kaggle-泰坦尼克号Titanic-1
大家都熟悉的『Jack and Rose』的故事,豪华游艇倒了,大家都惊恐逃生,可是救生艇的数量有限,无法人人都有,副船长发话了『lady and kid first!』,所以是否获救其实并非随机,而是基于一些背景有rank先后的。
训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。
对,这是一个二分类问题,很多分类算法都可以解决。
看看数据长啥样
import pandas as pd
import numpy as np
from pandas import Series,DataFrame data_train = pd.read_csv("Train.csv")
print(data_train.columns)
结果
Index([u'PassengerId', u'Survived', u'Pclass', u'Name', u'Sex', u'Age',u'SibSp', u'Parch', u'Ticket', u'Fare', u'Cabin', u'Embarked'],
dtype='object')
我们看大概有以下这些字段
PassengerId => 乘客ID
Pclass => 乘客等级(1/2/3等舱位)
Name => 乘客姓名
Sex => 性别
Age => 年龄
SibSp => 堂兄弟/妹个数
Parch => 父母与小孩个数
Ticket => 船票信息
Fare => 票价
Cabin => 客舱
Embarked => 登船港口
看一下数据的详细信息
print(data_train.info())
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB
上面的数据说啥了?它告诉我们,训练数据中总共有891名乘客,但是很不幸,我们有些属性的数据不全,比如说:
- Age(年龄)属性只有714名乘客有记录
- Cabin(客舱)更是只有204名乘客是已知的
似乎信息略少啊,想再瞄一眼具体数据数值情况呢?恩,我们用下列的方法,得到数值型数据的一些分布(因为有些属性,比如姓名,是文本型;而另外一些属性,比如登船港口,是类目型。这些我们用下面的函数是看不到的)
下面再看看每个/多个 属性和最后的Survived之间有着什么样的关系
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontManager, FontProperties
def getChineseFont():
return FontProperties(fname='/System/Library/Fonts/PingFang.ttc') data_train = pd.read_csv("train.csv")
#print(data_train.info())
#print(data_train.describe()) fig = plt.figure()
fig.set(alpha=0.2)#设定图表颜色alpha参数 plt.subplot2grid((2,3),(0,0)) #在一张大图里分列几个小图
data_train.Survived.value_counts().plot(kind='bar') #存活和不存活的条形图
plt.title(u"获救情况(1为获救)",fontproperties=getChineseFont())
plt.ylabel(u"人数",fontproperties=getChineseFont()) plt.subplot2grid((2,3),(0,1))
data_train.Pclass.value_counts().plot(kind='bar')
plt.title(u"乘客等级分布",fontproperties=getChineseFont())
plt.ylabel(u"人数",fontproperties=getChineseFont()) plt.subplot2grid((2,3),(0,2))
plt.scatter(data_train.Survived,data_train.Age)
plt.title(u"按年龄看获救分布(1为获救)",fontproperties=getChineseFont())
plt.ylabel(u"年龄",fontproperties=getChineseFont())
plt.grid(b=True,which='major',axis='y') #格式化图表的网格线样式 plt.subplot2grid((2,3),(1,0),colspan=2)
data_train.Age[data_train.Pclass == 1].plot(kind='kde')
data_train.Age[data_train.Pclass == 2].plot(kind='kde')
data_train.Age[data_train.Pclass == 3].plot(kind='kde')
plt.title(u"各等级乘客年龄分布",fontproperties=getChineseFont())
plt.xlabel(u"年龄",fontproperties=getChineseFont())
plt.ylabel(u"密度",fontproperties=getChineseFont())
plt.legend(("level1","level2","level3"),loc='best') plt.subplot2grid((2,3),(1,2))
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"各登船口岸上船人数",fontproperties=getChineseFont())
plt.ylabel(u"人数",fontproperties=getChineseFont()) plt.show()
得到了像下面这样一张图:
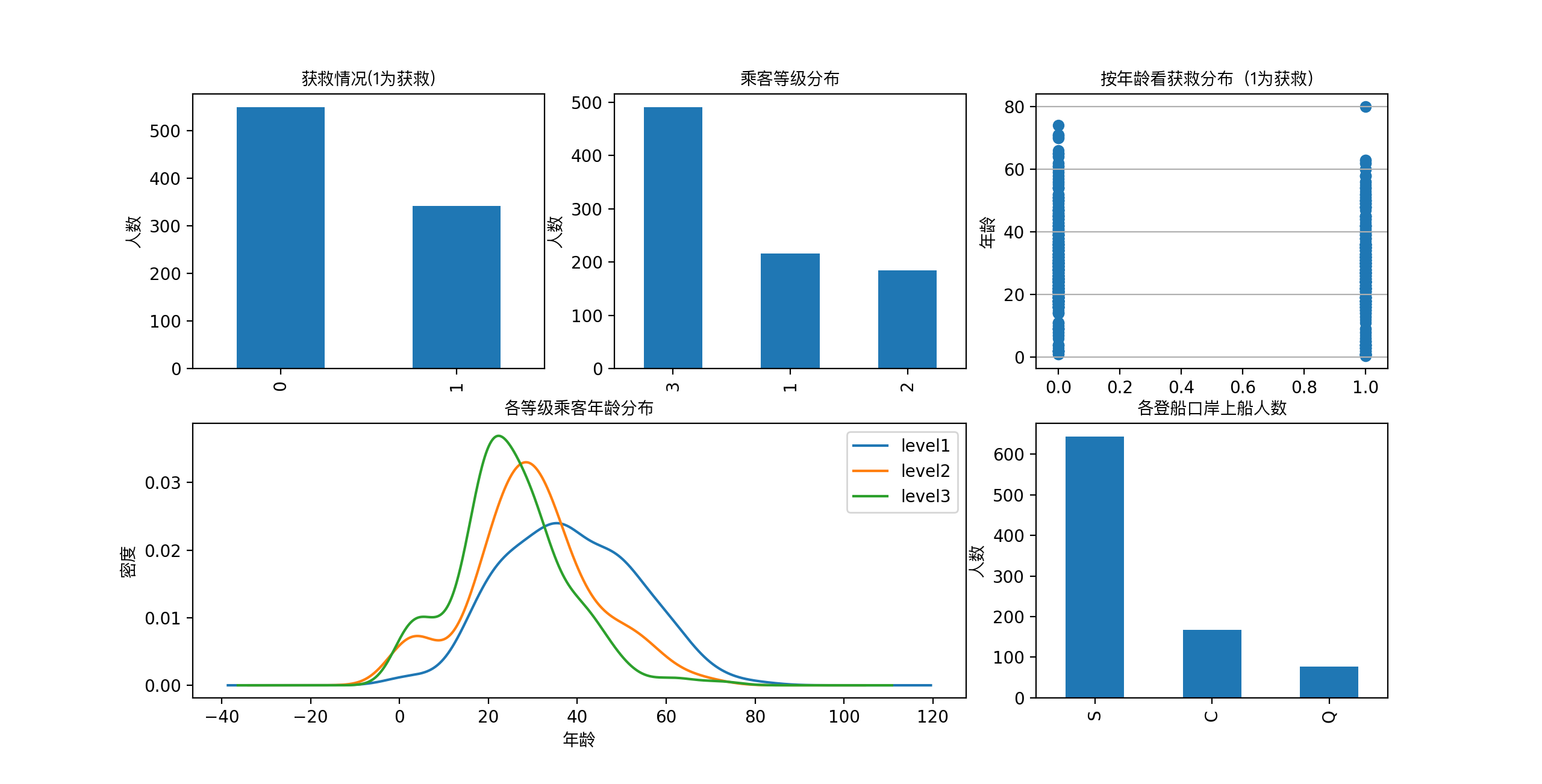
在图上可以看出来:
- 被救的人300多点,不到半数;
- 3等舱乘客灰常多;遇难和获救的人年龄似乎跨度都很广;
- 3个不同的舱年龄总体趋势似乎也一致,2、3等舱乘客20岁多点的人最多,1等舱40岁左右的最多(→_→似乎符合财富和年龄的分配哈);
- 登船港口人数按照S、C、Q递减,而且S远多于另外俩港口。
这个时候我们可能会有一些想法了:
- 不同舱位/乘客等级可能和财富/地位有关系,最后获救概率可能会不一样
- 年龄对获救概率也一定是有影响的,毕竟前面说了,副船长还说『小孩和女士先走』呢
- 和登船港口是不是有关系呢?也许登船港口不同,人的出身地位不同?
下面我们再来统计统计,看看这些属性值的统计分布吧。
#看看各乘客等级的获救情况
fig = plt.figure()
fig.set(alpha=0.2) Survived_0 = data_train.Pclass[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Pclass[data_train.Survived == 1].value_counts()
df = pd.DataFrame({'survived':Survived_1,'unsurvived':Survived_0})
df.plot(kind='bar',stacked=True)
plt.title(u"各乘客等级的获救情况",fontproperties=getChineseFont())
plt.xlabel(u"乘客等级",fontproperties=getChineseFont())
plt.ylabel(u"人数",fontproperties=getChineseFont()) plt.show()
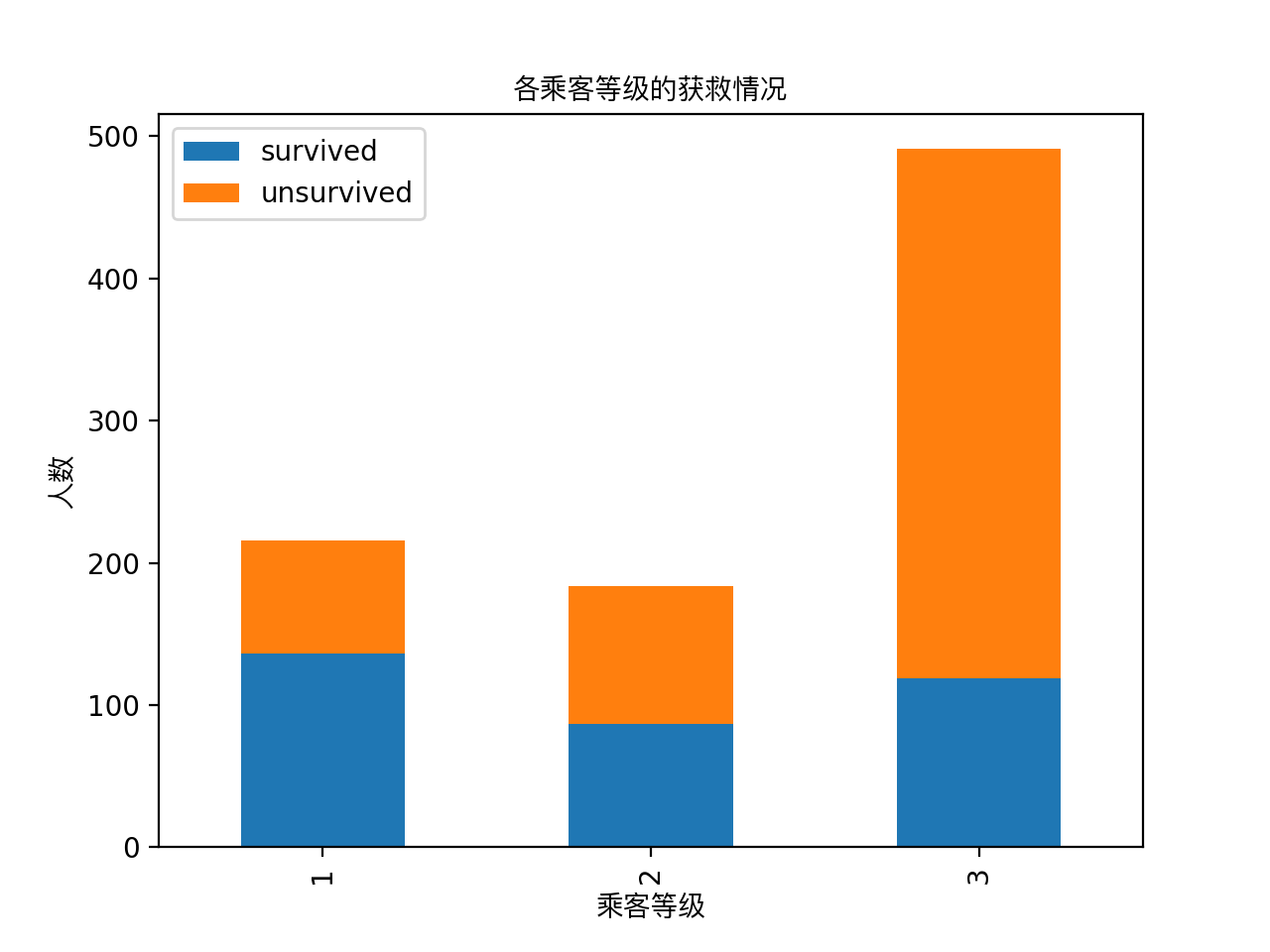
显然等级为1 的乘客获救概率更高,这一定是影响最后获救的一个特征。
#看看各登录港口的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_0 = data_train.Embarked[data_train.Survived == 0].value_counts()
Survived_1 = data_train.Embarked[data_train.Survived == 1].value_counts()
df=pd.DataFrame({'survived':Survived_1, 'unsurvived':Survived_0})
df.plot(kind='bar', stacked=True)
plt.title(u"各登录港口乘客的获救情况",fontproperties=getChineseFont())
plt.xlabel(u"登录港口",fontproperties=getChineseFont())
plt.ylabel(u"人数",fontproperties=getChineseFont()) plt.show()
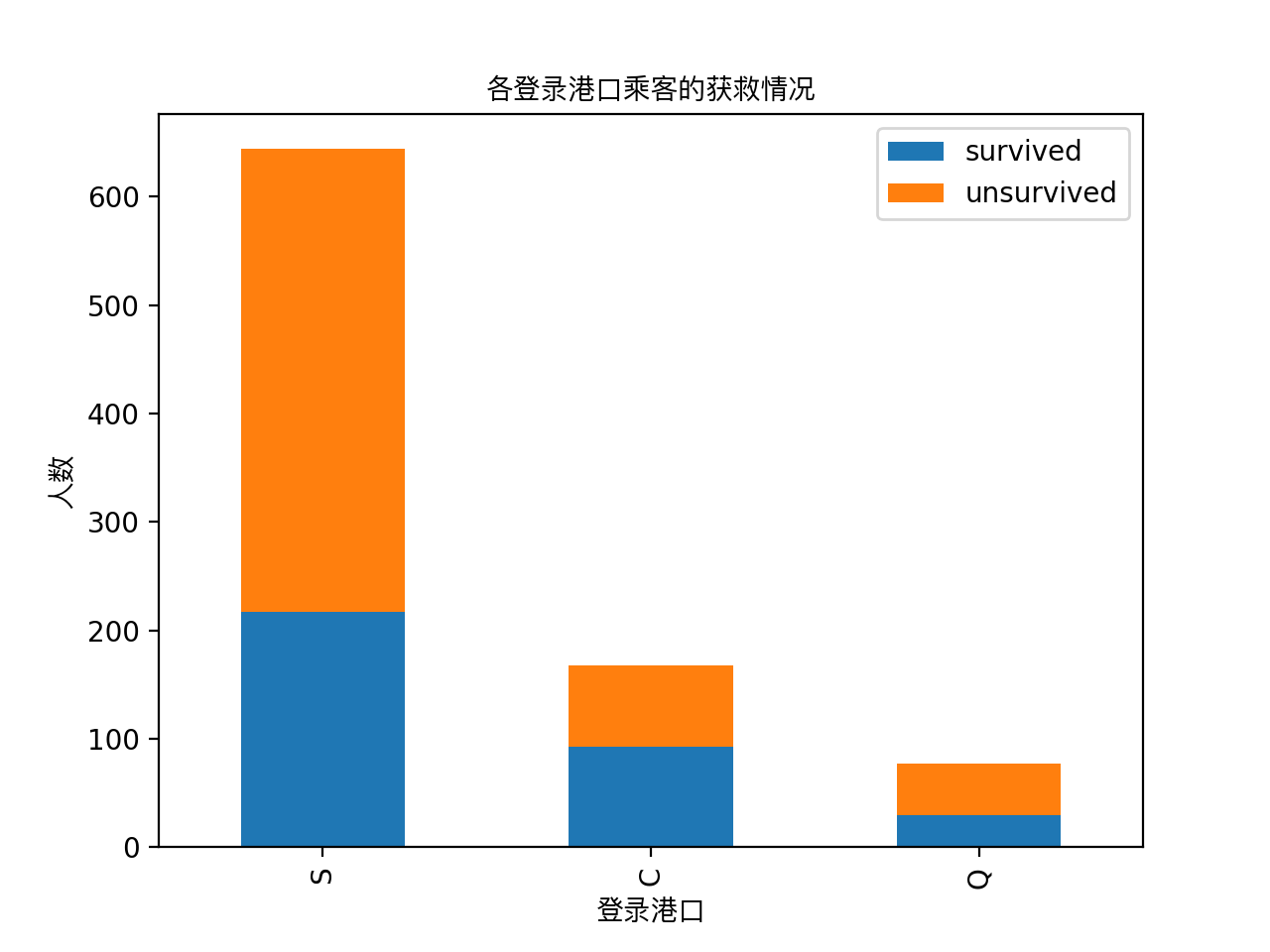
#看看各性别的获救情况
fig = plt.figure()
fig.set(alpha=0.2) # 设定图表颜色alpha参数 Survived_m = data_train.Survived[data_train.Sex == 'male'].value_counts()
Survived_f = data_train.Survived[data_train.Sex == 'female'].value_counts()
df=pd.DataFrame({'male':Survived_m, 'female':Survived_f})
df.plot(kind='bar', stacked=True)
plt.title(u"按性别看获救情况",fontproperties=getChineseFont())
plt.xlabel(u"性别",fontproperties=getChineseFont())
plt.ylabel(u"人数",fontproperties=getChineseFont())
plt.show()

歪果盆友果然很尊重lady,lady first践行得不错。性别无疑也要作为重要特征加入最后的模型之中
kaggle-泰坦尼克号Titanic-1的更多相关文章
- 数据分析-kaggle泰坦尼克号生存率分析
概述 1912年4月15日,泰坦尼克号在首次航行期间撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难.沉船导致大量伤亡的原因之一是没有足够的救生艇给乘客和船员.虽然幸存下来有一些运气因素,但 ...
- kaggle 泰坦尼克号问题总结
学习了机器学习这么久,第一次真正用机器学习中的方法解决一个实际问题,一步步探索,虽然最后结果不是很准确,仅仅达到了0.78647,但是真是收获很多,为了防止以后我的记忆虫上脑,我决定还是记录下来好了. ...
- 【项目实战】Kaggle泰坦尼克号的幸存者预测
前言 这是学习视频中留下来的一个作业,我决定根据大佬的步骤来一步一步完成整个项目,项目的下载地址如下:https://www.kaggle.com/c/titanic/data 大佬的传送门:http ...
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- kaggle& titanic代码
这两天报名参加了阿里天池的’公交线路客流预测‘赛,就顺便先把以前看的kaggle的titanic的训练赛代码在熟悉下数据的一些处理.题目根据titanic乘客的信息来预测乘客的生还情况.给了titan ...
- kaggle Titanic心得
Titanic是kaggle上一个练手的比赛,kaggle平台提供一部分人的特征,以及是否遇难,目的是预测另一部分人是否遇难.目前抽工作之余,断断续续弄了点,成绩为0.79426.在这个比赛过程中,接 ...
- 我的第一个 Kaggle 比赛学习 - Titanic
背景 Titanic: Machine Learning from Disaster - Kaggle 2 年前就被推荐照着这个比赛做一下,结果我打开这个页面便蒙了,完全不知道该如何下手. 两年后,再 ...
- 机器学习案例学习【每周一例】之 Titanic: Machine Learning from Disaster
下面一文章就总结几点关键: 1.要学会观察,尤其是输入数据的特征提取时,看各输入数据和输出的关系,用绘图看! 2.训练后,看测试数据和训练数据误差,确定是否过拟合还是欠拟合: 3.欠拟合的话,说明模 ...
- 20151007kaggle Titanic心得
Titanic是kaggle上一个练手的比赛,kaggle平台提供一部分人的特征,以及是否遇难,目的是预测另一部分人是否遇难.目前抽工作之余,断断续续弄了点,成绩为0.79426.在这个比赛过程中,接 ...
- 如何做到机器学习竞赛Kaggle排名前2%
原创文章,同步首发自作者个人博客 .转载请务必在文章开头显眼处注明出处 摘要 本文详述了如何通过数据预览,探索式数据分析,缺失数据填补,删除关联特征以及派生新特征等方法,在Kaggle的Titanic ...
随机推荐
- [转]无网络环境,在Windows Server 2008 R2和SQL Server 2008R2环境安装SharePoint2013 RT
无网络环境,在Windows Server 2008 R2和SQL Server 2008R2环境安装SharePoint2013 RT,这个还有点麻烦,所以记录一下,下次遇到省得绕弯路.进入正题: ...
- java web jsp
一.WEB应用的目录结构 通常我们是在IDE中创建web应用程序,IDE自动为我们实现了WEB的目录结构,下面来看如何徒手创建一个WEB程序. 首先来看一下Tomcat自带的一个web应用的目录结构 ...
- Quick guide for converting from JAGS or BUGS to NIMBLE
Converting to NIMBLE from JAGS, OpenBUGS or WinBUGS NIMBLE is a hierarchical modeling package that u ...
- emacs之配置4,颜色插件
来自https://github.com/oneKelvinSmith/monokai-emacs/blob/master/monokai-theme.el monokai-theme.el ;;; ...
- 【转】Java中的内部类和匿名类
Java内部类(Inner Class),类似的概念在C++里也有,那就是嵌套类(Nested Class),乍看上去内部类似乎有些多余,它的用处对于初学者来说可能并不是那么显著,但是随着对它的 ...
- 1027代码审计平台 1-sonar scanner
1.代码审计 1.1综合性的代码分析平台 sonar支持自定义规则,较多的公司使用 360火线 1.2IDE辅助功能 Xcode.Android studio 阿里巴巴Java开发手机ide插件支持 ...
- PHP-fpm启动时 出现 PHP Warning: PHP Startup: Invalid library (maybe not a PHP library) 'fileinfo.so' in Unknown on line 0
出现该问题的原因之一是: 在编译PHP时启用了fileinfo扩展(内置),但同时在php.ini文件中添加了: extension=fileinfo.so 去掉或注释之后,重启php-fpm,警告消 ...
- ADO.Net学习总结
一.讲述6个ADO.NET中的常用对象: Connection对象Command对象DataReader对象DataAdapter对象DataSet对象DataTable对象DataRow对象Data ...
- linux 完全卸载mysql数据库
a)查看系统中是否以rpm包安装的mysql [root@linux ~]# rpm -qa | grep -i mysql MySQL-server-5.1.49-1.glibc23 MySQL-c ...
- 学习Maven之PropertiesMavenPlugin
1.PRoperties-maven-plugin是个什么鬼? 介绍前我们先看一个问题,比如我们有一个maven项目结构如下:一般我们都把一些配置文件放到像src/main/resources/jdb ...