实例学习——爬取豆瓣网TOP250数据
开发环境:(Windows)eclipse+pydev
网址:https://book.douban.com/top250?start=0
from lxml import etree #解析提取数据
import requests #请求网页获取网页数据
import csv #存储数据 fp = open('D:\Pyproject\douban.csv','wt',newline='',encoding='UTF-8') #创建csv文件
writer = csv.writer(fp)
writer.writerow(('name','url','author','publisher','date','price','rate','comment')) #写入表头信息,即第一行 urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)] #构建urls headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'} for url in urls: #循环url,先抓大,后抓小(!!!重要,下面详解)
html = requests.get(url,headers = headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//tr[@class="item"]')
for info in infos:
name = info.xpath('td/div/a/@title')
url = info.xpath('td/div/a/@href')
book_infos = info.xpath('td/p/text()')[0]
author = book_infos.split('/')[0]
publisher =book_infos.split('/')[-3]
date = book_infos.split('/')[-2]
price = book_infos.split('/')[-1]
rate = info.xpath('td/div/span[2]/text()')
comments = info.xpath('td/p/span/text()')
comment = comments[0] if len(comments) != 0 else ''
writer.writerow((name,url,author,publisher,date,price,rate,comment)) #写入数据
fp.close() #关闭csv文件,勿忘
成果展示:
#乱码错误,用记事本打开,另存为UTF-8文件可解决

本例主要学习csv库的使用与数据批量抓取方式(即先抓大,后抓小,寻找循环点)
csv库创建csv文件及写入数据方式:
import csv
fp = ('C://Users/LP/Desktop/text.csv','w+')
writer = csv.writer(fp)
writer.writerow('id','name')
writer.writerow('','OCT')
writer.writerow('','NOV') #写入行
fp.close()
数据批量抓取:
通过类似于BeautifulSoup中的selector()删除谓语部分不可行,思路应为“先抓大,后抓小,寻找循环点”(手写,非copy xpath)
打开chrome浏览器进行“检查”,通过“三角形符号”折叠元素,找到完整的信息标签,如下图
(selector()获取数据集中最大区域,遵循路径表达式,第一个字符串前置)
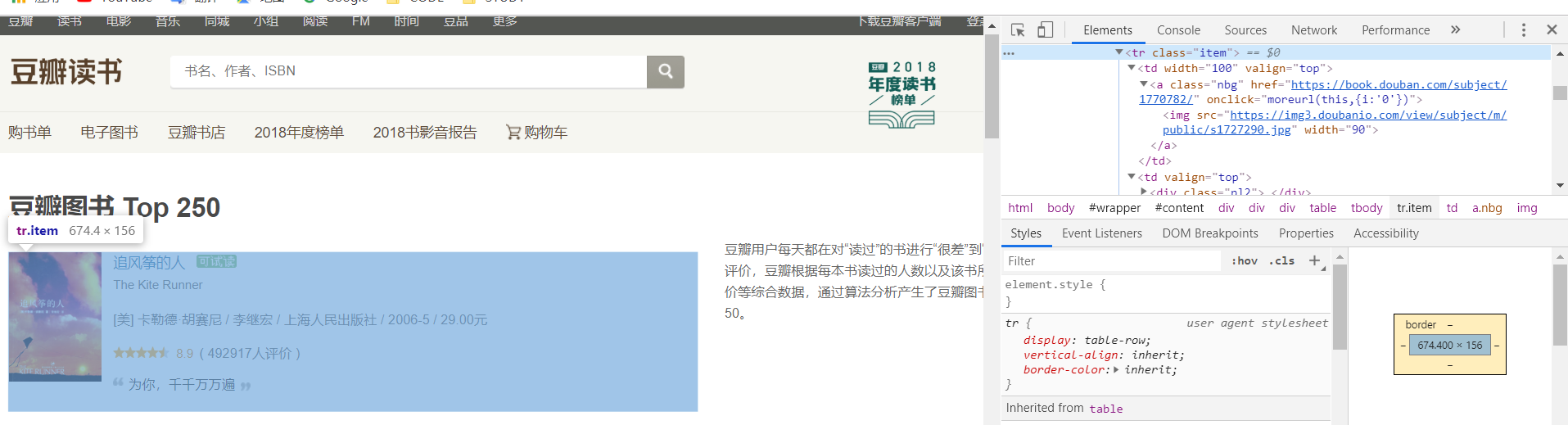
后每个单独的数据(名字,价格等)另取:
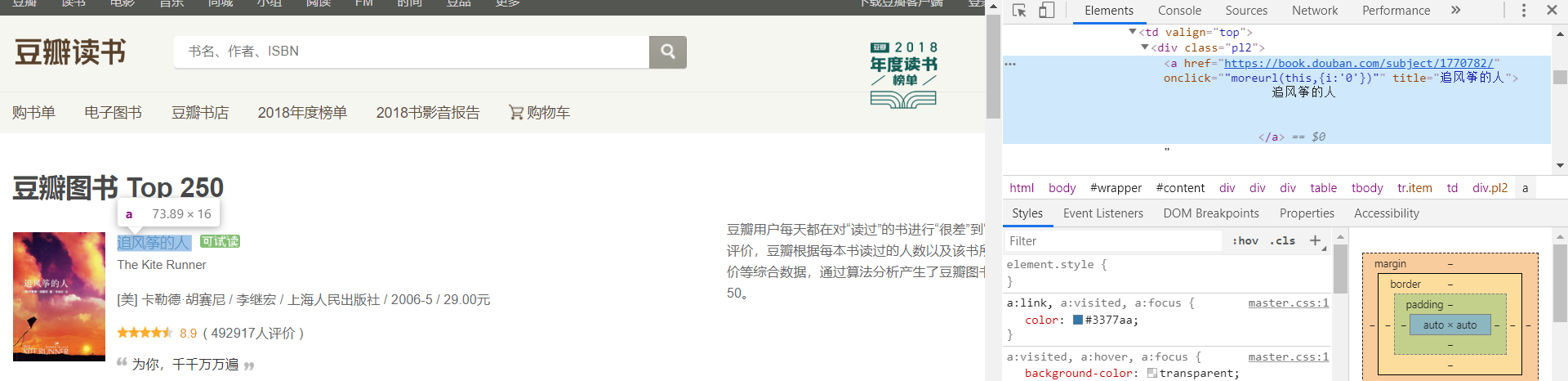
如 name,归属:<a>—><div>—><td>
所以:(当归属指向不变时,取小范围的)
name = info.xpath('td/div/a/@title')
实例学习——爬取豆瓣网TOP250数据的更多相关文章
- 实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB 豆瓣TOP网址:传送门 一.连接数据库 打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,d ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
随机推荐
- 对MySQL binlog日志解析,统计每张表的DML次数
想要获取每天数据库每张表的DML的次数,统计热度表,可以使用该脚本 # coding:utf-8 # 解析binlog,统计热度表,表的DML个数 import sys import os # mys ...
- Java多级文件夹上传
javaweb上传文件 上传文件的jsp中的部分 上传文件同样可以使用form表单向后端发请求,也可以使用 ajax向后端发请求 1.通过form表单向后端发送请求 <form id=" ...
- luogu 4366 [Code+#4]最短路 Dijkstra + 位运算 + 思维
这个题思路十分巧妙,感觉很多题都有类似的套路. 我们发现异或操作其实就是将一个数的二进制的若干个 $0$ 变成 $1$,或者一些 $1$ 变成 $0$. 而每次按照某种顺序一位一位地异或也可以起到同时 ...
- UVa 11235 Frequent values (RMQ && 区间出现最多次的数的次数)
题意 : 给出一个长度为 n 的不降序序列,并且给出 q 个形如(L, R)的问询,问你这个区间出现的最多次的数的次数. 分析 : 很自然的想到将区间“缩小”,例如1 1 2 3 3 3就可以变成2 ...
- 2018百度之星初赛A轮 度度熊拼三角
#include<bits/stdc++.h> using namespace std; int n; int a[1005]; int main() { int ans; ...
- cocos2d 15款游戏源码
https://blog.csdn.net/jailman/article/details/78678972
- [BZOJ3456]城市规划:DP+NTT+多项式求逆
写在前面的话 昨天听吕老板讲课,数数题感觉十分的神仙. 于是,ErkkiErkko这个小蒟蒻也要去学数数题了. 分析 Miskcoo orz 带标号无向连通图计数. \(f(x)\)表示\(x\)个点 ...
- HashMap原理及简单实现
public class MyHashMap<K, V> { private class Entry<K, V> { int hash; K key; V value; Ent ...
- 第四周总结 & 实验报告(二)
第四周课程总结 一.String类 1.实例化 (1)直接赋值 public class Xxxx{ public static void main(String args[]){ String a ...
- JSP 不能解析EL表达式的解决办法
原文地址:http://www.jb51.net/article/30791.htm 原因是:在默认情况下,Servlet 2.4 / JSP 2.0支持 EL 表达式. 解决的办法有两种: 1.修改 ...