Spark RDD理解
目录
RDD简介
RDD是弹性分布式数据集(Resilient Distributed Dataset),能在并行计算阶段进行高效的数据共享;RDD还提供了一种粗粒度接口,该接口会将相同的操作应用到多个数据集上并记录创建数据集的‘血统’,从而在不需要存储真正的数据的情况下,达到高效的容错性。
RDD操作类别
RDD操作大致可分为四类:创建操作、转换操作、控制操作、行动操作;在这些大类的基础上还能划为些细类,下面是大部分的RDD操作,以及其细类划分情况。

RDD分区
分区的多少决定RDD的并行粒度;分区是逻辑概念,分区前后可能存储在同一内存;RDD分区之间存在依赖关系,分为宽依赖和窄依赖
宽依赖:多个子RDD分区依赖一个父RDD分区;如join,groupBy操作;
窄依赖:窄依赖:每个父RDD的分区都至多被被一个子RDD的分区使用;如map操作一对一关系
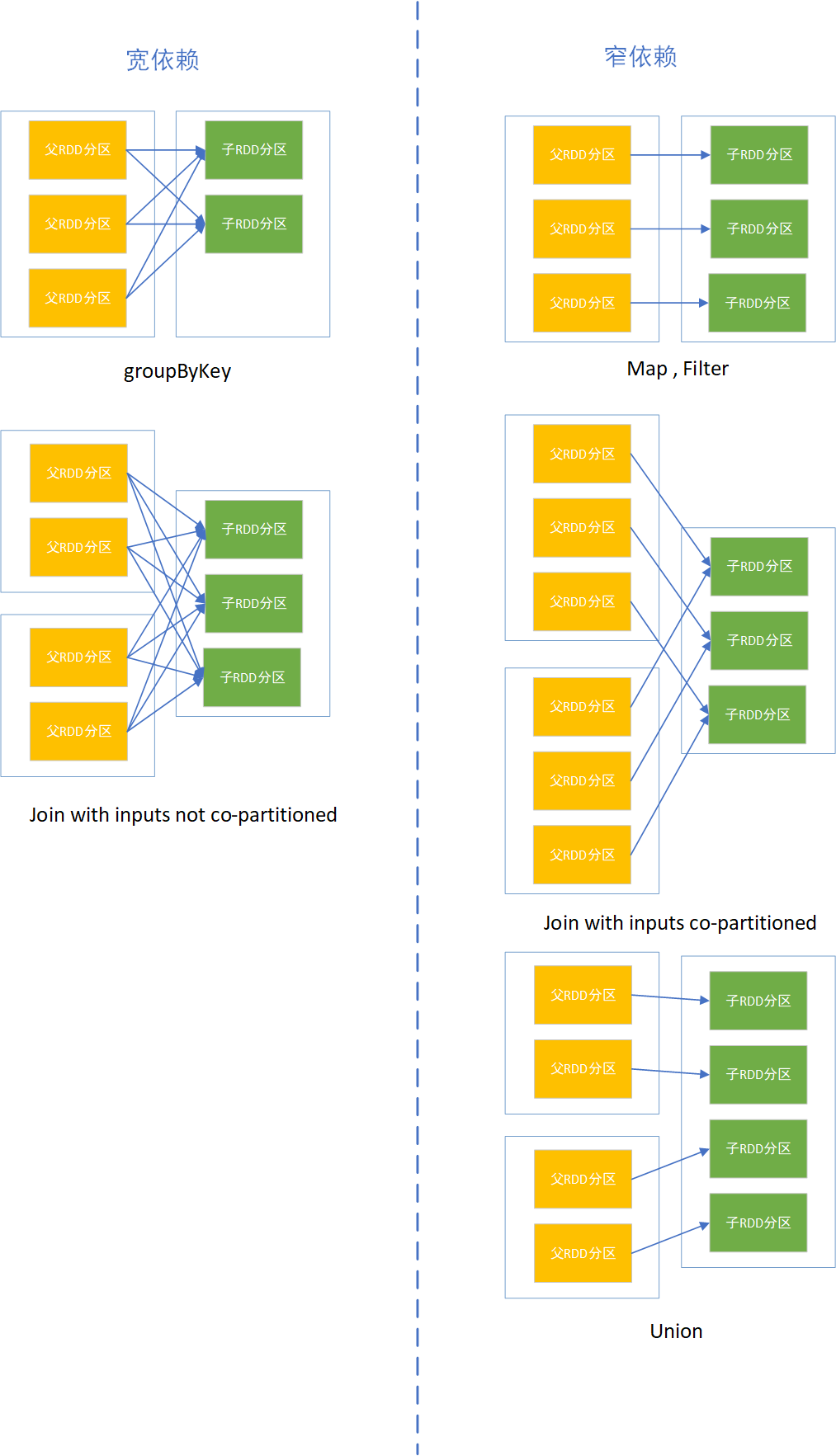
宽依赖和窄依赖作用
窄依赖允许在单个集群节点上流水线式执行,这个节点可以计算所有父级分区;而且,在窄依赖中,节点失败后的恢复更加高效
宽依赖的继承关系中,单个失败节点可能导致一个RDD的所有祖先RDD中的一些分区丢失,导致计算重新执行
RDD分区划分器
spark中RDD计算是以分区为单位的,而计算函数都是在迭代器中复合;分区计算一般使用mapPartitions等计算。
spark提供了两种默认的分区划分器,一种是HashPartitioner(哈希分区划分器),另一种是RangePartitioner(范围分区划分器)
RDD到调度
RDD转换操作属于lazy级别,会延迟执行,作业的提交是由行动操作触发。当执行RDD行动操作时触发作业的提交,然后会根据RDD之间的关系构建DAG(有向无环图),再提交给DAGScheduler进行解析;解析之后会得到调度阶段Stage,也就是taskSet;最后TashScheduler进一步解析得到task,task将会在Worker中Executor里面执行。
Spark RDD理解的更多相关文章
- Spark RDD理解-总结
1.spark是什么 快速.通用.可扩展的分布式计算引擎. 2. 弹性分布式数据集RDD RDD(Resilient Distributed Dataset),是Spark中最基本的数据抽象结构,表示 ...
- [bigdata] Spark RDD整理
1. RDD是什么RDD:Spark的核心概念是RDD (resilient distributed dataset),指的是一个只读的,可分区的弹性分布式数据集,这个数据集的全部或部分可以缓存在内存 ...
- Spark RDD aggregateByKey
aggregateByKey 这个RDD有点繁琐,整理一下使用示例,供参考 直接上代码 import org.apache.spark.rdd.RDD import org.apache.spark. ...
- Spark RDD概念学习系列之RDD的转换(十)
RDD的转换 Spark会根据用户提交的计算逻辑中的RDD的转换和动作来生成RDD之间的依赖关系,同时这个计算链也就生成了逻辑上的DAG.接下来以“Word Count”为例,详细描述这个DAG生成的 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- Spark RDD整理
参考资料: Spark和RDD模型研究:http://itindex.net/detail/51871-spark-rdd-模型 理解Spark的核心RDD:http://www.infoq.com/ ...
- Spark RDD概念学习系列之rdd持久化、广播、累加器(十八)
1.rdd持久化 2.广播 3.累加器 1.rdd持久化 通过spark-shell,可以快速的验证我们的想法和操作! 启动hdfs集群 spark@SparkSingleNode:/usr/loca ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
随机推荐
- Ubuntu下Visual Studio Code的配置
最近在Ubuntu系统里用Visual Studio Code编写vue代码时,在build的时候老是报错,后来发现原来Visual Studio Code里默认Tab是4个空格,而vue代码要求ta ...
- [朴孝敏/Loco][Nice Body]
歌词来源:http://music.163.com/#/song?id=28738294 作曲 : 勇敢兄弟/大象王国 [作曲 : 勇敢兄弟/大象王国] 作词 : 勇敢兄弟 [作词 : 勇敢兄弟] A ...
- 关于Class类的getResource().getPath()方法
程序中配置文件如果放置在classes文件夹,那么我们就可以使用Class类的getResource().getPath()方法获取文件路径. 例如: String path = DBUtil.cla ...
- 学习python第一天总纲
1).python基础语法:4周课程(结束阶段考试) 2).前端知识点:html.css.javascript(js).jQuery 3).Linux(系统).数据库(关系型&非关系型) 4) ...
- 深入理解 iOS Rendering Process
本文将从 OpenGL 的角度结合 Apple 官方给出的部分资料,介绍 iOS Rendering Process 的概念及其整个底层渲染管道的各个流程. 相信在理解了 iOS Rendering ...
- 关于c++ list容器的操作摸索
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/chaoweilanmao/article/details/30793859 #include< ...
- python中的类(二)
python中的类(二) 六.类的成员 字段:普通字段,静态字段 eg: class Province(): country=’中国’ #静态字段,保存在类中,执行时可以通过类或对象访问 def __ ...
- Java50道经典习题-程序34 三个数排序
题目:输入3个数a,b,c,按大小顺序输出. import java.util.Scanner; public class Prog34 { public static void main(Strin ...
- 优化Eclipse基本配置
eclipse有很多默认配置会造成其本身运行缓慢,特别是加载大型工程的时候,以下列举的几种方法可以优化eclipse的运行速度,加快工程的加载和构建. 关闭XML Validation 1. 关闭当前 ...
- Gradle Goodness: Parse Files with SimpleTemplateEngine in Copy Task
With the copy task of Gradle we can copy files that are parsed by Groovy's SimpleTemplateEngine. Thi ...