Hadoop源码学习笔记之NameNode启动场景流程四:rpc server初始化及启动
老规矩,还是分三步走,分别为源码调用分析、伪代码核心梳理、调用关系图解。
一、源码调用分析
根据上篇的梳理,直接从initialize()方法着手。源码如下,部分代码的功能以及说明,已经在注释阐述了。
protected void initialize(Configuration conf) throws IOException {
// 可以通过找到下面变量名的映射,在hdfs-default.xml中找到对应的配置
if (conf.get(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS) == null) {
String intervals = conf.get(DFS_METRICS_PERCENTILES_INTERVALS_KEY);
if (intervals != null) {
conf.set(HADOOP_USER_GROUP_METRICS_PERCENTILES_INTERVALS,
intervals);
}
}
......
// 核心代码:启动HttpServer
if (NamenodeRole.NAMENODE == role) {
startHttpServer(conf);
}
this.spanReceiverHost = SpanReceiverHost.getInstance(conf);
// 核心代码:FSNamesystem初始化
loadNamesystem(conf);
// 核心代码:创建一个rpc server实例
rpcServer = createRpcServer(conf);
......
// 核心代码:启动一些服务组件,包括rpc server等
startCommonServices(conf);
}
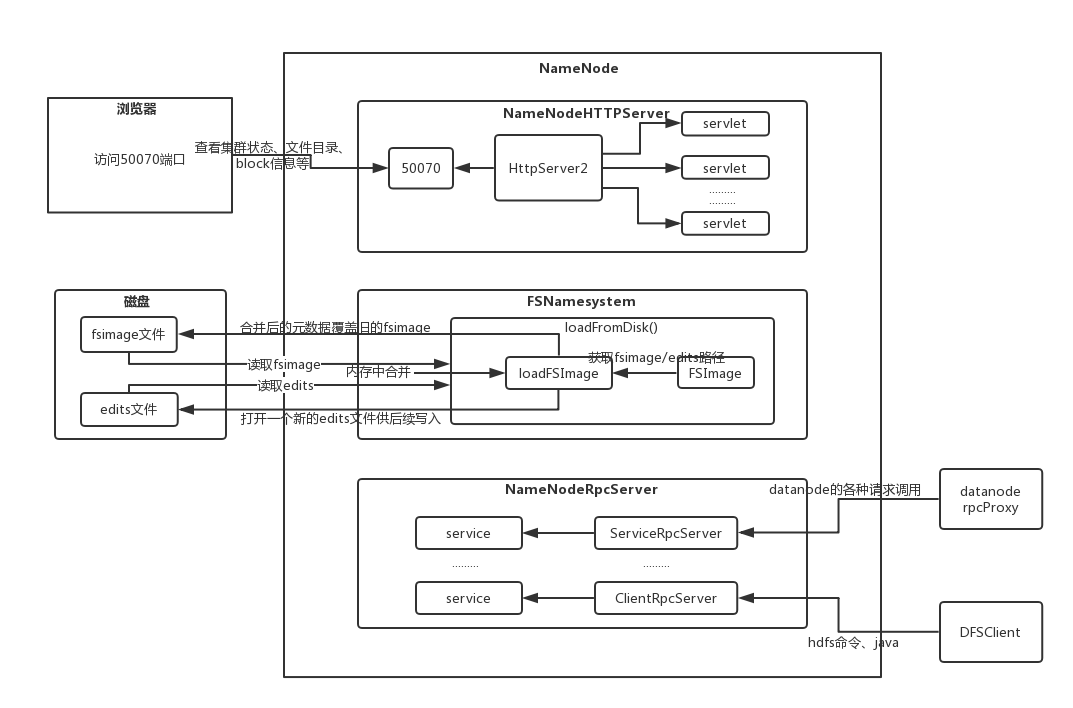
这段代码涉及到rpc server初始化及启动的核心,有两处:
第一处是rpcServer = createRpcServer(conf); 这个createRpcServer()的功能就是创建了一个rpc server的实例。如下:
protected NameNodeRpcServer createRpcServer(Configuration conf)
throws IOException {
return new NameNodeRpcServer(conf, this);
}
我们继续进去NameNodeRpcServer类的构造方法中看一看,到底里面做了哪些事情:
public NameNodeRpcServer(Configuration conf, NameNode nn)
throws IOException {
this.nn = nn;
this.namesystem = nn.getNamesystem();
this.metrics = NameNode.getNameNodeMetrics(); int handlerCount =
conf.getInt(DFS_NAMENODE_HANDLER_COUNT_KEY,
DFS_NAMENODE_HANDLER_COUNT_DEFAULT); RPC.setProtocolEngine(conf, ClientNamenodeProtocolPB.class,
ProtobufRpcEngine.class);
// ----------1------------
// ---- 下面一堆都是实例化各种协议和服务的对象,所有的服务都是BlockingService接口的实现
// client和namenode之间进行通信需要调用的接口,包括:创建目录、管理block、设置权限等一些操作
ClientNamenodeProtocolServerSideTranslatorPB
clientProtocolServerTranslator = new ClientNamenodeProtocolServerSideTranslatorPB(this);
BlockingService clientNNPbService = ClientNamenodeProtocol.
newReflectiveBlockingService(clientProtocolServerTranslator); // datanode和namenode之间进行通信调用的接口,包括:datanode注册、heartbeatReport、blockReport等接口
DatanodeProtocolServerSideTranslatorPB dnProtoPbTranslator =
new DatanodeProtocolServerSideTranslatorPB(this);
BlockingService dnProtoPbService = DatanodeProtocolService
.newReflectiveBlockingService(dnProtoPbTranslator); // 不同的namenode之间进行通信需要调用的接口
NamenodeProtocolServerSideTranslatorPB namenodeProtocolXlator =
new NamenodeProtocolServerSideTranslatorPB(this);
BlockingService NNPbService = NamenodeProtocolService
.newReflectiveBlockingService(namenodeProtocolXlator); ......
// ---- 以上都是初始化rpc server关键的部分
// 确保供写数据的rpc服务引擎已经初始化,如果没有初始化,
// 则在此方法中调用registerProtocolEngine()从而将WritableRpcEngine引擎加入到内存中的引擎map
WritableRpcEngine.ensureInitialized(); ......
if (serviceRpcAddr != null) {
......
// -----------2----------
// 实例化一个监听datanode请求的rpc server
this.serviceRpcServer = new RPC.Builder(conf)
.setProtocol(org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB.class)
.setInstance(clientNNPbService)
.setBindAddress(bindHost)
.setPort(serviceRpcAddr.getPort()).setNumHandlers(serviceHandlerCount)
.setVerbose(false)
.setSecretManager(namesystem.getDelegationTokenSecretManager())
.build();
// 将前面实例化的各种协议service添加到这个监听datanode请求的rpc server
// Add all the RPC protocols that the namenode implements
DFSUtil.addPBProtocol(conf, HAServiceProtocolPB.class, haPbService,
serviceRpcServer);
DFSUtil.addPBProtocol(conf, NamenodeProtocolPB.class, NNPbService,
serviceRpcServer);
......
......
} else {
......
}
......
// -----------3------------
// 实例化一个监听客户端请求的rpc server
this.clientRpcServer = new RPC.Builder(conf)
.setProtocol(
org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolPB.class)
.setInstance(clientNNPbService).setBindAddress(bindHost)
.setPort(rpcAddr.getPort()).setNumHandlers(handlerCount)
.setVerbose(false)
.setSecretManager(namesystem.getDelegationTokenSecretManager()).build();
// 将前面实例化的各种协议service添加到这个监听客户端请求的RPC server
// Add all the RPC protocols that the namenode implements
DFSUtil.addPBProtocol(conf, HAServiceProtocolPB.class, haPbService,
clientRpcServer);
DFSUtil.addPBProtocol(conf, NamenodeProtocolPB.class, NNPbService,
clientRpcServer);
......
......
}
进入到NameNodeRpcServer类的构造方法中,可以看到除了上面几行的一些初始化赋值之外,下面的代码好长啊。其实并不复杂,
根据代码的逻辑划分,主要有三部分:
第一部分,实例化各种通信协议和服务对象,比如:负责创建目录、管理block、设置权限等操作的客户端同NameNode通信的
协议服务——ClientNameNodeProtocolServerSideTranslatorPB、负责datanode的启动时向NameNode注册、发送心跳报告、
block信息报告等操作的datanode同NameNode通信的协议服务——DatanodeProtocolServerSideTranslatorPB。篇幅有限,
后面还有不同NameNode之间通信协议服务、HA高可靠、用户权限管理等不在一一详细说明。
第二部分,实例化了一个监听datanode请求的rpc server,并且将第一部分实例化的各种ProtocolService同此rpc server进行绑定,
用于处理rpc server监听到的来自datanode的各种rpc请求。
第三部分,实例化了一个监听客户端请求的rpc server,并将第一部分实例化的各种ProtocolService同此rpc server进行绑定,用于
处理监听到的来自客户端的rpc请求。
至此,rpc server启动之前相关的准备工作已经完毕,接下来就要开始启动rpc server了。继续回到本篇刚开始的initialize()方法中的最后一处核心,
startCommonServices(); 内容如下:
private void startCommonServices(Configuration conf) throws IOException {
// 核心代码:
namesystem.startCommonServices(conf, haContext);
registerNNSMXBean();
if (NamenodeRole.NAMENODE != role) {
startHttpServer(conf);
httpServer.setNameNodeAddress(getNameNodeAddress());
httpServer.setFSImage(getFSImage());
}
// 启动rpcServer
rpcServer.start();
......
}
在此方法中,直接就启动了rpcServer。
但是在第一行的startCommonServices()方法也是核心之一,里面有很重要的一些服务,比如磁盘检查、安全模式判断等,后续篇幅会跟进。
二、伪代码调用流程梳理
NameNode.main() // 入口函数
|——createNameNode(); // 通过new NameNode()进行实例化
|——initialize(); // 方法进行初始化操作
|——startHttpServer(); // 启动HttpServer
|——loadNamesystem(); // 加载元数据
|——createRpcServer(); // 创建rpc server实例
|——new NameNodeRpcServer();
|——service1 // 各种通信协议service
|——service2 // 各种通信协议service
|——service.... // 各种通信协议service
|——serviceRpcServer = new RPC.builder(); // 实例化一个监听datanode请求的rpc server
|——serviceRpcServer.add(service1...); // 将各种service添加到serviceRpcServer
|——clientRpcServer = new RPC.builder(); // 实例化一个监听客户端请求的rpc server
|——clientRpcServer.add(service2...); // 将各种service添加到clientRpcServer
|——startCommonServices();
|——namesystem.startCommonServices(); // 启动一些磁盘检查、安全模式等一些后台服务及线程
|——rpcServer.start(); // 启动rpcServer
|——join()
三、rpc server初始化及启动流程图解
Hadoop源码学习笔记之NameNode启动场景流程四:rpc server初始化及启动的更多相关文章
- Hadoop源码学习笔记之NameNode启动场景流程一:源码环境搭建和项目模块及NameNode结构简单介绍
最近在跟着一个大佬学习Hadoop底层源码及架构等知识点,觉得有必要记录下来这个学习过程.想到了这个废弃已久的blog账号,决定重新开始更新. 主要分以下几步来进行源码学习: 一.搭建源码阅读环境二. ...
- Hadoop源码学习笔记之NameNode启动场景流程二:http server启动源码剖析
NameNodeHttpServer启动源码剖析,这一部分主要按以下步骤进行: 一.源码调用分析 二.伪代码调用流程梳理 三.http server服务流程图解 第一步,源码调用分析 前一篇文章已经锁 ...
- Hadoop源码学习笔记之NameNode启动场景流程五:磁盘空间检查及安全模式检查
本篇内容关注NameNode启动之前,active状态和standby状态的一些后台服务及准备工作,即源码里的CommonServices.主要包括磁盘空间检查. 可用资源检查.安全模式等.依然分为三 ...
- Hadoop源码学习笔记之NameNode启动场景流程三:FSNamesystem初始化源码剖析
上篇内容分析了http server的启动代码,这篇文章继续从initialize()方法中按执行顺序进行分析.内容还是分为三大块: 一.源码调用关系分析 二.伪代码执行流程 三.代码图解 一.源码调 ...
- Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构
Hadoop源码学习笔记(5) ——回顾DataNode和NameNode的类结构 之前我们简要的看过了DataNode的main函数以及整个类的大至,现在结合前面我们研究的线程和RPC,则可以进一步 ...
- Hadoop源码学习笔记(6)——从ls命令一路解剖
Hadoop源码学习笔记(6) ——从ls命令一路解剖 Hadoop几个模块的程序我们大致有了点了解,现在我们得细看一下这个程序是如何处理命令的. 我们就从原头开始,然后一步步追查. 我们先选中ls命 ...
- Hadoop源码学习笔记(2) ——进入main函数打印包信息
Hadoop源码学习笔记(2) ——进入main函数打印包信息 找到了main函数,也建立了快速启动的方法,然后我们就进去看一看. 进入NameNode和DataNode的主函数后,发现形式差不多: ...
- Hadoop源码学习笔记(1) ——第二季开始——找到Main函数及读一读Configure类
Hadoop源码学习笔记(1) ——找到Main函数及读一读Configure类 前面在第一季中,我们简单地研究了下Hadoop是什么,怎么用.在这开源的大牛作品的诱惑下,接下来我们要研究一下它是如何 ...
- Hadoop源码学习笔记(4) ——Socket到RPC调用
Hadoop源码学习笔记(4) ——Socket到RPC调用 Hadoop是一个分布式程序,分布在多台机器上运行,事必会涉及到网络编程.那这里如何让网络编程变得简单.透明的呢? 网络编程中,首先我们要 ...
随机推荐
- python文本操作
file_obj=file("文件路径","模式") 打开文件的模式有: r,以只读方式打开文件 w,打开一个文件只用于写入.如果该文件已存在则将其覆盖.如果该 ...
- xcopy-参数详解
XCOPY——目录复制命令 1.功能:复制指定的目录和目录下的所有文件连同目录结构. 2.类型:外部命令 3.格式:XCOPY [源盘:]〈源路径名〉[目标盘符:][目标路径名][/S][/V][/E ...
- 关于VSTS自动Build报错问题之Microsoft.Net.Compilers
报错内容如下: --06T11::.6035712Z ##[error]Dotnet command failed with non-zero exit code on the following p ...
- HBuilder设置APP状态栏
一. 前言 状态栏就是手机屏幕最顶部的区域,包括了:信号.运营商.电量等信息.通常APP都有属于自己的色调风格,为了达到整体视觉美观,通常会设置状态栏和标题栏的色调设置成一致. 图例: 二.状态栏状态 ...
- CSV输入输出
读取csv文件: import csv cf = open('D:\pywe.csv','rb') cf.readline() #读取标题行,光标移动到下一行(相当于调过标题行) for l in c ...
- POP3、SMTP端口(SSL、TSL)
POP3服务器地址: 110 995 支持SSLSMTP服务器地址: 25 465 或者 587 支持SSL(TSL) 465端口是SSL/TLS通讯协议的 ...
- Exchange 2010 服务器邮件传输配额设置详解
在企业的邮件系统管理中,传输邮件的大小配额关系到邮件队列.邮件传输速度以及关系到该附件是否能正常发送,直接关系到用户体验.为此,传输邮件大小的设置,也经常是企业邮件管理员比较迷惑的地方.如下: 1) ...
- 骑士周游问题跳马问题C#实现(附带WPF工程代码)
骑士周游问题,也叫跳马问题. 问题描述: 将马随机放在国际象棋的8×8棋盘的某个方格中,马按走棋规则进行移动.要求每个方格只进入一次,走遍棋盘上全部64个方格. 代码要求: 1,可以任意选定马在棋盘上 ...
- ELK系统分析Nginx日志并对数据进行可视化展示
结合之前写的一篇文章:ELK日志分析平台搭建全过程,上篇文章主要讲了部署方法.而这篇文章介绍的是单独监控nginx 日志分析再进行可视化图形展示. 本文环境与上一篇环境一样,前提 elasticsea ...
- August 11th 2017 Week 32nd Friday
I can't give you the world, but I can give you my world. 我不能给你全世界,但是我的世界我可以全部给你. Maybe I can't give ...