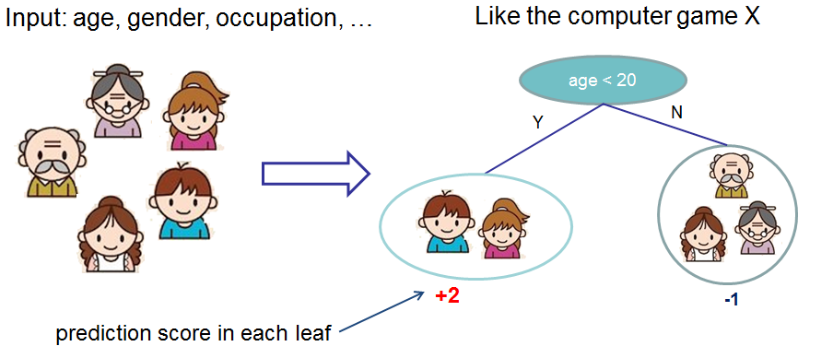
通常,一棵树过于简单,所以集成学习将多棵树进行结合,常常获得比单棵树优越的泛化性能。
XGBoost是加法模型,它会把多棵树的预测加到一起,预测得分是每棵树的预测分数之和,如下图所示
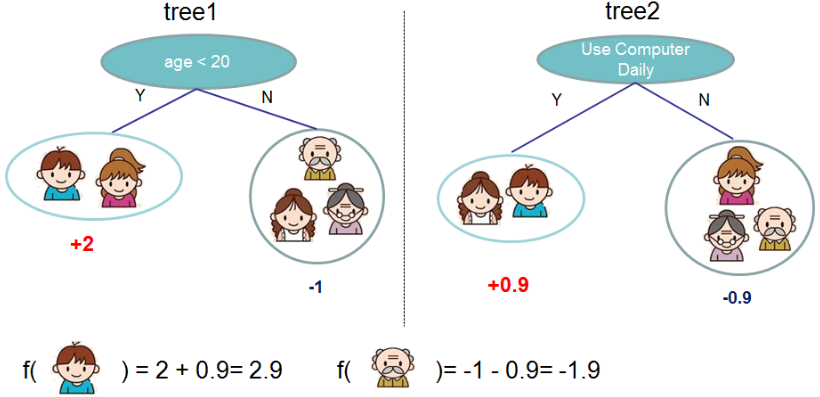
可以用下面的数学公式描述我们的模型
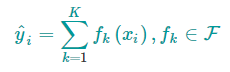
其中,$K$是树的数量,$f_{k}$是一棵树,$F$是所有可能的CART树集合。
三、树提升
3.1加性训练
XGBoost的目标函数为
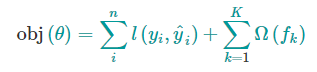
机器学习中的目标函数总是由两个部分组成:训练损失部分 和 正则化部分。
正如上式一样,前面是损失部分,后面是正则化部分,在XGBoost中将全部K棵树的复杂度进行求和,添加到目标函数中作为正则化项。
损失函数用来描述模型与训练数据的契合程度,正则化项用来描述模型的某些性质,比如模型的复杂度。
常见的损失函数有平方损失和log损失,表达式分别如下

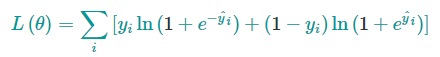
我们要学习的是那些函数$f$,每个函数都包含了树的结构和叶节点的分数。一次性地学习出所有的树是很棘手的,在XGBoost中采用“加性策略”(additive strategy)学习模型:保持学习到的结果不变,每次添加一棵新的树。 如果$y^{(t)}_{i}$表示第$t$步的预测值,则有:

那么我们每次都要留下哪棵树?一个很自然的想法就是选择可以优化我们目标函数的那棵树。前面 $t-1$ 棵树的模型复杂度是一个常数,我的目标函数可以写为
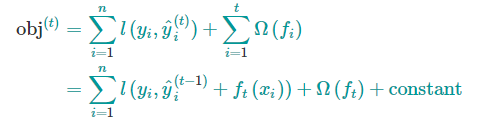
如果采用平方损失作为损失函数,可以变为下面的形式

使用平方损失函数有许多友好的地方,它具有一阶项(通常称为残差)和二次项。对于其他形式的损失函数,并不容易获得这么好的形式。一般情况下,我们可以用泰勒公式展开损失函数。
泰勒公式的二阶展开式如下
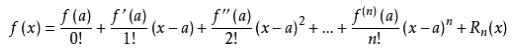 展开后的目标函数变为
展开后的目标函数变为
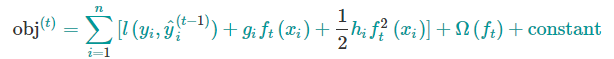
其中,$g$是一阶偏导,$h$是二阶偏导
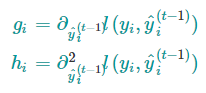
上面的目标函数中 $l(y,\hat{y})$是前t-1棵树带来的损失,是一个常数,下面把常数项去掉,第t步的目标函数就变成了
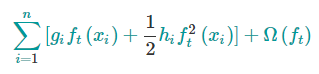 这个定义的损失函数只取决于$g$和$h$,这就是XGBoost支持自定义损失函数的方式,我们可以优化包括log损失在内的每一个损失函数,对损失函数求一阶和二阶偏导,得到g和h,然后带到上面的公式中就可以了。
这个定义的损失函数只取决于$g$和$h$,这就是XGBoost支持自定义损失函数的方式,我们可以优化包括log损失在内的每一个损失函数,对损失函数求一阶和二阶偏导,得到g和h,然后带到上面的公式中就可以了。
3.2模型复杂度
我们介绍了模型的训练,但还没定义模型复杂度$\Omega (f)$,我们先改进一棵树的定义为:
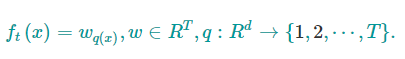 其中$w$是叶节点上的分数向量,$q$是将输入数据映射到某个叶节点的函数,$T$是叶节点的数量。我们定义XGBoost的复杂度为
其中$w$是叶节点上的分数向量,$q$是将输入数据映射到某个叶节点的函数,$T$是叶节点的数量。我们定义XGBoost的复杂度为
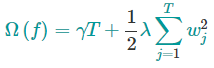 它由两部分组成:(1)叶结点的数量 和 (2)叶结点分数向量的L2范数;
它由两部分组成:(1)叶结点的数量 和 (2)叶结点分数向量的L2范数;
3.3结构分数
将上面得到式子带到前面得到的目标函数中,有
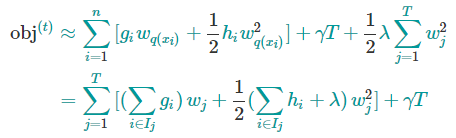 其中
其中
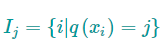
它存放着被映射到第$j$个叶子节点的数据 $x_{i}$的索引集合。
上面目标函数的第二行中,式子修改了求和符号的下标,由$i$=1变为 $i\in I_{j}$,这是因为同一叶节点上的数据有相同的分数。
我们可以进一步压缩这个目标函数:
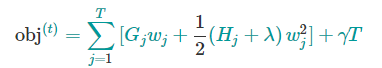
其中
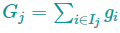
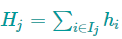
这个目标函数中,$w_{j}$彼此独立,而
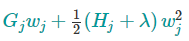
是二次式,我们可以用顶点公式找出最优解
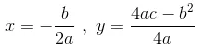
对于给定结构$q(x)$,使目标函数最小化的$w^{*}_{j}$的取值和最小化的目标函数为
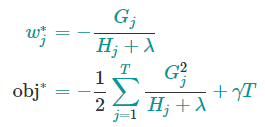
最后一个公式用于衡量树形结构的好坏,分数越小,模型的结构越好。
如果这听起来有点复杂,那么让我们看看下面图片,分数是如何计算的。
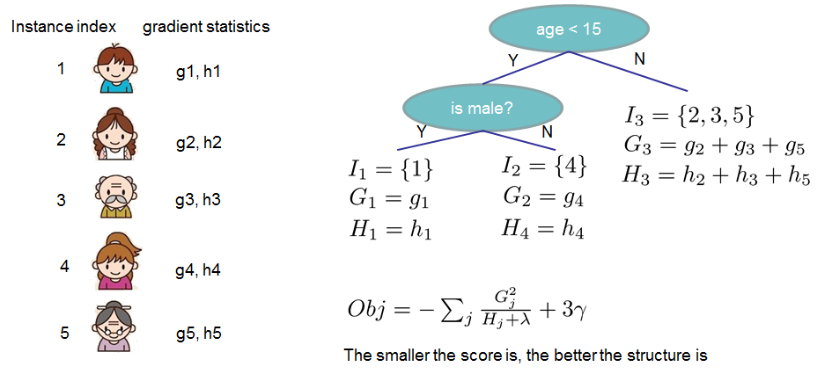
总的来说,对于给定的树结构,我们把 $g$ 和 $h$ 放到它们对应的叶节点中,对这些数据进行求和,然后使用公式计算树有多好。
这个分数类似于决策树中的不纯度,只是它还考虑了模型的复杂性。
3.4学习树结构
现在我们有了一种方法来衡量一棵树的质量,理想情况下,我们将枚举所有可能的树并选择最佳的树。
实际上这是棘手的,所以我们将尝试每次优化树的一层。具体来说,我们尝试将一个叶节点分成叶节点,其分数增益为
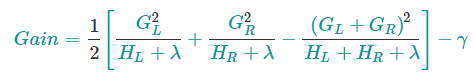
公式从左到右可分解为4个部分
- 1)新左叶上的分数
- 2)新右叶上的分数
- 3)原始叶上的分数
- 4)附加叶上的正则化。
如果增益小于$\gamma$,说明添加一个节点没有带来模型性能的提升,容易导致过拟合,我们最好不要添加该分支。这正是基于树的模型中的剪枝技术。
对于实值数据,我们通常希望找到最佳分割点。为了有效地做到这一点,我们将所有样本排好序,如下图所示。
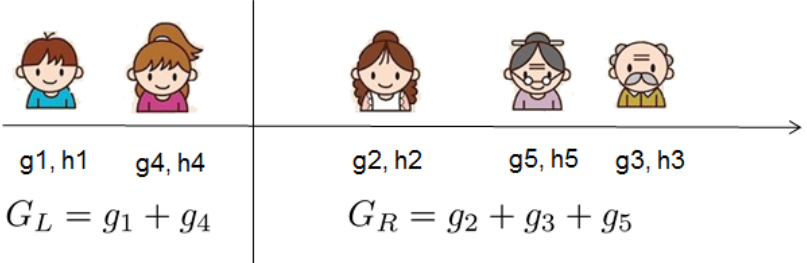 然后从左到右的扫描,就足以计算所有可能的分割方案的结构得分,我们可以有效地找到最佳的拆分。
然后从左到右的扫描,就足以计算所有可能的分割方案的结构得分,我们可以有效地找到最佳的拆分。
参考文章
https://xgboost.readthedocs.io/en/latest/tutorials/model.html
https://blog.csdn.net/weixin_30443813/article/details/96532052
XGBoost的推导和说明的更多相关文章
- 1.XGBOOST算法推导
最近因为实习的缘故,所以开始复习各种算法推导~~~就先拿这个xgboost练练手吧. (参考原作者ppt 链接:https://pan.baidu.com/s/1MN2eR-4BMY-jA5SIm6W ...
- XGBoost 完整推导过程
参考: 陈天奇-"XGBoost: A Scalable Tree Boosting System" Paper地址: <https://arxiv.org/abs/1603 ...
- 机器学习相关知识整理系列之三:Boosting算法原理,GBDT&XGBoost
1. Boosting算法基本思路 提升方法思路:对于一个复杂的问题,将多个专家的判断进行适当的综合所得出的判断,要比任何一个专家单独判断好.每一步产生一个弱预测模型(如决策树),并加权累加到总模型中 ...
- Xgboost集成算法
集成算法思想: Xgboost基本原理: Xboost中是一个树(函数)接着一个树(函数)往里加,每加一个树都希望整体表达效果更好一些,即:目标函数逐步减小. 每加入一个函数,使目标函数逐渐减小,整体 ...
- XgBoost推导与总结
一 .机器学习算法中GBDT和XGBOOST的区别有哪些?(转自知乎https://www.zhihu.com/question/41354392/answer/98658997) xgboost相比 ...
- 跟我学算法-xgboost(集成算法)基本原理推导
1.构造损失函数的目标函数 2.对目标函数进行泰勒展开 3.把样本遍历转换成叶子节点遍历,合并正则化惩罚项 4.求wj进行求导,使得当目标函数等于0时的wj的值 5.将求解得到的wj反导入方程中,解得 ...
- 【小白学AI】XGBoost 推导详解与牛顿法
文章转自公众号[机器学习炼丹术],关注回复"炼丹"即可获得海量免费学习资料哦! 目录 1 作者前言 2 树模型概述 3 XGB vs GBDT 3.1 区别1:自带正则项 3.2 ...
- 【小白学AI】XGBoost推导详解与牛顿法
文章来自微信公众号:[机器学习炼丹术] 目录 1 作者前言 2 树模型概述 3 XGB vs GBDT 3.1 区别1:自带正则项 3.2 区别2:有二阶导数信息 3.3 区别3:列抽样 4 XGB为 ...
- 机器学习 - 算法 - Xgboost 数学原理推导
工作原理 基于集成算法的多个树累加, 可以理解为是弱分类器的提升模型 公式表达 基本公式 目标函数 目标函数这里加入了损失函数计算 这里的公式是用的均方误差方式来计算 最优函数解 要对所有的样本的损失 ...
随机推荐
- 进程池和multiprocess.Pool模块
一.为什么要有进程池 首先,创建进程需要消耗时间,销毁进程也需要时间.其次,即使开启了成千上万的进程,操作系统也不能让它们同时执行,这样反而会影响程序的效率.因此我们不能无限制的根据任务开启或者结束进 ...
- shuoj 1 + 2 = 3? (二分+数位dp)
题目传送门 1 + 2 = 3? 发布时间: 2018年4月15日 22:46 最后更新: 2018年4月15日 23:25 时间限制: 1000ms 内存限制: 128M 描述 埃森哲是 ...
- python学习第十三天元组创建和操作方法
有人问,有了列表,为什么还要有元组呢,到底元组是什么,元组是不可变的有序的列表,一旦创建不能改变,那些地方用到元组呢,小编知道可以应用到数据库连接. 1,元组的创建 n1 = () 元组用的是小括号 ...
- python学习第三天格式化输出%s %d
编程语言为什么要格式化输出吗,一般print()就够了,有些复杂的格式输出比较麻烦,用格式化输出更加高效, info=""" ---------------------- ...
- linux上执行jmeter脚本
1.linux上安装jmeter 将windows上的zip包直接放到linux上 进入bin目录,chmod 777 jmeter 修改环境变量: 1 2 3 4 # vim /etc/profil ...
- C#split的使用方式
一,在msdn中我们能看到一下几种使用 二,我们先看看经常使用的, 我们先定义一个数组 string test = "1,2,,3,4,5,6,7"; 第一种,结果大家都熟悉,就不 ...
- BUUCTF--xor
测试文件:https://buuoj.cn/files/caa0fdad8f67a3115e11dc722bb9bba7/7ea34089-68ff-4bb7-8e96-92094285dfe9.zi ...
- VS Code的使用
之前一直使用的是WebStorm来学习web前端开发,最近开始使用VSCode,很多方面和WebStorm不一样,需要一段时间适应,以下是我初次使用VSCode进行web前端开发学习所遇到的一些问题以 ...
- 有关css的兼容问题
兼容性 1 页面在不同浏览器中可能显示不同 在IE6下 子级的宽度会撑开父级设置好的宽度 温馨提示:和模型的计算一定要精确,IE浏览器可能显示不同 兼容性 2 在IE6中,元素浮 ...
- wxstring与其他类型转换
wxstring与其他类型转换 1.1 int to wxString: wxString str = wxString::Format(wxT("%i"),myInt); 1.2 ...