mysql之sql性能调优
sql调优大致分为两步:1 如何定位慢查询 2 如何优化sql语句。
一:定位慢查询
-- 显示到mysql数据库的连接数
-- show status like 'connections'; -- 显示慢查询次数
show status like 'slow_queries'; -- 查看慢查询阈值 (默认是10秒)
show variables like 'long_query_time'; -- 修改慢查询时间 (但是重启mysql之后,long_query_time依然是my.ini中的值)
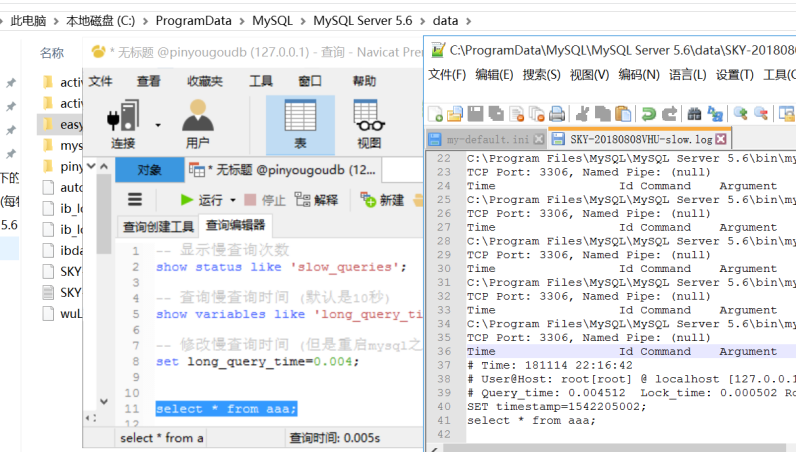
set long_query_time=1;
-- 此时再次查看mysql慢查询阈值就是刚设置的值了,一般sql执行时间超过1s,就是慢查询了。
如图:我们将慢查询时间设置为0.004s, 而select * from aaa; 执行花了0.005s,那么它就是慢查询,mysql会将慢查询语句直接写入日志文件中,我们就可以根据日志快速定位项目中的慢查询语句。
二:优化案例
查询只有命中索引才能高效,我们可以通过 explain 执行计划 来检查我们的sql语句是否命中了索引。
1:创建表, id为主键索引
CREATE TABLE ccc (
id int (5),
name varchar(50),
age int (3),
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8; 2:设置普通索引 create index 索引名 on 表 (列1,列名2);
create index ccc_index on ccc(name); 3:查入数据
insert into ccc VALUES (1, '吴磊', 23);
insert into ccc VALUES (2, '杰伦', 22);
insert into ccc VALUES (3, '二狗', 24);
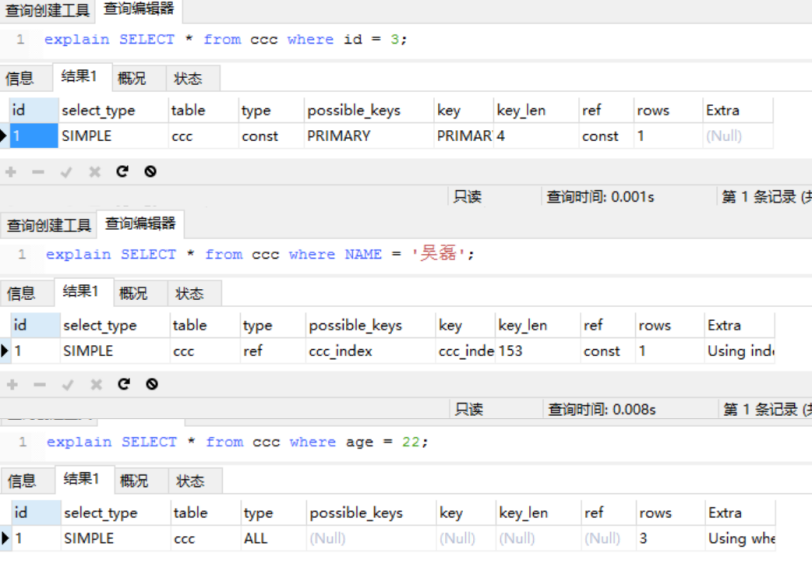
type:性能从好到差为 const、eq_reg、ref、range、indexhe , 为 ALL 则表示没有命中索引
sql调优总结:
1. like 模糊查询:不要以%开头,它会丢失索引
explain select * from ccc where name like "吴磊" 命中索引
explain select * from ccc where name like "吴磊%" 命中索引
explain select * from ccc where name like "%吴磊" 丢失索引
explain select * from ccc where name like "%吴磊%" 丢失索引
2. null判断用: is 代替 =
explain select * from ccc where name is null 命中索引
explain select * from ccc where name = null 丢失索引
3. select * from user where age >100比select * from user where age >= 101 效率要高;前者只查了一次,后者查了2次
4. group by 分组:默认分组后,还会排序,可能会降低速度,
在group by 后面增加 order by null 就可以防止排序。 select * from ccc group by age order by null
5. 关连查询代替子查询,因为子查询会将查出来的结果集在内存中创建处一张临时表。
6. 关联查询尽量大表在前小标在后,mysql是以右边的表为驱动表。 from table(大), table2(小)
7. 尽量保证where的过滤条件中,哪个条件过滤的数据多久放在语句前面
8. 尽量 用0代替null 用exits代替in 交集代替!= ..........
9. 避免使用or, 他会丢失索引。
10. 离散程度大的条件放前面:比如 where a = 12 and b = 3 ,如果b有100条数据 a只有10条,那么b放在前面。
mysql之sql性能调优的更多相关文章
- mysql监控、性能调优及三范式理解
原文:mysql监控.性能调优及三范式理解 1监控 工具:sp on mysql sp系列可监控各种数据库 2调优 2.1 DB层操作与调优 2.1.1.开启慢查询 在My.cnf文件中添加如 ...
- MySQL插入数据性能调优
插入数据性能调优总结: 1.SQL插入语句调优 2.如果是InnoDB引擎的话,尝试开启事务,批量提交 3.调整MySQl数据库配置 参考: 百度空间 - MySQL插入数据性能调优 CSDN ...
- spark2.+ sql 性能调优
1.在内存中缓存数据 性能调优主要是将数据放入内存中操作,spark缓存注册表的方法 版本 缓存 释放缓存 spark2.+ spark.catalog.cacheTable("tableN ...
- mysql 索引优化 性能调优 锁
1 检查mysql 是否安装 rpm -qa|grep -i mysql 2 ntsysv 查看和设置开机启动列表 3 mysql 在 centos 上默认 的数据目录是 /var/lib/mysql ...
- SQL性能调优基础教材
一.数据库体系结构 1. Oracle数据库和实例 数据库:物理操作系统文件或磁盘的集合. 实例:一组Oracle后台进程/线程以及一个共享内存区,这些内存由同一个计算机上运行的线程/进程 ...
- OCP读书笔记(15) - 管理SQL性能调优
SQL Tuning Advisor(STA): 使用oracle提供的程序包进行sql优化 SQL> conn scott/tiger SQL), name )); SQL> inser ...
- 学会使用MySQL的Explain执行计划,SQL性能调优从此不再困难
上篇文章讲了MySQL架构体系,了解到MySQL Server端的优化器可以生成Explain执行计划,而执行计划可以帮助我们分析SQL语句性能瓶颈,优化SQL查询逻辑,今天就一块学习Explain执 ...
- mysql my.ini 性能调优
MYSQL服务器my.cnf配置文档详解 硬件:内存16G [client] port = 3306 socket = /data/3306/mysql.sock [mysql] no-auto-re ...
- SQL 性能调优日常积累
我们要做到不但会写SQL,还要做到写出性能优良的SQL,以下为笔者学习.摘录.并汇总部分资料与大家分享! (1)选择最有效率的表名顺序(只在基于规则的优化器中有效) ORACLE 的解析器按照从右到左 ...
随机推荐
- Redis实战(十七)Redis各个版本新特性
序言 Redis1.0 Redis2.0 Redis3.0 Redis4.0 Redis5.0 资料
- #420 Div2 Problem B Okabe and Banana Trees (math && 暴力枚举)
题目链接 :http://codeforces.com/contest/821/problem/B 题意 :给出 m 和 b 表示在坐标轴上的一条直线 要求你在这条直线和x.y轴围成的区域中找出一个 ...
- POJ 3180 牛围着池塘跳舞 强连通分量裸题
题意:一群牛被有向的绳子拴起来,如果有一些牛(>=2)的绳子是同向的,他们就能跳跃.求能够跳跃的组数. #include <iostream> #include <cstdio ...
- Vue(核心思想)
1.Es6语法普及 let和var的区别: var:定义变量时,在全局范围内都有效;所以在变量没有声明之前就能使用,值为undefined, 称为变量提升; let:声明的变量一定要在声明后使用,而且 ...
- D2. Equalizing by Division (hard version)
D2. Equalizing by Division (hard version) 涉及下标运算一定要注意下标是否越界!!! 思路,暴力判断以每个数字为到达态最小花费 #include<bits ...
- 密度聚类 DBSCAN
刘建平:DBSCAN密度聚类算法 https://www.cnblogs.com/pinard/p/6208966.html API 的说明: https://www.jianshu.com/p/b0 ...
- Word2Vec模型参数 详解
用gensim函数库训练Word2Vec模型有很多配置参数.这里对gensim文档的Word2Vec函数的参数说明进行翻译,以便不时之需. class gensim.models.word2vec.W ...
- 3、electron打包生成exe文件
打包方式1:DOS窗口命令打包 DOS 下,输入 npm install electron-packager -g全局安装我们的打包神器: cnpm install electron-packager ...
- hibernate+spring mvc,解决hibernate对象懒加载,json序列化失败
在使用spring MVC时,@ResponseBody 注解的方法返回一个有懒加载对象的时候出现了异常,以登录为例: @RequestMapping("login") @Resp ...
- 阶段3 1.Mybatis_05.使用Mybatis完成CRUD_5 Mybatis的CRUD-查询返回一行一列和占位符分析
聚合函数 模糊查询的另外一种写法 如果用户这种方式里面的value是固定的 因为在源码分析中,绑定的就是固定的value值 所以这里传参数的 没必要在用百分号了 删掉后 xml里面应该用这种方式来注释 ...