Java实现:数据结构之排序
Java实现:数据结构之排序
0.概述
- 形式化定义:假设有n个记录的序列(待排序列)为{ R1, R2 , …, Rn },其相应的关键字序列为 { K1, K2, …, Kn }。找到{1,2, …, n}的一个排列p1,p2, …, pn,使得Kp1≤Kp2≤ …≤ Kpn (升序),按此排列将n个记录重新排列为 { Rp1, Rp2, …,Rpn }的操作称作排序。
- 排序方法分类
- 基于比较的排序:
- 比较两个关键字大小
- 移动关键字到合适位置(交换或复制)
- 不基于比较的排序
- 基于比较的排序:
- 排序有内部排序和外部排序之分,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
- 本篇博客所要介绍的是内部排序中的八大排序方法(参考博客地址为C语言实现):

1.插入排序—直接插入排序(Straight Insertion Sort)
- 基本思想
在要排序的一组数中,假设前面(n-1)[n>=2] 个数已经是排好顺序的,现在要把第n个数插到前面的有序数中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。 - 代码实现(InsertSort.java)
package DataStructures.Sort;
public class InsertSort {
public InsertSort(int a[]){
int temp = 0;
for(int i=1; i<a.length; i++){
int j = i-1;
temp=a[i];
for(; j>=0 && temp<a[j]; j--){
a[j+1] = a[j]; //将大于temp的值整体后移一个单位
}
a[j+1] = temp;
}
}
}
- 运行结果(InsertSortDemo.java)

2. 插入排序—希尔排序(Shell's Sort)
- 基本思想
算法先将要排序的一组数按某个增量d(n/2,n为要排序数的个数)分成若干组,每组中记录的下标相差d.对每组中全部元素进行直接插入排序,然后再用一个较小的增量(d/2)对它进行分组,在每组中再进行直接插入排序。当增量减到1时,进行直接插入排序后,排序完成。 - 代码实现(ShellSort.java)
package DataStructures.Sort;
public class ShellSort {
public ShellSort(int a[]) {
double d1 = a.length;
int temp = 0;
while (true) {
d1 = Math.ceil(d1 / 2); //返回大于参数x的最小整数,即对浮点数向上取整
int d = (int) d1;
for (int x = 0; x < d; x++) {
for (int i = x + d; i < a.length; i += d) {
int j = i - d;
temp = a[i];
for (; j >= 0 && temp < a[j]; j -= d) {
a[j + d] = a[j];
}
a[j + d] = temp;
}
}
if (d == 1) {
break;
}
}
}
}
- 运行结果(ShellSortDemo.java)

3. 选择排序—简单选择排序(Simple Selection Sort)
- 基本思想
在要排序的一组数中,选出最小(或者最大)的一个数与第1个位置的数交换;然后在剩下的数当中再找最小(或者最大)的与第2个位置的数交换,依次类推,直到第n-1个元素(倒数第二个数)和第n个元素(最后一个数)比较为止。 - 代码实现(SelectSort.java)
package DataStructures.Sort;
public class SelectSort {
public SelectSort(int a[]){
int position = 0;
for(int i=0; i<a.length; i++){
int j = i+1;
position = i;
int temp = a[i];
for(; j<a.length; j++){
if(a[j] < temp){
temp = a[j];
position = j;
}
}
a[position] =a [i];
a[i] = temp;
}
}
}
- 运行结果(SelectSortDemo.java)

4. 选择排序—堆排序(Heap Sort)
- 基本思想
- 堆排序是一种树形选择排序,是对直接选择排序的有效改进。可以将一个堆看做是一棵完全二叉树的顺序存储。以升序排序为例:
- 通过建大顶堆,将待排序列中的最大元素筛选出来(即根结点位置)。
- 将根结点与待排序列中最后一个元素交换。
- 调整剩余元素再次成为大顶堆。
- 不断重复上述过程,直至堆中只剩2个元素为止。
- 代码实现(HeapSort.java)
//以建立大顶堆为例
package DataStructures.Sort;
public class HeapSort {
public HeapSort(int a[]){
int arrayLength=a.length;
//循环建堆
for(int i=0;i<arrayLength-1;i++){
//建堆
buildMaxHeap(a,arrayLength-1-i);
//交换堆顶和最后一个元素
swap(a,0,arrayLength-1-i);
}
}
private void swap(int[] data, int i, int j) {
int temp = data[i];
data[i] = data[j];
data[j] = temp;
}
//对data数组从0到lastIndex建大顶堆
private void buildMaxHeap(int[] data, int lastIndex) {
//从lastIndex处节点(最后一个节点)的父节点开始
for(int i=(lastIndex-1)/2;i>=0;i--){
//k保存正在判断的节点
int k=i;
//如果当前k节点的子节点存在
while(k*2+1<=lastIndex){
//k节点的左子节点的索引
int biggerIndex=2*k+1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if(biggerIndex<lastIndex){
//若果右子节点的值较大
if(data[biggerIndex]<data[biggerIndex+1]){
//biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
//如果k节点的值小于其较大的子节点的值
if(data[k]<data[biggerIndex]){
//交换他们
swap(data,k,biggerIndex);
//将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k=biggerIndex;
}
else{
break;
}
}
}
}
}
- 运行结果(HeapSortDemo.java)

5. 交换排序—冒泡排序(Bubble Sort)
- 基本思想
在要排序的一组数中,对当前还未排好序的范围内的全部数,自上而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较小的往上冒。即:每当两相邻的数比较后发现它们的排序与排序要求相反时,就将它们互换。 - 代码实现(BubbleSort.java)
package DataStructures.Sort;
public class BubbleSort {
public BubbleSort(int[] a){
int temp;
for(int i=0; i<a.length-1; i++){
for(int j=0; j<a.length-1-i; j++){
if(a[j] > a[j+1]){
temp = a[j];
a[j] = a[j+1];
a[j+1] = temp;
}
}
}
}
}
- 运行结果(BubbleSortDemo.java)
6. 交换排序—快速排序(Quick Sort)
- 基本思想
- 选择一个基准元素,通常选择第一个元素或者最后一个元素
- 通过一趟排序讲待排序的记录分割成独立的两部分,其中一部分记录的元素值均比基准元素值小。另一部分记录的 元素值比基准值大。
- 此时基准元素在其排好序后的正确位置
- 然后分别对这两部分记录用同样的方法继续进行排序,直到整个序列有序
- 代码实现(QuickSort.java)
package DataStructures.Sort;
public class QuickSort {
public QuickSort(int[] a){
quick(a);
}
private int getMiddle(int[] list, int low, int high) {
int temp = list[low]; //数组的第一个作为中轴
while (low < high){
while (low<high && list[high]>=temp) {
high--;
}
list[low] =list[high]; //比中轴小的记录移到低端
while (low <high && list[low]<=temp) {
low++;
}
list[high] = list[low]; //比中轴大的记录移到高端
}
list[low] = temp; //中轴记录到尾
return low; //返回中轴的位置
}
private void quickSort(int[] list, int low, int high) {
if (low < high){
int middle = getMiddle(list, low, high); //将list数组进行一分为二
quickSort(list, low, middle - 1); //对低字表进行递归排序
quickSort(list, middle + 1, high); //对高字表进行递归排序
}
}
private void quick(int[] a2) {
if (a2.length > 0) { //查看数组是否为空
quickSort(a2,0, a2.length - 1);
}
}
}
- 运行结果(QuickSortDemo.java)

7. 归并排序(Merge Sort)
- 基本思想
- 归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列。
- 分解:将含有n个元素的待排序列分解为各含n/2个元素的两个子序列。
- 解决:用归并排序递归地排序两个子序列。
- 合并:合并两个已排序的子序列,以得到最终结果。
- 代码实现(MergeSort.java)
package DataStructures.Sort;
public class MergeSort {
public MergeSort(int[] a){
sort(a,0,a.length-1);
}
private void sort(int[] data, int left, int right) {
if(left < right){
//找出中间索引
int center = (left+right)/2;
//对左边数组进行递归
sort(data, left, center);
//对右边数组进行递归
sort(data, center+1, right);
//合并
merge(data, left, center, right);
}
}
private void merge(int[] data, int left, int center, int right) {
int [] tmpArr = new int[data.length];
int mid = center+1;
//third记录中间数组的索引
int third = left;
int tmp = left;
while(left<=center && mid<=right){
//从两个数组中取出最小的放入中间数组
if(data[left] <= data[mid]){
tmpArr[third++] = data[left++];
}
else{
tmpArr[third++] = data[mid++];
}
}
//剩余部分依次放入中间数组
while(mid <= right){
tmpArr[third++] = data[mid++];
}
while(left <= center){
tmpArr[third++] = data[left++];
}
//将中间数组中的内容复制回原数组
while(tmp <= right){
data[tmp] = tmpArr[tmp++];
}
}
}
- 运行结果(MergeSortDemo.java)

8. 基数排序(Radix Sort)
基本思想
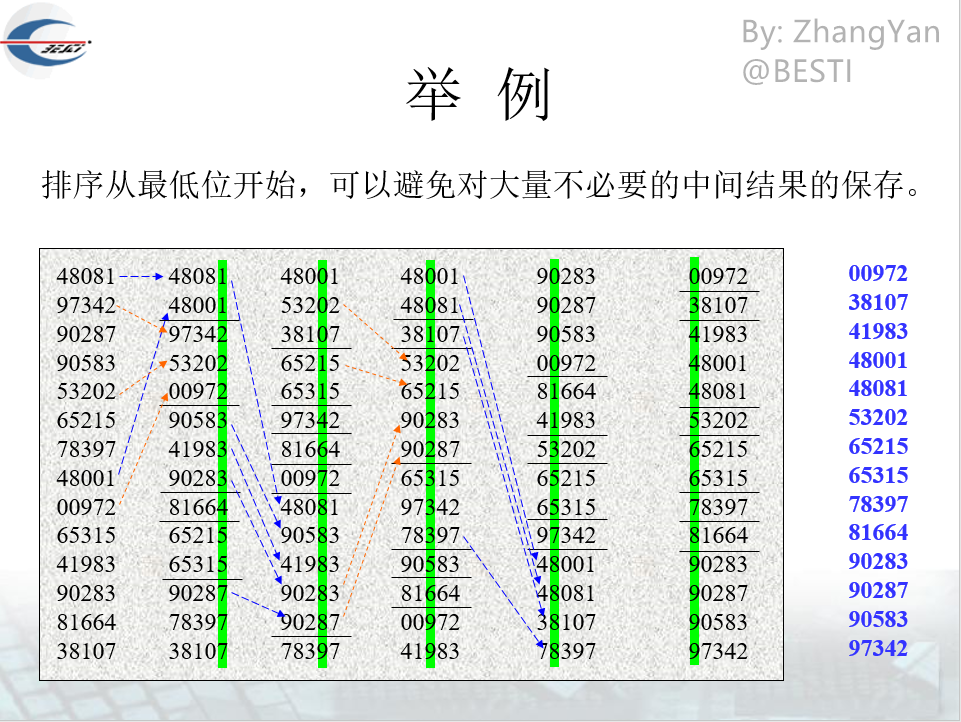
- 一种借助“多关键字排序”的思想来实现“单关键字排序”的算法。
- 将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
代码实现(RadixSort.java)
package DataStructures.Sort;
import java.util.ArrayList;
import java.util.List;
public class RadixSort {
public RadixSort(int[] a){
radixSort(a);
}
private void radixSort(int[] a){
//首先确定排序的趟数;
int max=a[0];
for(int i=1; i<a.length; i++){
if(a[i] > max){
max = a[i];
}
}
int time = 0;
//判断位数;
while(max > 0){
max /= 10;
time++;
}
//建立10个队列;
List<ArrayList> queue = new ArrayList<ArrayList>();
for(int i=0; i<10; i++){
ArrayList<Integer>queue1 = new ArrayList<Integer>();
queue.add(queue1);
}
//进行time次分配和收集;
for(int i=0; i<time; i++){
//分配数组元素;
for(int j=0; j<a.length; j++){
//得到数字的第time+1位数;
int x = a[j]%(int)Math.pow(10,i+1)/(int)Math.pow(10, i);
ArrayList<Integer>queue2 = queue.get(x);
queue2.add(a[j]);
queue.set(x, queue2);
}
int count = 0;//元素计数器;
//收集队列元素;
for(int k=0; k<10; k++){
while(queue.get(k).size() > 0){
ArrayList<Integer>queue3 = queue.get(k);
a[count] = queue3.get(0);
queue3.remove(0);
count++;
}
}
}
}
}
- 运行结果(RadixDemo.java)
9. 脉络梳理
- 排序算法稳定性:
- 首先,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。在简单形式化一下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。
- 其次,说一下稳定性的好处。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就 是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。
- 所以,堆排序、快速排序、希尔排序、直接选择排序不是稳定的排序算法,而基数排序、冒泡排序、直接插入排序、折半插入排序、归并排序是稳定的排序算法。(相关解释参考:排序算法稳定性)
- 各种排序特点的比较:
| 排序算法 | 平均时间 | 最差情形 | 稳定度 | 额外空间 | 备注 |
|---|---|---|---|---|---|
| 直接插入排序 | O(n^2) | O(n^2) | 稳定 | O(1) | n小时较好 |
| 希尔排序 | O(nlogn) | O(n^s),1<s<2 | 不稳定 | O(1) | s是所选分组 |
| 简单选择排序 | O(n^2) | O(n^2) | 不稳定 | O(1) | n小时较好 |
| 堆排序 | O(nlogn) | O(nlogn) | 不稳定 | O(1) | n大时较好 |
| 冒泡排序 | O(n^2) | O(n^2) | 稳定 | O(1) | n小时较好 |
| 快速排序 | O(n) | O(n^2) | 不稳定 | O(nlogn) | n大时较好 |
| 归并排序 | O(nlogn) | O(nlogn) | 稳定 | O(1) | n大时较好 |
| 基数排序 | O(logrd) | O(logrd) | 稳定 | O(n) | d是关键字项数(0-9),r是基数(个十百) |
参考资料
Java实现:数据结构之排序的更多相关文章
- Java中的数据结构及排序算法
(明天补充) 主要是3种接口:List Set Map List:ArrayList,LinkedList:顺序表ArrayList,链表LinkedList,堆栈和队列可以使用LinkedList模 ...
- Java数据结构与排序
一.引子:想要给ArrayList排序却发现没有排序方法?你有两种选择: 1.换用TreeSet: 2.使用Collection.sort(List<T> list) ...
- java项目——数据结构实验报告
java项目——数据结构总结报告 20135315 宋宸宁 实验要求 1.用java语言实现数据结构中的线性表.哈希表.树.图.队列.堆栈.排序查找算法的类. 2.设计集合框架,使用泛型实现各类. ...
- JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balaba ...
- (6)Java数据结构-- 转:JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balab ...
- 【转】Java学习---Java核心数据结构(List,Map,Set)使用技巧与优化
[原文]https://www.toutiao.com/i6594587397101453827/ Java核心数据结构(List,Map,Set)使用技巧与优化 JDK提供了一组主要的数据结构实现, ...
- Java同步数据结构之ConcurrentSkipListMap/ConcurrentSkipListSet
引言 上一篇Java同步数据结构之Map概述及ConcurrentSkipListMap原理已经将ConcurrentSkipListMap的原理大致搞清楚了,它是一种有序的能够实现高效插入,删除,更 ...
- MySql无限分类数据结构--预排序遍历树算法
MySql无限分类数据结构--预排序遍历树算法 无限分类是我们开发中非常常见的应用,像论坛的的版块,CMS的类别,应用的地方特别多. 我们最常见最简单的方法就是在MySql里ID ,parentID, ...
- Java内存访问重排序笔记
>>关于重排序 重排序通常是编译器或运行时环境为了优化程序性能而采取的对指令进行重新排序执行的一种手段. 重排序分为两类:编译期重排序和运行期重排序,分别对应编译时和运行时环境. > ...
随机推荐
- Oracle 11G Client 客户端安装步骤(图文详解)
http://www.cnblogs.com/jiguixin/archive/2011/09/09/2172672.html 下载地址: http://download.oracle.com/otn ...
- [置顶] 数据库优化实践【MS SQL优化开篇】
数据库定义: 数据库是依照某种数据模型组织起来并存在二级存储器中的数据集合,此集合具有尽可能不重复,以最优方式为特定组织提供多种应用服务,其数据结构独立于应用程序,对数据的CRUD操作进行统一管理和控 ...
- java高级---->Thread之BlockingQueue的使用
今天我们通过实例来学习一下BlockingQueue的用法.梦想,可以天花乱坠,理想,是我们一步一个脚印踩出来的坎坷道路. BlockingQueue的实例 官方文档上的对于BlockingQueue ...
- FlipClock.js时钟,计数,3D翻转插件
1.FlipClock.js能够自动定义计数,时钟的翻牌效果,调用简单,下面简单记录下用法 2.官网地址:http://www.flipclockjs.com/ 3.调用2个文件 <link h ...
- CentOS中用户不在 sudoers 文件中。此事将被报告。
首先切换为root用户 su root; 然后更改etc/sudoers文件的只读为可读可写可执行. sudo chmod 777 /etc/sudoers 输入visudo命令即可编辑文件,找到ro ...
- centos samba搭建
1.需求: 建立两个用户(zx,zxadmin),zxadmin能访问所有目录,zx只能访问指定目录. 2.安装smb [root@vi /]# yum install samba -y 3.创建用户 ...
- jq和axios的取消请求
场景: 分页: 每次点击分页会发送请求,如果上一次请求还未获取到,下一次请求已经开始且先一步获取到,那么数据上会出现问题. 快速点击会发送多次请求,多次点击的时候一般的做法我们会定义一个flag,此时 ...
- SQL Server 2008 R2数据库镜像部署图文教程
数据库镜像是一种针对数据库高可用性的基于软件的解决方案.其维护着一个数据库的两个相同的副本,这两个副本分别放置在不同的SQL Server数据库实例中 概述 “数据库镜像”是一种针对数据库高可用性的基 ...
- kubernetes实战(八):k8s集群安全机制RBAC
1.基本概念 RBAC(Role-Based Access Control,基于角色的访问控制)在k8s v1.5中引入,在v1.6版本时升级为Beta版本,并成为kubeadm安装方式下的默认选项, ...
- Maven的pom文件配置
pom.xml文件如下: <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http:// ...