实例学习——爬取豆瓣网TOP250数据
开发环境:(Windows)eclipse+pydev
网址:https://book.douban.com/top250?start=0
from lxml import etree #解析提取数据
import requests #请求网页获取网页数据
import csv #存储数据 fp = open('D:\Pyproject\douban.csv','wt',newline='',encoding='UTF-8') #创建csv文件
writer = csv.writer(fp)
writer.writerow(('name','url','author','publisher','date','price','rate','comment')) #写入表头信息,即第一行 urls = ['https://book.douban.com/top250?start={}'.format(str(i)) for i in range(0,250,25)] #构建urls headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'} for url in urls: #循环url,先抓大,后抓小(!!!重要,下面详解)
html = requests.get(url,headers = headers)
selector = etree.HTML(html.text)
infos = selector.xpath('//tr[@class="item"]')
for info in infos:
name = info.xpath('td/div/a/@title')
url = info.xpath('td/div/a/@href')
book_infos = info.xpath('td/p/text()')[0]
author = book_infos.split('/')[0]
publisher =book_infos.split('/')[-3]
date = book_infos.split('/')[-2]
price = book_infos.split('/')[-1]
rate = info.xpath('td/div/span[2]/text()')
comments = info.xpath('td/p/span/text()')
comment = comments[0] if len(comments) != 0 else ''
writer.writerow((name,url,author,publisher,date,price,rate,comment)) #写入数据
fp.close() #关闭csv文件,勿忘
成果展示:
#乱码错误,用记事本打开,另存为UTF-8文件可解决

本例主要学习csv库的使用与数据批量抓取方式(即先抓大,后抓小,寻找循环点)
csv库创建csv文件及写入数据方式:
import csv
fp = ('C://Users/LP/Desktop/text.csv','w+')
writer = csv.writer(fp)
writer.writerow('id','name')
writer.writerow('','OCT')
writer.writerow('','NOV') #写入行
fp.close()
数据批量抓取:
通过类似于BeautifulSoup中的selector()删除谓语部分不可行,思路应为“先抓大,后抓小,寻找循环点”(手写,非copy xpath)
打开chrome浏览器进行“检查”,通过“三角形符号”折叠元素,找到完整的信息标签,如下图
(selector()获取数据集中最大区域,遵循路径表达式,第一个字符串前置)
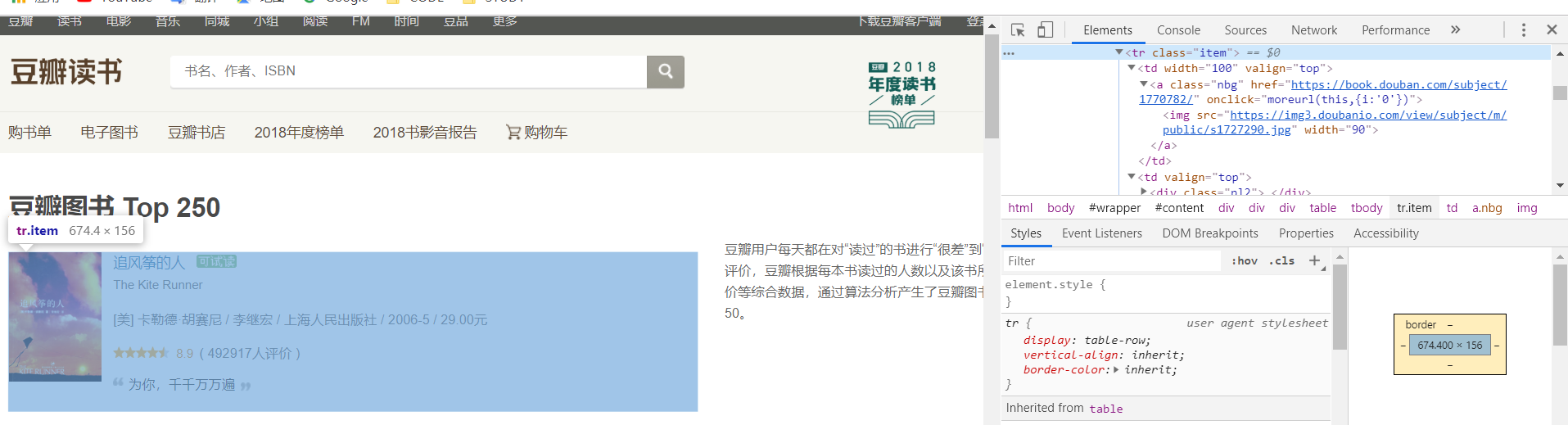
后每个单独的数据(名字,价格等)另取:
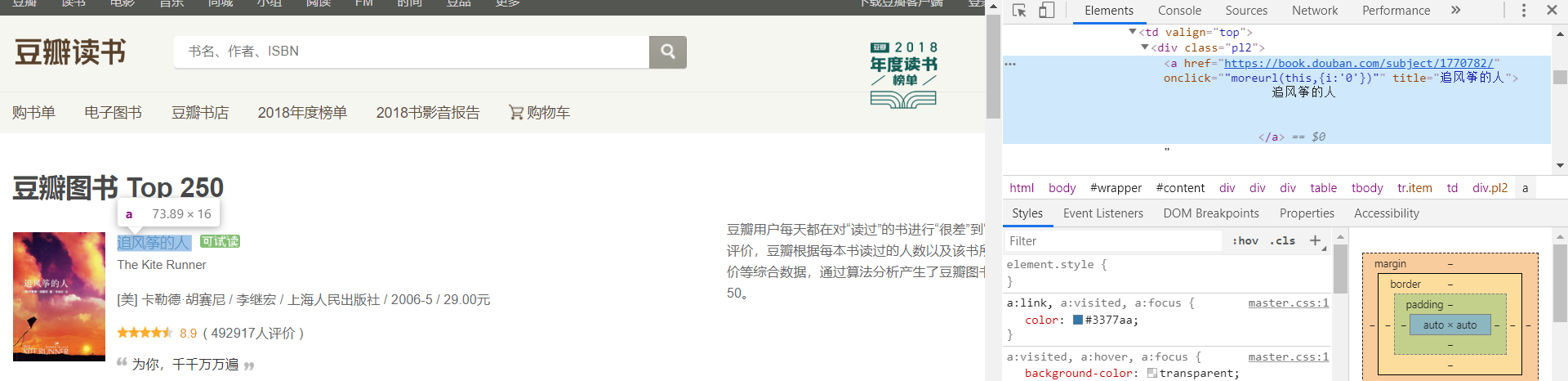
如 name,归属:<a>—><div>—><td>
所以:(当归属指向不变时,取小范围的)
name = info.xpath('td/div/a/@title')
实例学习——爬取豆瓣网TOP250数据的更多相关文章
- 实例学习——爬取豆瓣音乐TOP250数据
开发环境:(Windows)eclipse+pydev+MongoDB 豆瓣TOP网址:传送门 一.连接数据库 打开MongoDBx下载路径,新建名为data的文件夹,在此新建名为db的文件夹,d ...
- 爬取豆瓣网图书TOP250的信息
爬取豆瓣网图书TOP250的信息,需要爬取的信息包括:书名.书本的链接.作者.出版社和出版时间.书本的价格.评分和评价,并把爬取到的数据存储到本地文件中. 参考网址:https://book.doub ...
- python2.7爬取豆瓣电影top250并写入到TXT,Excel,MySQL数据库
python2.7爬取豆瓣电影top250并分别写入到TXT,Excel,MySQL数据库 1.任务 爬取豆瓣电影top250 以txt文件保存 以Excel文档保存 将数据录入数据库 2.分析 电影 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
- 【转】爬取豆瓣电影top250提取电影分类进行数据分析
一.爬取网页,获取需要内容 我们今天要爬取的是豆瓣电影top250页面如下所示: 我们需要的是里面的电影分类,通过查看源代码观察可以分析出我们需要的东西.直接进入主题吧! 知道我们需要的内容在哪里了, ...
- Scrapy中用xpath/css爬取豆瓣电影Top250:解决403HTTP status code is not handled or not allowed
好吧,我又开始折腾豆瓣电影top250了,只是想试试各种方法,看看哪一种的方法效率是最好的,一直进行到这一步才知道 scrapy的强大,尤其是和selector结合之后,速度飞起.... 下面我就采用 ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
随机推荐
- 详解GSM的基带跳频和射频跳频
跳频技术源于军事通信,目的是为了获得较好的保密性和抗干扰能力.跳频分为快速和慢速两种,GSM中的跳频属于慢跳频. 跳频方式从时域概念上分为帧跳频和时隙跳频,从载频实现方式上分为射频跳频和基带跳频. 帧 ...
- PHP基础教程 php 网络上关于设计模式一些总结
1.单例模式 单例模式顾名思义,就是只有一个实例.作为对象的创建模式,单例模式确保某一个类只有一个实例,而且自行实例化并向整个系统提供这个实例. 单例模式的要点有三个: 一是某个类只能有一个实例; 二 ...
- 中南林业大学校赛 I 背包问题 ( 折半枚举 || 01背包递归写法 )
题目链接 题意 : 中文题 分析 : 价值和重量都太过于大,所以采用折半枚举的方法,详细可以看挑战的超大背包问题 由于 n <= 30 那么可以不必直接记录状态来优化,面对每个用例 直接采用递 ...
- (WCF) There is already a listener on IP endpoint 0.0.0.0:9999.
有個nettcpbinding, service host總是不能起來,出現如題錯誤. 查了下,同樣的程序并沒有在進程裏面,但是看起來好像有其他的程序在占用這個Port C:\Program File ...
- vue 渲染是出现 Do not use built-in or reserved HTML elements as component id 的警告
情况1.是因为组件命名和引入不一致造成的. 命名组件(nav) export default { name: 'nav', data () { return { } } 引入组件(Navigation ...
- [BZOJ4695]最假女选手:segment tree beats!
分析 segment tree beats!模板题. 看了gxz的博客突然发现自己写的mxbt和mnbt两个标记没用诶. 代码 #include <bits/stdc++.h> #defi ...
- enum简单使用
前台传入weightCode :1/2/3/4,获取不同的区间0~10 10~50 50~100 100~999999 0~999999 public void setWeight(){ this.m ...
- tomcat+nginx负载均衡
一. 工具 nginx-1.8.0 apache-tomcat-6.0.33 二. 目标 实现高性能负载均衡的Tomcat集群: 三. 步骤 1.首先下载Nginx,要下载稳定 ...
- Masonry 布局 scrollView
原理 scrollView的高度(纵向滑动时)时靠内部的子控件撑起来的.我们直接给ScrollView布局会发现失败.用层级检查器发现,ScrollVIiw的高度有问题,我们可以选择添加一个UIVie ...
- mysql-8.0解压缩版安装配置完整过程
https://www.cnblogs.com/xiongzaiqiren/p/8970203.html